15. 开放问题:小模型的人工推理之路
官方 PPT 来源:Lecture 19 官方 PPT:Open Questions / The Art of Artificial Reasoning for (Small) Language Models
本讲只整理 Stanford CS224n Winter 2026 官方 PPT 中的课堂内容。它不是一节“随便展望未来”的课,而是把前面几讲的 reasoning、RL、后训练、评测和数据问题收束到一个更大的问题:当 brute-force scaling 越来越难继续时,NLP/LLM 还能靠什么继续提升?
第 15 讲的关键词是 small language models、smart scaling、prolonged RL、synthetic reasoning data、RLP、front-loading reasoning 和 open collaboration。这节课的价值在于,它把“未来模型怎么变强”从一句空话拆成了可以研究、可以实验、可以训练的几个技术方向。
学习目标
学完本讲,你应该能做到:
- 解释为什么 PPT 说 current scaling laws 依赖少数机构才负担得起的 extreme-scale compute。
- 区分 brute-force scaling 和 smart scaling。
- 说明 data saturation 之后的三条路线:有限数据学得更好、合成新数据、超越数据本身进行推理。
- 理解 2025 年 LRMs 相对 LLMs 的核心变化:long thought、RL、从 imitation learning 转向 exploration learning。
- 解释为什么 RLVR 后 Pass@1 可以变好,而 Pass@K 可能变差。
- 说明 effortless RL 和 effortful RL 的结论不能直接混同。
- 读懂 ProRL 中 GRPO/DAPO 的基本目标、dynamic sampling、decoupled clipping 和 entropy control。
- 解释为什么 prolonged RL 需要在 exploration 和 exploitation 之间维持可持续熵。
- 理解 Prismatic Synthesis 如何用 gradient representation 和 G-Vendi Score 做合成数据多样性筛选。
- 说明 RLP 为什么把 chain-of-thought 当作 pretraining 阶段的 exploratory action。
- 写出 RLP 的信息增益式 reward,并理解它为什么是 verifier-free 和 dense reward。
- 概括 front-loading reasoning 的结论:pretraining 阶段加入 reasoning data 的收益可以在后训练后保留。
- 解释 OpenThoughts3 在 PPT 中代表的 open collaboration 和 super effortful SFT 路线。
- 说清楚最后的开放问题:智能理论、知识与推理理论、超长上下文是否真是纯优势。
1. 这一讲在 CS224n 主线中的位置
对应 slides 1-2。
前面几讲已经讲过现代 NLP 的核心技术:
- Transformer 和预训练让语言模型拥有强大的表示与生成能力。
- 后训练、RLHF/RLVR、GRPO、DPO 等方法让模型更符合任务或人类偏好。
- reasoning 讲了 chain-of-thought、test-time compute、RL 诱导推理、蒸馏、长上下文和推理时扩展。
- evaluation 讲了为什么 benchmark 会驱动模型进步,也会诱导模型过拟合评测。
第 15 讲的问题是:如果这些路线都继续往前走,下一步的科学问题在哪里?
PPT 的标题是 The Art of Artificial Reasoning for Small Language Models。这里的“小模型”不是说模型能力一定弱,而是指研究目标不再只靠把参数、数据和算力堆到最大。课程试图回答的是:如果不是所有人都能训练超大模型,怎样用更聪明的数据、算法和协作,让较小模型也获得强 reasoning 能力?

这一讲的第一句主张很明确:民主化生成式 AI 需要突破当前 scaling laws 的限制。原因是当前 scaling laws 往往要求 extreme-scale compute,而这种算力只有少数机构负担得起。

所以这讲的核心不是“还要不要 scaling”,而是“scaling 什么”。以前主要 scaling parameters、tokens、compute;现在要更认真地 scaling intelligence,也就是让模型在数据有限、算力有限、开放协作的情况下,仍然能学会更强推理。
2. David vs. Goliath:小模型为什么仍然值得研究
对应 slides 3-6。
PPT 用 David vs. Goliath 比喻当前大模型研究格局。Goliath 代表有巨大算力、闭源模型和大规模训练资源的机构;David 代表开源社区、研究团队、小模型和资源较少的参与者。
如果只看 brute-force scaling,David 很难赢。因为 brute-force scaling 的逻辑是:
这条路当然有效,但它把门槛推得很高。PPT 的转向是:David 不能靠同一种资源竞争,而要靠不同的创新维度。

PPT 给出三类创新:
- Unconventional data:不是只从互联网抓更多普通文本,而是设计、合成、筛选更有推理价值的数据。
- Unconventional algorithms:不是只复用标准 next-token prediction 或短程后训练,而是改训练目标、RL 过程、数据表示和推理算法。
- Unconventional collaboration:通过 open science、open source、跨机构和跨地域协作,把单个团队无法完成的数据与算法积累变成共同基础。
这三类创新贯穿整节课。后面的 ProRL 属于算法创新,Prismatic Synthesis 和 RLP/FLR 同时涉及数据与算法创新,OpenThoughts 则强调协作创新。
3. 从 brute-force scaling 到 smart scaling
对应 slides 7-11。
PPT 引用 test-time award talk 的观点:brute-force scaling 的时代结束,smart scaling 的时代开始。这里不要误解为 scaling 不重要了。更准确地说,scaling 的对象正在变化。

PPT 把 data saturation 后的路线分成三类。
第一类是 learn better and faster with limited data。同样的数据量,模型能不能学得更快、更稳、更有泛化?这对应 alternative architectures 和 alternative training recipes。也就是:不要只问数据够不够多,还要问训练目标和优化过程是不是浪费了数据。
第二类是 synthesize new data。当互联网上高质量文本有限时,可以通过算法生成 internet data 之外的“外太空数据”。这里的“外太空”不是玄学,而是指不再被现有互联网分布限制:可以生成更难、更稀有、更系统化、更覆盖 OOD 情况的训练样本。
第三类是 reason beyond what is in the data。如果模型只能复述训练分布,那遇到真正新问题会卡住。推理能力的意义是:从已有知识中组合、搜索、验证、修正,得到训练数据中没有直接出现的结论。这对应 test-time reasoning algorithms 和 test-time training algorithms。
PPT 的结论是:brute-force scaling 放缓,不代表 intelligence scaling 停止。只是下一阶段需要更聪明地利用数据、合成数据和推理过程。

本讲后面的三个主技术块正好对应这条线:
- ProRL:让小模型通过更持久、更精细的 RL 扩展 reasoning 边界。
- Prismatic Synthesis:让合成 reasoning 数据更有多样性,而不是塌缩到单一模式。
- RL as Pretraining / RLP:把 reasoning 提前放进 pretraining,而不是只在后训练阶段补。
4. LRMs:从语言模型到推理模型
对应 slides 13-15。
PPT 把 2025 年称作 LRMs 兴起的阶段。LRM 可以理解为 reasoning model,也就是相对于传统 LLM,更强调长思考链和推理能力的模型。
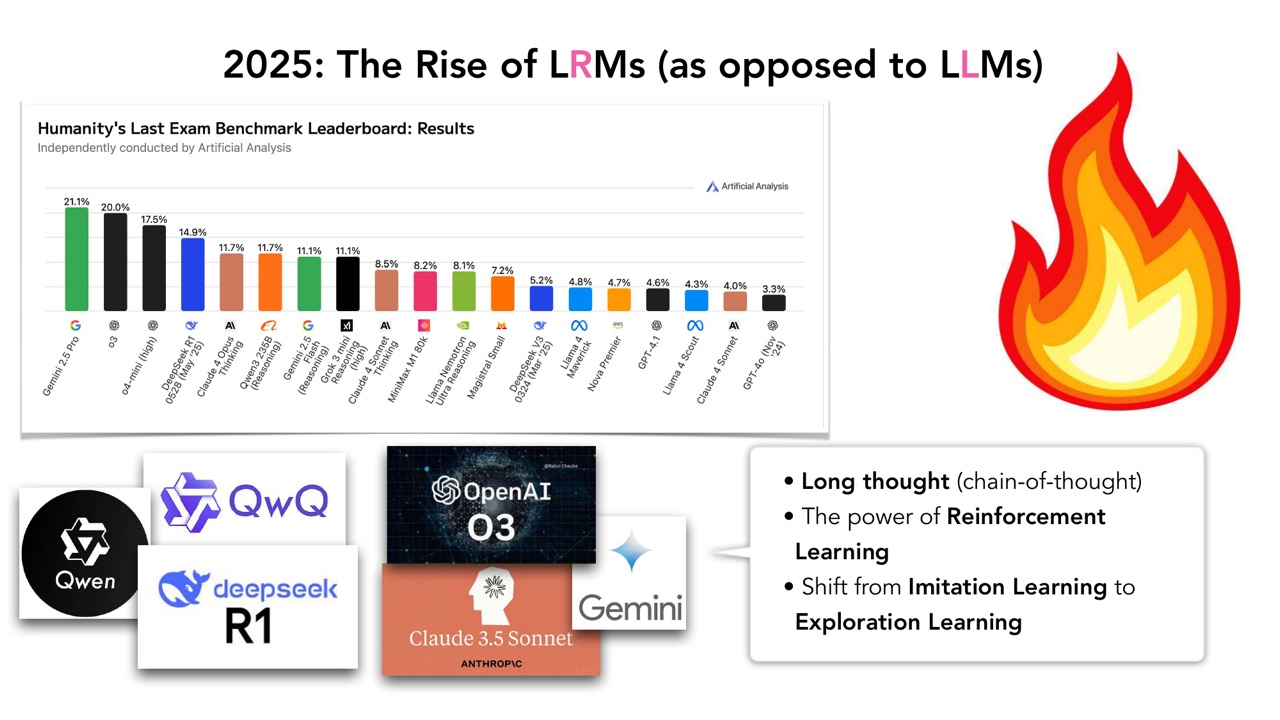
PPT 给出三个变化:
- Long thought,也就是更长 chain-of-thought 或 reasoning trace。
- Reinforcement Learning 的力量变得更突出。
- 从 imitation learning 转向 exploration learning。
这三个点要放在一起理解。
Imitation learning 的典型形式是 SFT:给模型高质量示范,让模型模仿。它的优势是稳定、直接、可控;缺点是模型主要学会复现数据中已有的推理形式。Exploration learning 的典型形式是 RL:模型尝试多种解法,通过 reward 信号发现哪些路径有效。它的优势是可能发现训练数据中没有直接演示的策略;缺点是训练更不稳定,也更依赖 reward、采样和优化细节。
LRMs 的核心变化就是:模型不只要“像人类写答案”,还要能在推理空间中探索。
5. Pass@1 变好,Pass@K 变差:为什么这是重要警告
对应 slides 16-21。
PPT 先展示一个看似反直觉的现象:RLVR 后,Pass@1 变好,但 Pass@K 变差。

先解释两个指标:
- Pass@1:只生成一个答案,这个答案是否正确。
- Pass@K:生成 \(K\) 个答案,只要其中有一个正确就算通过。
如果一个模型的 Pass@1 上升,说明它最常给出的答案更可能正确。可是 Pass@K 下降说明:当你允许它尝试多次时,它反而不如 base LLM 容易在多个尝试里覆盖到正确路径。
这背后的直觉是:RL 可能提高单次输出的确定性,也可能压缩输出分布的多样性。模型变得更偏向某些被 reward 奖励过的路径,短期看 Pass@1 好了,但探索空间变窄,多个样本之间差异变小,Pass@K 反而下降。
PPT 的关键结论不是“RL 不行”,而是:
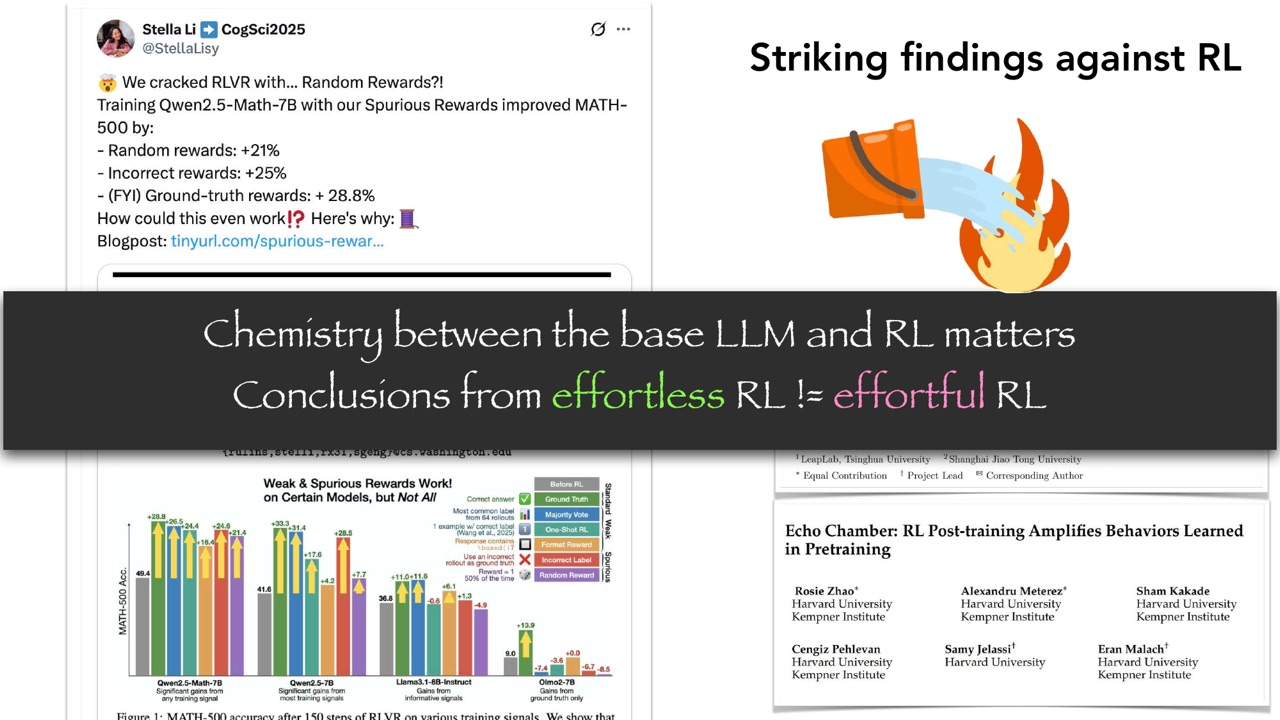
Base LLM 和 RL 之间的 chemistry 很重要。Effortless RL 的结论不能直接推广到 effortful RL。
这里的 effortless RL 可以理解为短、弱、低投入、没有细致调参或没有持续探索控制的 RL。Effortful RL 则是投入更长训练、更认真采样、更精细控制 entropy 和 KL、更系统覆盖任务的 RL。PPT 后面用 ProRL 说明:如果 RL 做得足够“努力”,结论可能不同。
6. ProRL:小模型也可以靠持久 RL 扩展推理边界
对应 slides 22-24。
PPT 用一句话引出 ProRL:Rome was not built in a day。换成机器学习语言就是:不要只追求在大模型上短跑式 RL;也可以让一个 1.5B 小模型做耐力训练。
ProRL 的论文题目是 Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models。PPT 的重点不是把论文所有细节讲完,而是强调 prolonged RL 的训练哲学:
- 模型很小,只有 1.5B。
- RL 不是短跑,而是长时间维持学习信号。
- 训练过程需要持续保持探索能力,而不是很快 entropy collapse。
ProRL 建立在 DAPO 之上。DAPO 是 GRPO 的一个变体,强调 dynamic sampling 和 decoupled clipping。

PPT 中的 GRPO 目标可以写成:
这里可以先按直觉读:
- \(\tau\):模型生成的一条轨迹,可以理解为一次完整回答或推理过程。
- \(\pi_\theta\):当前策略,也就是当前语言模型的生成分布。
- \(r_\theta(\tau)\):importance ratio,用来衡量当前策略相对旧策略对这条轨迹的概率变化。
- \(A(\tau)\):advantage,表示这条轨迹比同组其他轨迹更好还是更差。
- \(\mathrm{clip}\):限制更新幅度,避免策略一步走太远。
GRPO 的思想和 PPO 类似:如果一条轨迹 advantage 为正,模型应该提高它的概率;如果 advantage 为负,模型应该降低它的概率。但更新不能太激进,否则策略会崩。
DAPO 在这里加入两个实践机制。
第一是 Dynamic Sampling。它会偏向选择中等难度样本。太简单的题模型都能答对,reward 没有区分度;太难的题模型都答错,也没有学习信号。中等难度题能让同组回答出现差异,advantage 才有用。
第二是 Decoupled Clipping。标准 clipping 用同一个 \(\epsilon\) 控制上下界,而 DAPO 把上下界拆开:
\(\epsilon_{\mathrm{high}}\) 控制正向提升的上界,\(\epsilon_{\mathrm{low}}\) 控制负向压制的下界。PPT 特别强调 clip-higher:提高上界可以让低概率但可能有用的 token 更容易被提升,从而鼓励 broader exploration。
7. ProRL 的核心:维持 sustainable entropy
对应 slides 25-28。
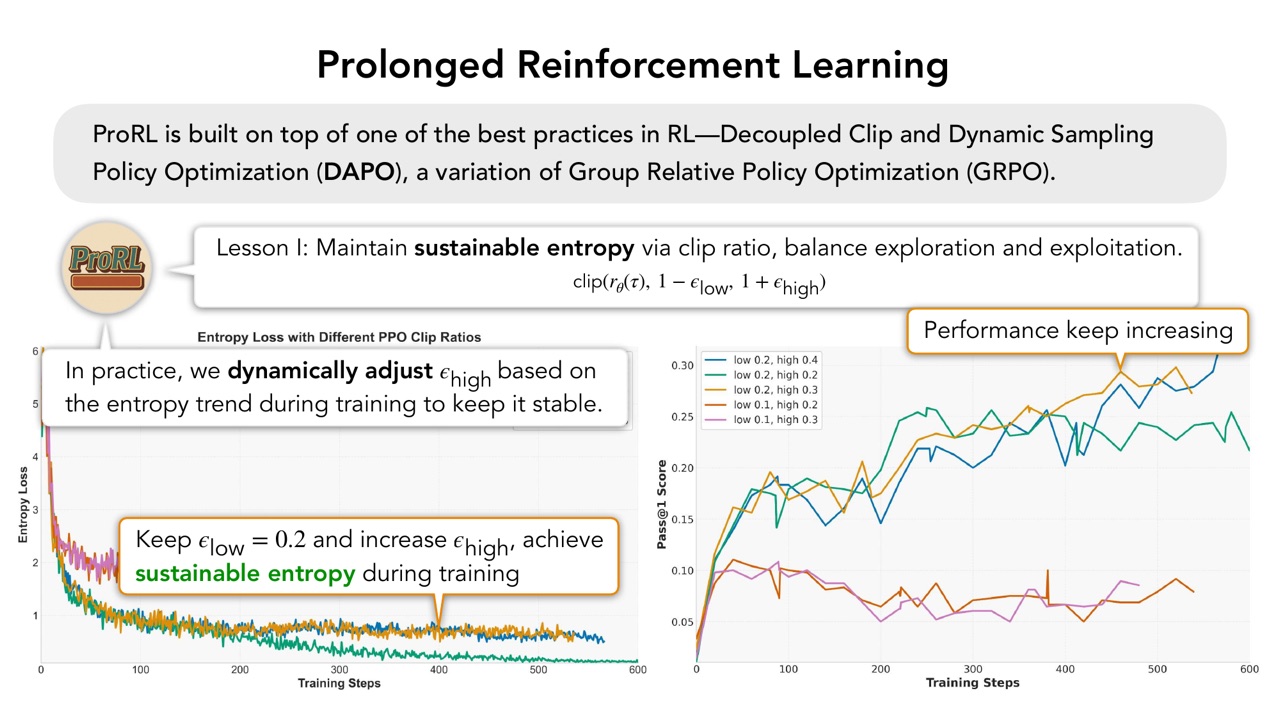
ProRL 的第一课是:通过 clip ratio 维持 sustainable entropy,平衡 exploration 和 exploitation。
Entropy 可以理解为模型输出分布的“分散程度”:
- Entropy 高:模型还在考虑多种 token、多种解法、多种路径,探索空间更宽。
- Entropy 低:模型高度确定,输出集中在少数路径上,探索空间变窄。
RL 训练里 entropy 既不能太快塌缩,也不能无限保持很高。如果 entropy 太快塌缩,模型会过早锁死某些策略,后续训练没有探索;如果 entropy 太高,模型又不能稳定利用已经学到的好策略。
PPT 展示了三种情况。
第一种是默认 \(\epsilon_{\mathrm{low}}=\epsilon_{\mathrm{high}}=0.2\)。性能一开始提升,但 entropy collapse 后平台期很快出现,原因可能是探索不足。
第二种是降低 \(\epsilon_{\mathrm{low}}\)、提高 \(\epsilon_{\mathrm{high}}\)。这样确实能让 entropy 更可持续,但如果对负 advantage 的动作压制不够,exploitation 又不足,性能改善不明显。
第三种是实践中动态调整 \(\epsilon_{\mathrm{high}}\)。也就是根据训练过程中的 entropy trend 调整上界,让模型持续保持探索,同时保留足够利用能力。
ProRL 的第三课是:为了让一个 hero run 活下去,需要动态调整超参数。
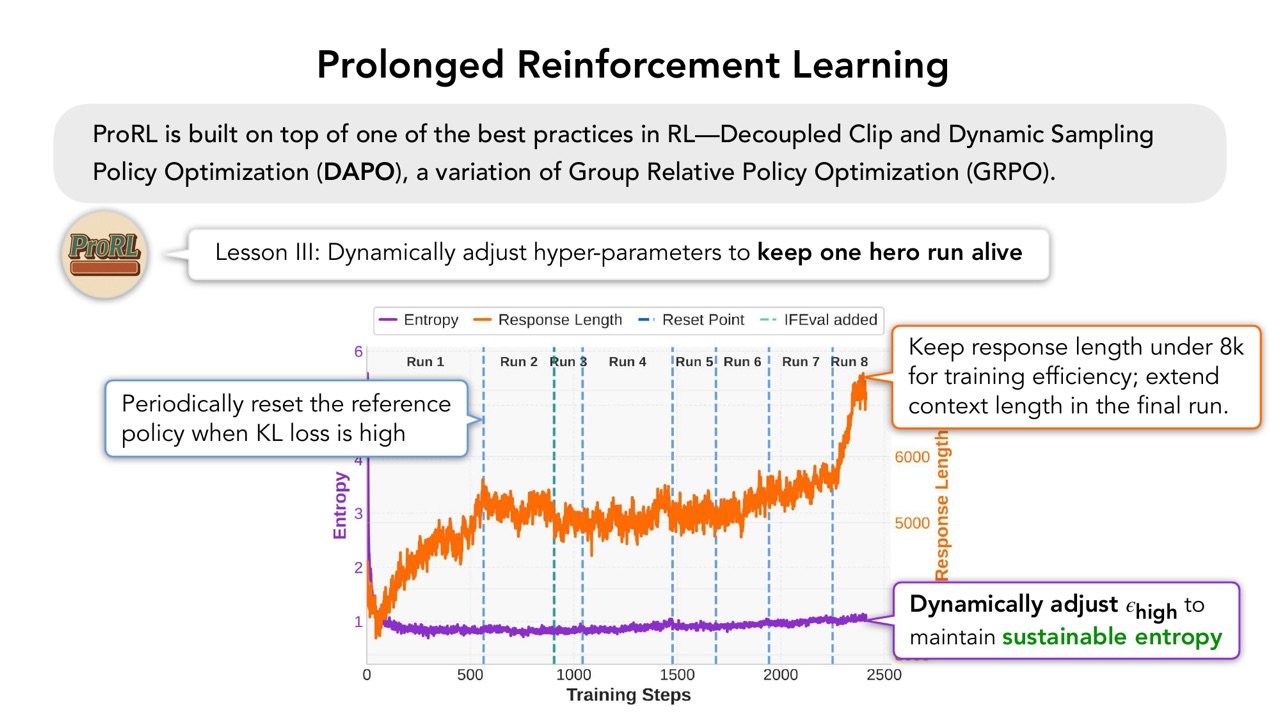
PPT 给出三个操作:
- KL loss 高时,周期性 reset reference policy。
- 为了训练效率,训练时把 response length 控制在 8k 以内,最后一轮再扩展 context length。
- 动态调整 \(\epsilon_{\mathrm{high}}\),维持 sustainable entropy。
这说明 prolonged RL 的难点不是“写出一个 loss 就完了”。真正难的是让训练过程持续处在有学习信号、有探索、有稳定性的区域。
8. ProRL 的结果:1.5B 小模型能走多远
对应 slides 29-32。
PPT 总结 ProRL 在 math、code、STEM、reasoning gym、instruction following 等多类任务上评估。结果相对 base model 和 Distill-R1-1.5B 都有显著提升,尤其在 OOD tasks 和 reasoning gym 上提升更明显。
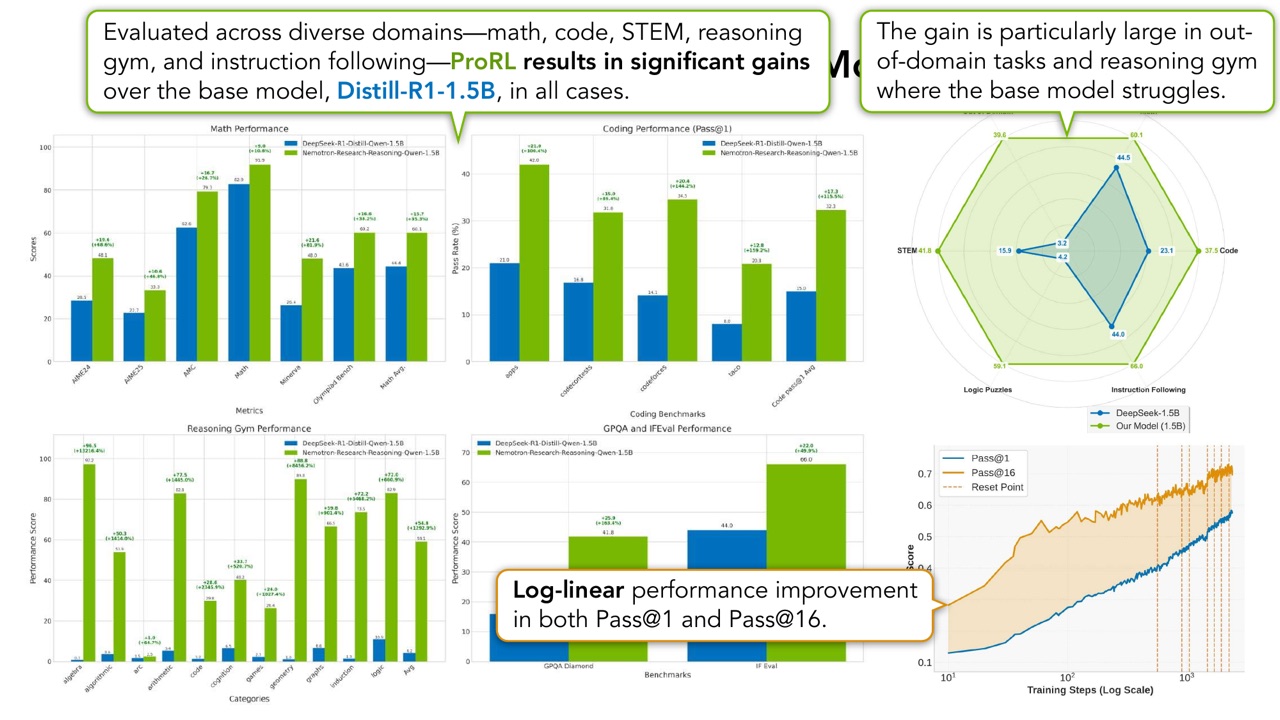
PPT 还强调了 Pass@1 和 Pass@16 的 log-linear performance improvement。这里的重点是:prolonged RL 不只是让单次输出变好,也没有像前面警告那样牺牲多样采样下的收益。至少在这套训练配方中,Pass@1 和 Pass@16 都能随训练推进改善。
PPT 进一步说,Nemotron-Reasoning-1.5B 可以达到与 4.5 倍更大的 DeepSeek-R1-7B 相当或更好的性能。
这就是本讲小模型主题的第一个强例子:更小的模型如果配上 effortful prolonged RL,并不一定只能在大模型阴影下做蒸馏模仿。它可以通过训练算法本身获得更强 reasoning。

ProRL 段落的结论是:
- Effortless RL 的结论不等于 effortful RL 的结论。
- 对 1.5B 模型做足够持久的 RL,可以走得很远。
- 动态控制 entropy 是关键。
- 仍然开放的问题是:effortful RL 能否在更弱、更早期的模型上也成功,例如 GPT-2 级别模型。
9. Effortless SFT 也不等于 effortful SFT
对应 slides 35-36。
PPT 接着把同样的逻辑推广到 SFT。
如果 effortless RL 的结论不能代表 effortful RL,那么 effortless SFT 的结论也不能代表 effortful SFT。这个提醒很重要,因为在 reasoning model 讨论中,很多人容易把 RL 和 SFT 简化成二选一:
PPT 没有这样简单下结论。它提出一个具体问题:为什么 Qwen 和 RL 的 chemistry 很好?一种可能是 Qwen 在 pretraining 中已经经过 SFT 或 SFT-style mid-training,使它更适合后续 RL。

这给出一个很重要的课程观点:模型最终表现不是某个单独阶段决定的,而是 pretraining、mid-training、SFT、RL 之间的相互作用。一个模型在 RL 阶段看起来“突然会推理”,可能是因为早期训练阶段已经埋下了 reasoning 格式、数据分布或能力基础。
10. Prismatic Synthesis:为什么合成数据需要多样性
对应 slides 38-41。
第二个主技术块是 Prismatic Synthesis。PPT 的题目是 Gradient-based Data Diversification Boosts Generalization in LLM Reasoning。

PPT 先回到 smart scaling 的第二条路线:synthesize new data。

合成数据已经广泛用于 mid-training 和 post-training,有些情况下甚至覆盖 LLM 训练的全部数据流程。常见做法是依赖 largest 或 strongest teacher models,让强模型生成训练数据给较小模型。
但 obvious concern 是 mode collapse。

Mode collapse 在这里可以理解为:生成的数据表面很多,但分布越来越集中,思路越来越单一。对于 reasoning 数据,这尤其危险。因为 reasoning model 需要面对多种题型、多种解法、多种隐含结构。如果合成数据只覆盖少数模式,模型可能在熟悉模式上变强,却在 OOD 推理上变弱。
因此,Prismatic Synthesis 的核心不是“生成更多数据”,而是“知道生成的数据覆盖了多少不同推理方向”。
11. Gradient as Data Representation:用梯度表示一个样本
对应 slides 43-44。
Prismatic Synthesis 的关键思想是:用 gradient 来表示一个 data point。
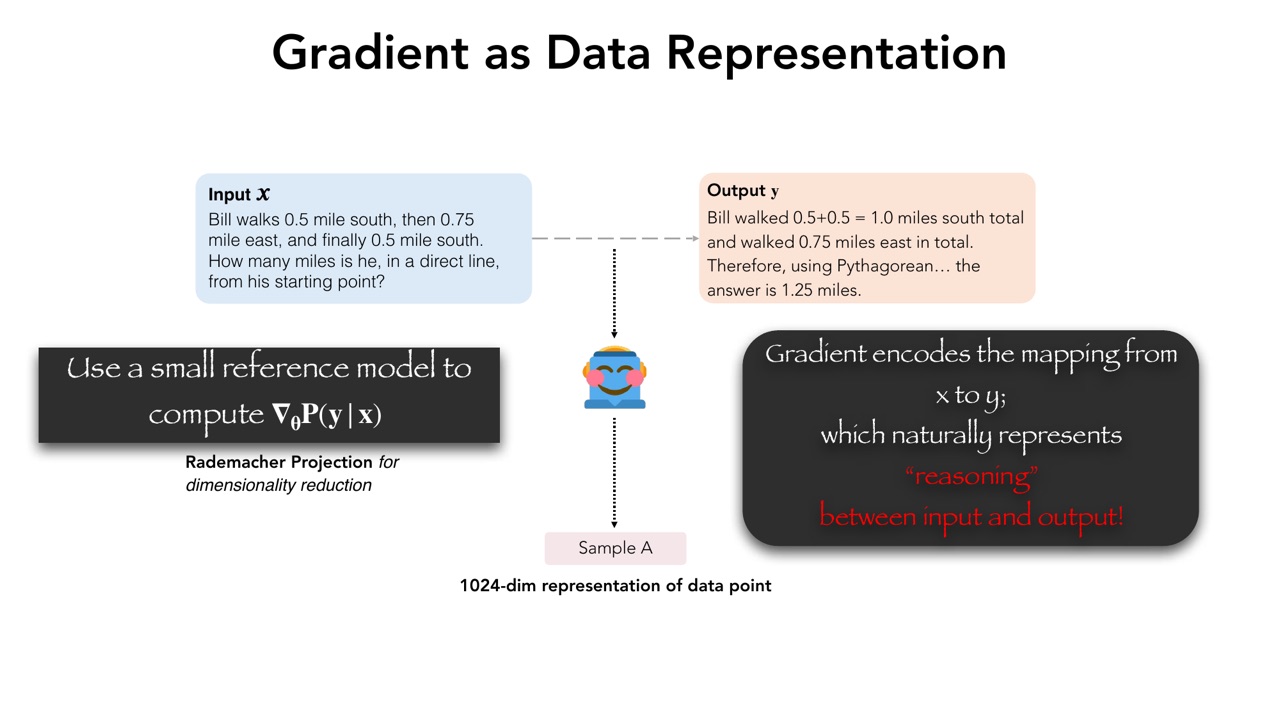
设一个 reasoning 样本由输入 \(x\) 和输出 \(y\) 组成。普通 embedding 往往只表示文本本身,而 Prismatic 的直觉是:reasoning 样本真正重要的是从 \(x\) 到 \(y\) 的映射。因此可以用一个小 reference model 计算梯度:
这个梯度表示:为了让模型更倾向于从 \(x\) 生成 \(y\),参数应该朝哪个方向变化。换句话说,它不只是表示输入或输出,而是表示这个样本对模型行为的训练作用。
PPT 说,gradient encodes the mapping from \(x\) to \(y\),因此自然表示 input 和 output 之间的 reasoning。随后使用 Rademacher Projection 做降维,得到 1024 维 data point representation。
这一点对初学者很重要:这里的数据多样性不是用题目文字是否不同来衡量,而是用“这些样本会不会推动模型学到不同的东西”来衡量。两个题目表面不同,但如果梯度方向类似,训练作用可能很重叠;两个题目表面相似,但如果解法结构不同,梯度可能更分散。
12. G-Vendi Score:衡量合成数据的推理多样性
对应 slide 44。
Prismatic Synthesis 用 G-Vendi Score 衡量数据集在 gradient representation 空间中的多样性。PPT 明确说 G-Vendi Score 可以预测 generalization,尤其是 out-of-distribution generalization。
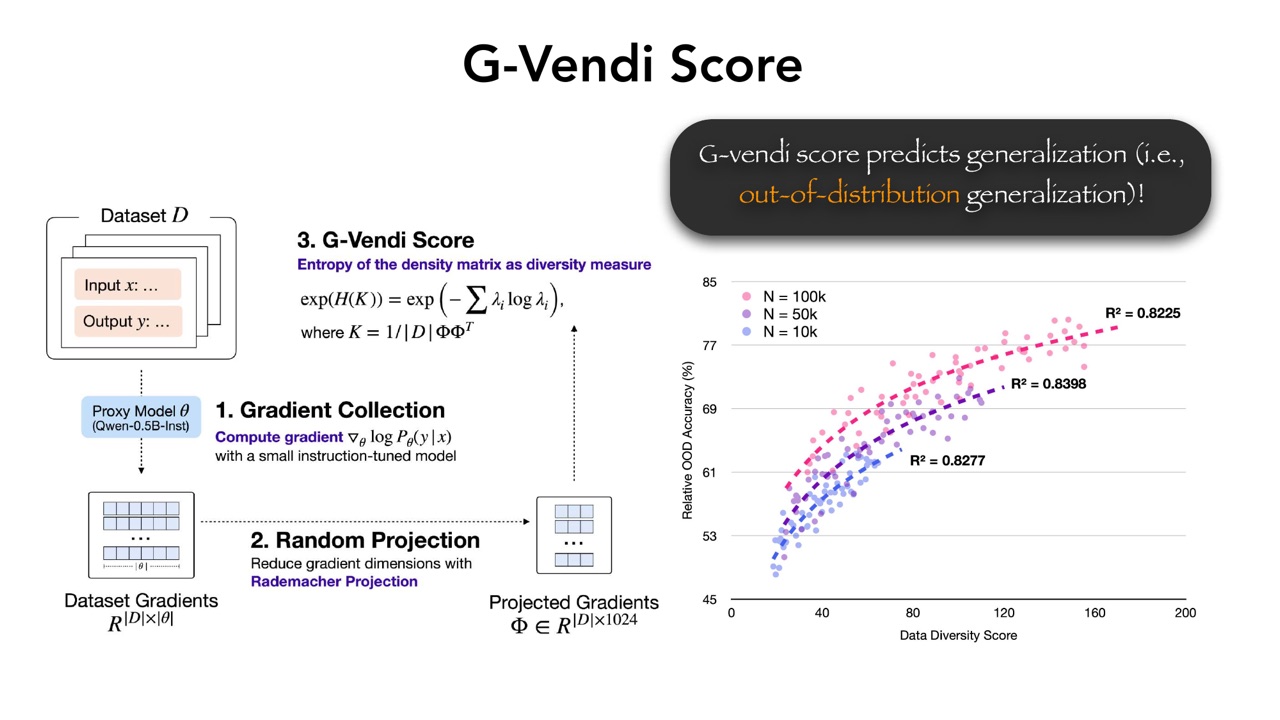
可以把数据集表示成矩阵 \(\Phi\),每一行或每个向量对应一个样本的 gradient representation。构造相似度矩阵:
设 \(K\) 的特征值为 \(\lambda_i\),G-Vendi Score 可以写成:
这个公式的直觉是:如果数据集中许多样本都很相似,那么相似度矩阵的有效维度较低,熵也较低;如果样本覆盖多个不同方向,特征值分布更分散,熵更高,G-Vendi Score 也更高。
学习时不要只把它当成一个公式。它要解决的问题是:
G-Vendi Score 试图给这个问题一个可计算的答案。
13. Prismatic Synthesis 的 pipeline
对应 slides 45-48。
PPT 展示的 Prismatic Synthesis pipeline 是:
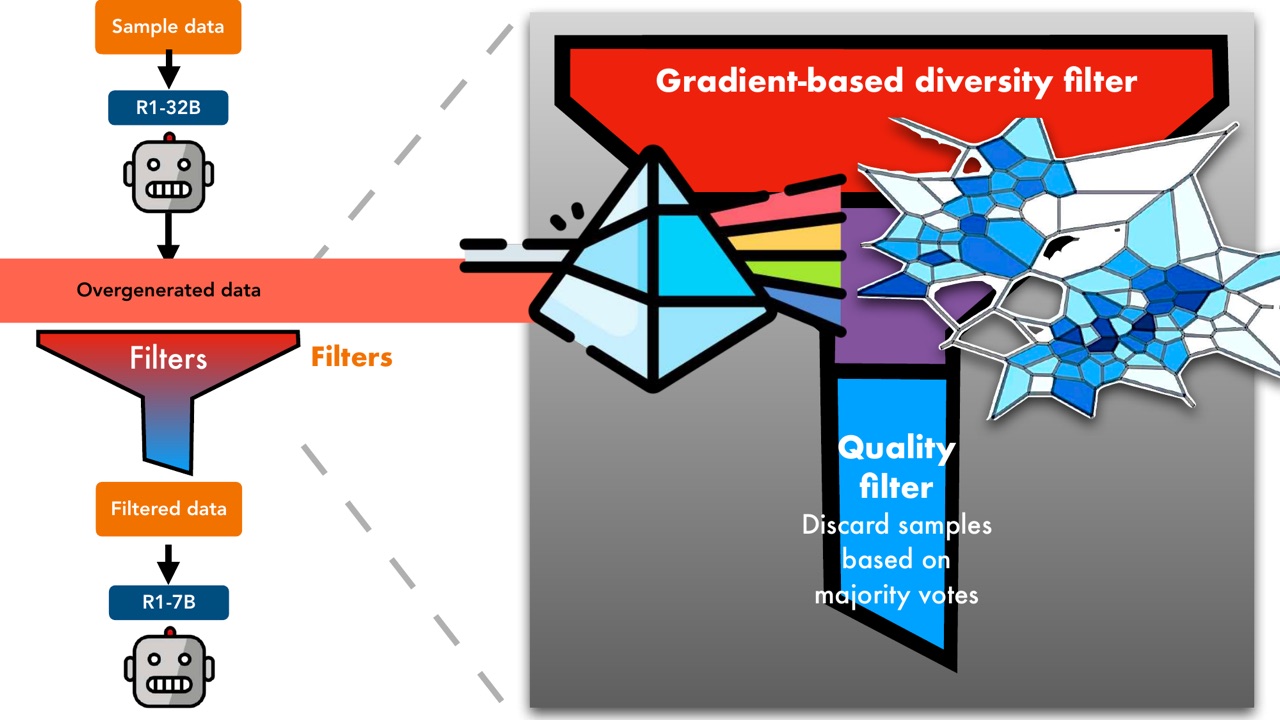
流程可以分成五步:
- 从 sample data 开始。
- 使用 R1-32B 生成 overgenerated data。
- 通过 filters 筛选。
- 得到 filtered data。
- 用 filtered data 训练 R1-7B。
关键在 filters。PPT 展示了两类 filter:
- Gradient-based diversity filter:根据前面的 gradient representation 和多样性指标筛选,避免数据集中出现太多训练作用重复的样本。
- Quality filter:基于 majority votes 丢弃部分样本,控制生成数据质量。
这就是 Prismatic 这个名字的含义:像棱镜一样把合成数据的“光束”拆开,检查里面是否真的包含多种方向,而不是看起来丰富、实际单调。
14. Prismatic 的结果:更小 teacher 也能生成有用 reasoning 数据
对应 slides 48-49。
PPT 展示 Prismatic Synthesis 改善 long-CoT reasoning。
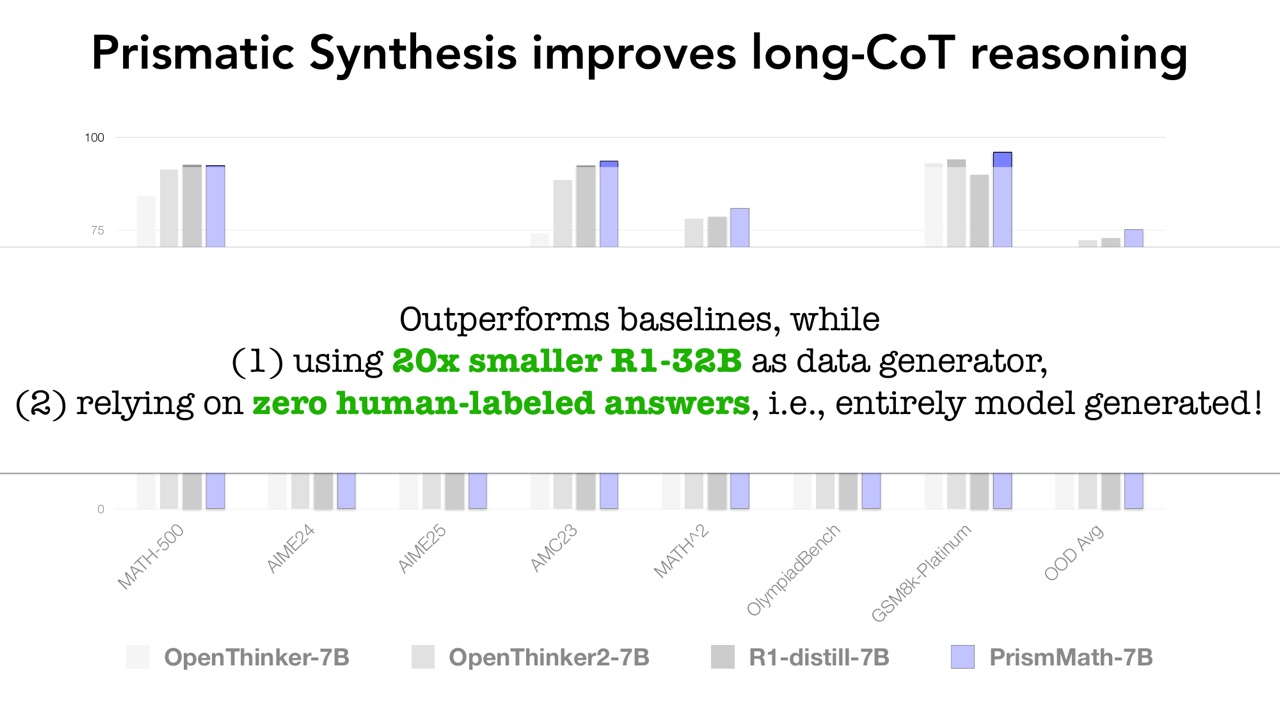
结果的重点有两点:
- 它 outperform baselines。
- 它使用 20 倍更小的 R1-32B 作为 data generator,并且依赖 zero human-labeled answers,也就是数据完全由模型生成。
这和 David vs. Goliath 的主题呼应:不一定只有最大 teacher model 才能产出有价值数据。只要合成、筛选和多样性控制做得足够系统,较小的生成器也可以构造出强训练数据。
PPT 对 Prismatic 的总结是:

- Reasoning requires data that transcends internet data。
- Synthetic data 可以救场。
- RL 也可以看成一种 implicit synthetic data generation,因为模型通过 exploration 生成新轨迹。
- 不管是否使用 RL,现有方法常缺少对 overall diversity 的 bird-eye view。
- 系统性多样化加质量检查,可以弥补 teacher model 大小差距。
这里可以把 Prismatic 放回 CS224n 的总主线:预训练数据决定模型吸收什么世界知识,后训练数据决定模型如何回答,而 reasoning 数据的多样性决定模型能不能跳出单一解法模板。
15. RLP:把推理提前放进 pretraining
对应 slides 51-53。
第三个主技术块是 RLP:Reinforcement as a Pretraining Objective。

PPT 先指出一个大背景:ever more pretraining 的时代正在结束。

原因有三点:
- Scaling compute 不再是唯一瓶颈。
- High-quality data 是有限的,并且越来越被消耗。
- 时代从 scaling data 转向 extracting more value per token。
这和前面 smart scaling 完全一致。既然高质量 token 不再无限增长,问题就变成:同样一个 token,能不能训练出更多 reasoning 能力?
标准 LLM 训练的问题是:reasoning 往往是 afterthought。
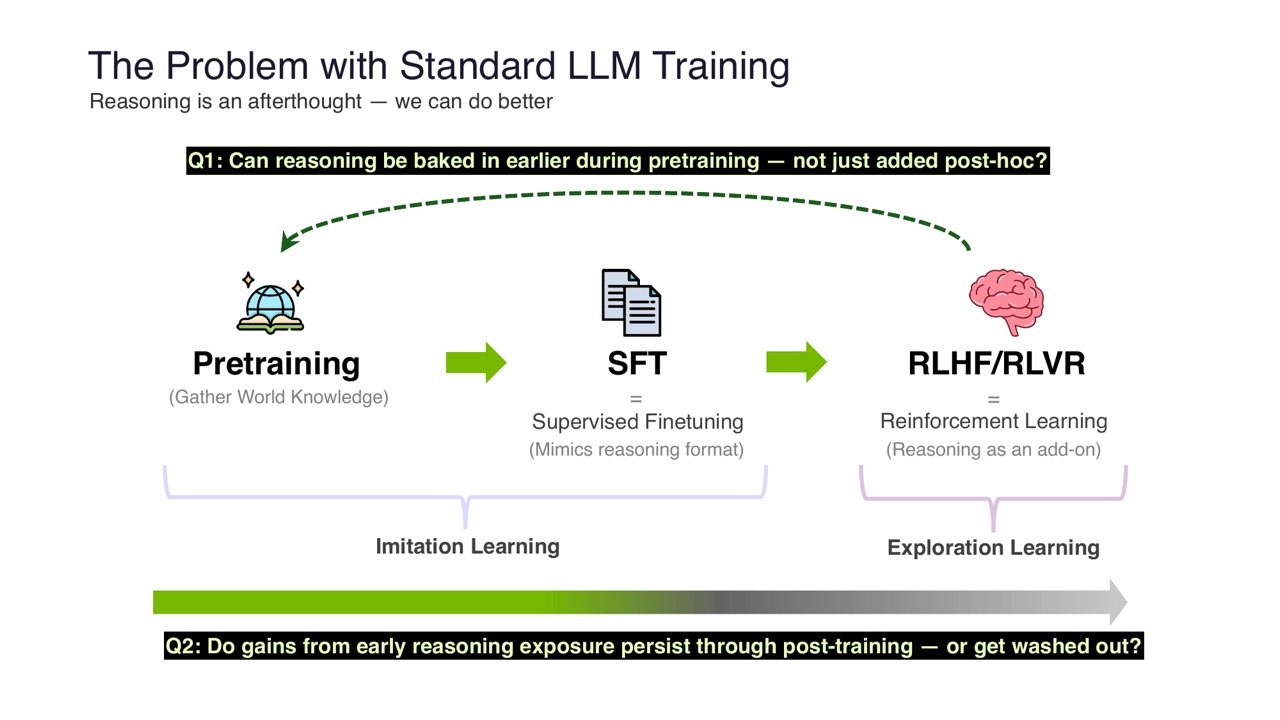
传统流程可以概括为:
在这个流程里:
- Pretraining 收集世界知识。
- SFT 模仿 reasoning format。
- RLHF/RLVR 把 reasoning 当作 add-on。
PPT 提出两个问题:
- 能不能把 reasoning 更早 bake into pretraining,而不是事后补?
- 早期 reasoning exposure 的收益在后训练后还会保留,还是会被 wash out?
RLP 就是在回答这两个问题。
16. Vanilla Pretraining vs. RLP:从 pattern completion 到 reasoned prediction
对应 slide 54。
PPT 用 photosynthesis 的例子说明 vanilla pretraining 和 RLP 的区别。
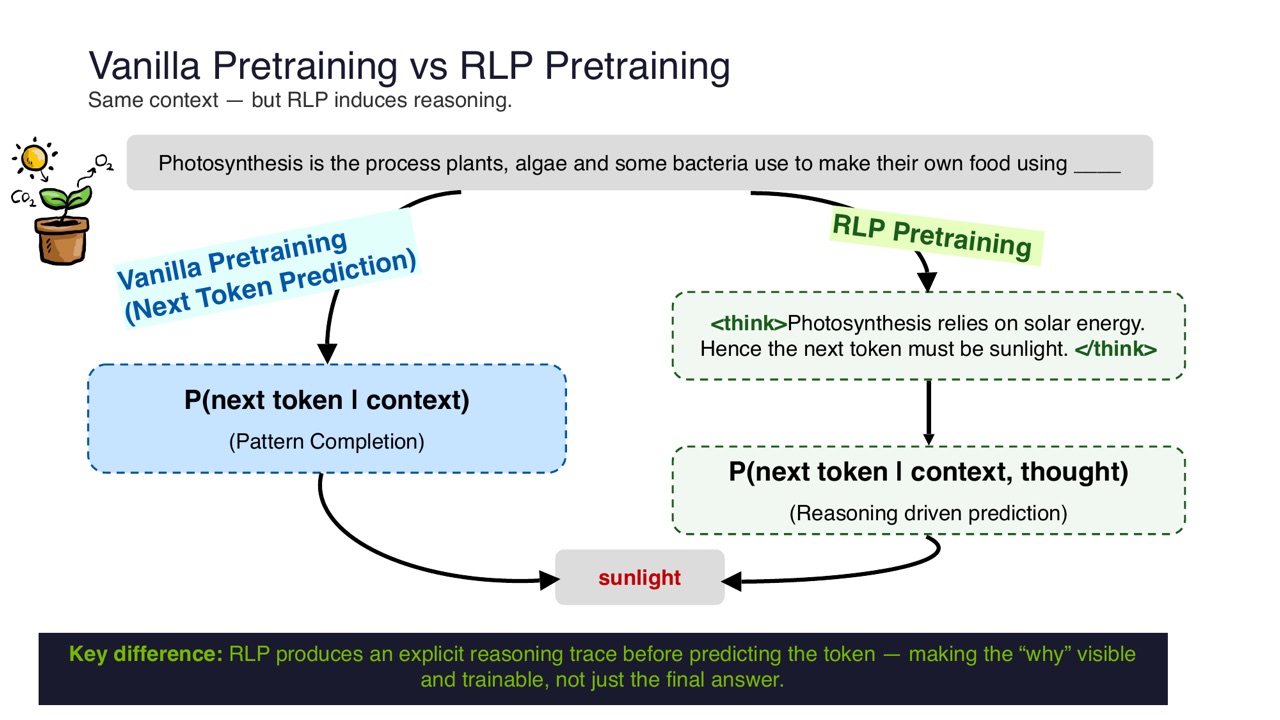
上下文是:
Vanilla pretraining 做的是 next-token prediction:
模型看到前文,根据模式补全,下一个 token 是 sunlight。这是 pattern completion。
RLP pretraining 则先产生一个显式 reasoning trace:
<think>Photosynthesis relies on solar energy.
Hence the next token must be sunlight.</think>
然后再预测:
区别在于,RLP 让模型在预测 token 前先生成“为什么”。这个 why 变成可见、可训练的中间对象,而不是只让模型内部隐式完成。
对于学习者来说,这就是 RLP 最关键的改变:它不是把 CoT 放在推理时 prompt 里,也不是只在 SFT 时模仿 CoT,而是把 CoT 作为 pretraining 阶段的行动。
17. From NTP to RLP:把 CoT 当作 action
对应 slides 55-57。
PPT 对 RLP 的一句概括是:

RLP 的工作方式是:
- 在预测下一个 token 前,先 sample 一个 thought \(c_t\)。
- 比较有 thought 和没有 thought 时,下一个 token 的 likelihood。
- 如果 thought 让下一个 token 更容易预测,就奖励这个 thought。
- 更新时只更新 thought tokens。
PPT 给出的 reward 是:
其中:
- \(x_{<t}\):当前位置之前的上下文。
- \(x_t\):要预测的下一个 token。
- \(c_t\):模型生成的 thought。
- \(p_\theta(x_t\mid x_{<t},c_t)\):有 thought 时预测正确 token 的概率。
- \(\bar{p}_\phi(x_t\mid x_{<t})\):没有 thought 的 teacher 或 baseline 预测概率。
如果 thought 让正确 token 的 log probability 更高,reward 就为正。它衡量的是 thought 带来的 information gain。
这个设计有三个特点:
- Verifier-free:不需要外部 judge 判断 thought 好不好。
- Position-wise credit:每个位置都可以产生反馈,不必等完整答案结束。
- Dense reward:普通 pretraining text 上每个 token 都能提供奖励,而不是只有数学题最后答案才有 sparse reward。
RLP 的 training recipe 里,单个网络同时作为 policy 和 reasoned predictor。PPT 还引入 EMA no-think teacher:
也就是用一个慢速跟随当前模型的无思考 teacher 作为 baseline。训练时使用 group-relative advantages 和 GRPO-style clipped per-token surrogate,但只作用在 thought tokens 上。

初学者可以先抓住核心:RLP 不需要人工标注 reasoning,也不需要外部 verifier。它用“这个 thought 是否让下一个 token 更可预测”作为自监督式强化信号,把普通文本变成 reasoning pretraining 的材料。
18. RLP 的实验问题与结果
对应 slides 58-63。
PPT 用两个问题评估 RLP。

第一个问题是:RLP 能不能在没有 task-specific tuning 的情况下提升 base model 的 reasoning 能力?这种提升是否比 Base + CPT 更好?在后续 SFT + RLVR 后,提升还会不会保留?
第二个问题是:如果把 RLP 用在一个更早的 pretraining checkpoint 上,也就是少看 200B tokens,但 FLOPs 匹配,它能否追上 fully trained base model?
PPT 的结果是肯定的。
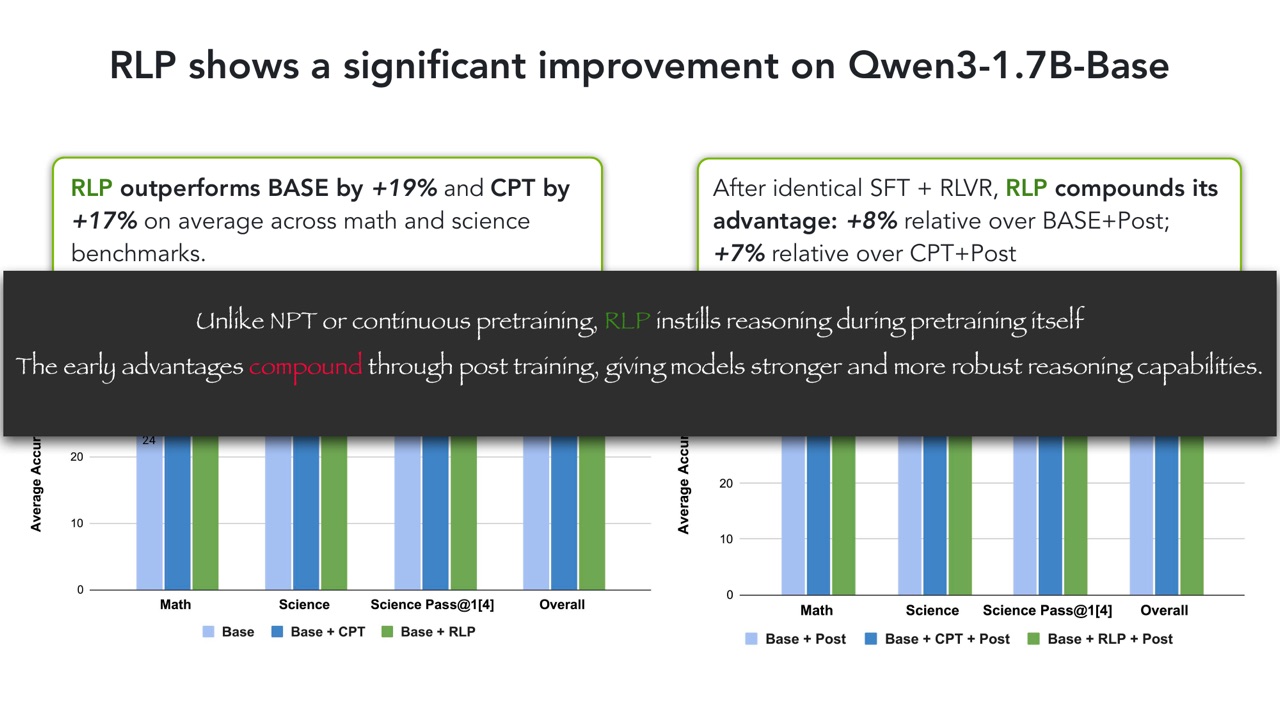
在 Qwen3-1.7B-Base 上:
- RLP 在 math 和 science benchmarks 上平均比 BASE 高 \(19\%\)。
- RLP 平均比 CPT 高 \(17\%\)。
- 经过相同 SFT + RLVR 后,RLP 仍然比 BASE + Post 高 \(8\%\),比 CPT + Post 高 \(7\%\)。
这回答了“早期 reasoning exposure 会不会被后训练洗掉”的问题:至少 PPT 展示的结果中,它没有被洗掉,而是和 post-training 形成 compounding advantage。
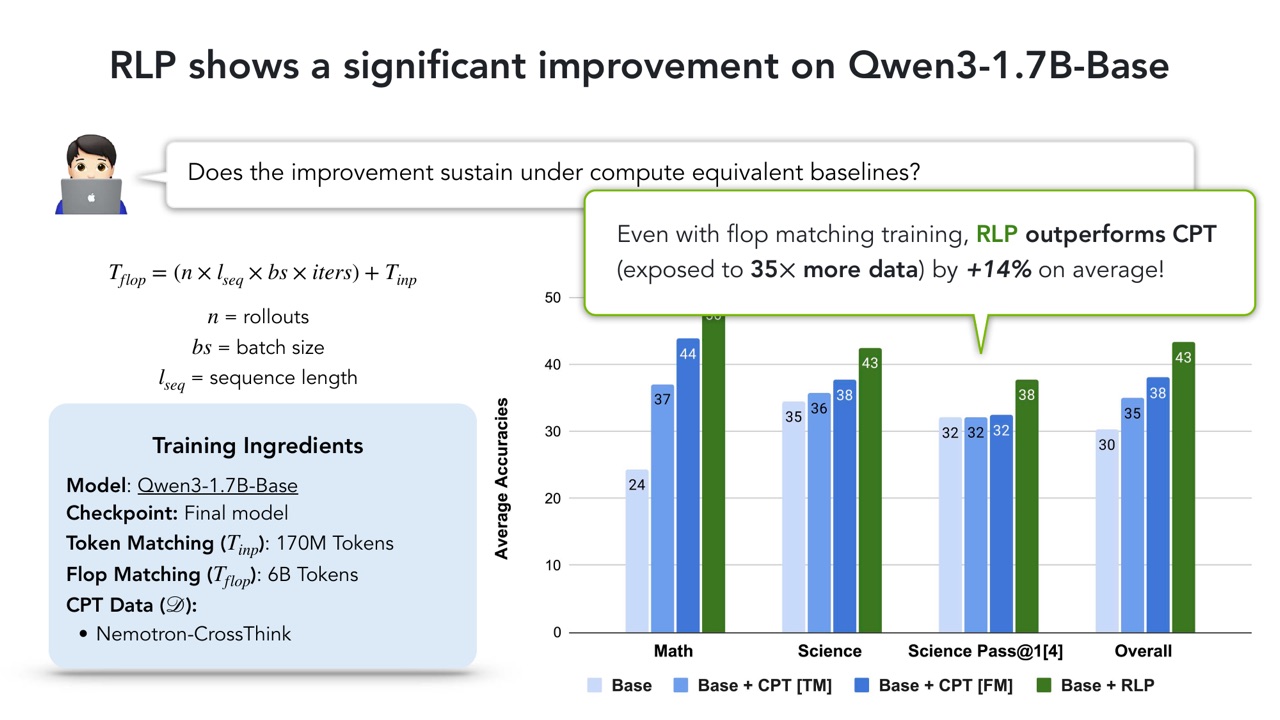
即使在 FLOP matching 的设置下,RLP 也比暴露到 \(35\times\) 更多数据的 CPT 平均高 \(14\%\)。这很关键,因为它说明 RLP 的优势不是简单来自“看了更多 token”,而是训练目标本身让每个 token 提供了更多 reasoning 学习信号。
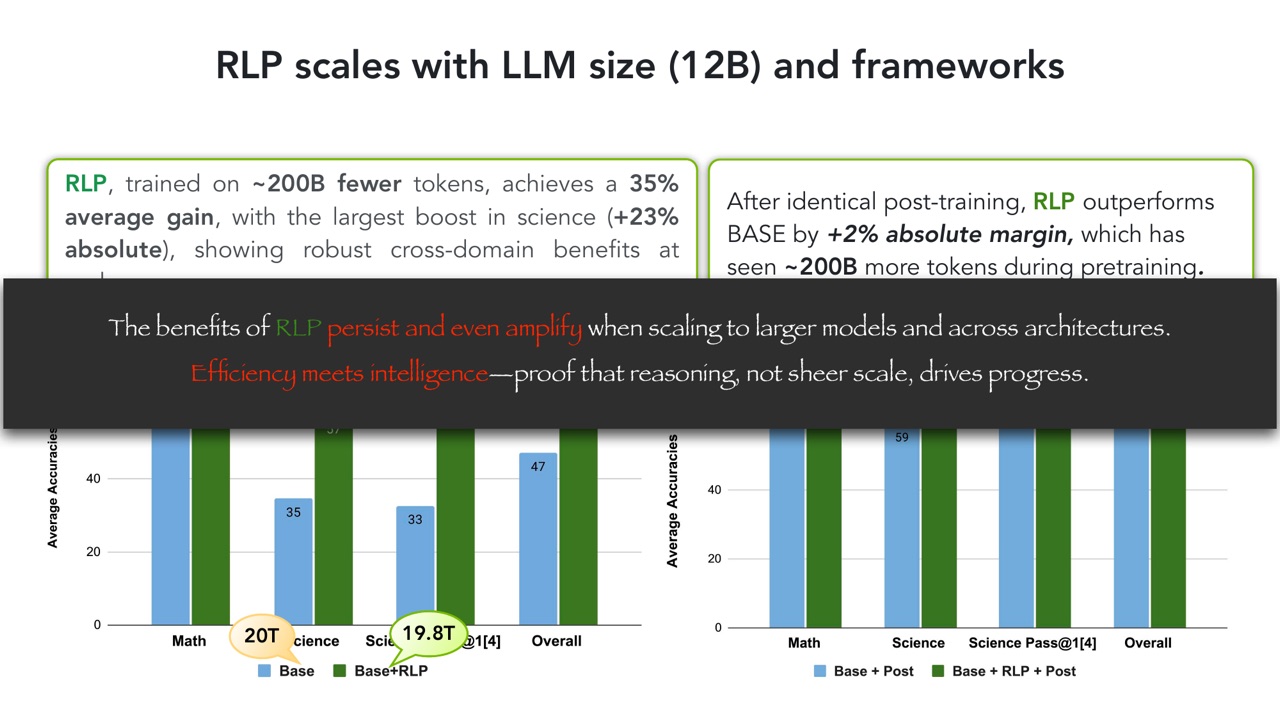
PPT 还展示 RLP 可以扩展到 12B 模型和不同框架:
- RLP 用约 200B 更少 token 训练,却有 \(35\%\) 平均增益。
- 最大提升出现在 science,绝对提升 \(23\%\)。
- 经过相同后训练后,RLP 仍比看过更多 pretraining tokens 的 BASE 高 \(2\%\) absolute margin。
PPT 把 RLP 的核心 idea 总结为:

换成一句话:如果一段 thought 能让模型更好预测接下来的真实文本,那么这段 thought 就有训练价值。
这把 next-token prediction 和 chain-of-thought reasoning 连接了起来。传统 NTP 只问“下一个 token 是什么”;RLP 问“什么 thought 能帮助我知道下一个 token 是什么”。
19. Front-Loading Reasoning:reasoning 数据应该放在哪个训练阶段
对应 slides 65-67。
RLP 之后,PPT 讲 Front-Loading Reasoning,简称 FLR。它系统地把 reasoning-style data 注入不同训练阶段:pretraining、SFT、RL,同时改变 diversity、quantity 和 quality。
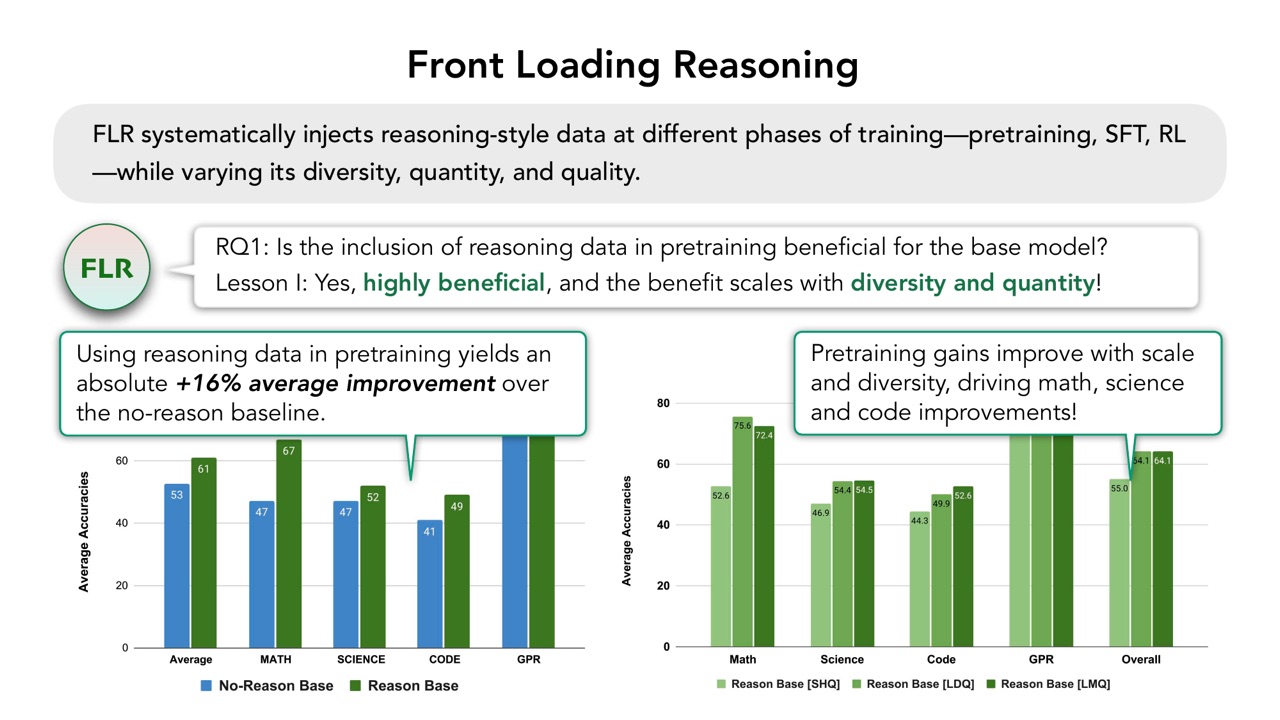
第一个研究问题是:在 pretraining 中加入 reasoning data 对 base model 是否有帮助?
PPT 的结论是:有帮助,而且收益随 diversity 和 quantity 增加。使用 reasoning data 做 pretraining,可以相对 no-reason baseline 带来 \(16\%\) 的平均绝对提升。并且 pretraining gains 会随规模和多样性提高,驱动 math、science、code 改善。
第二个问题是:如果一个模型 pretraining 阶段没有 reasoning data,能不能后面用更多 SFT compute 追上?
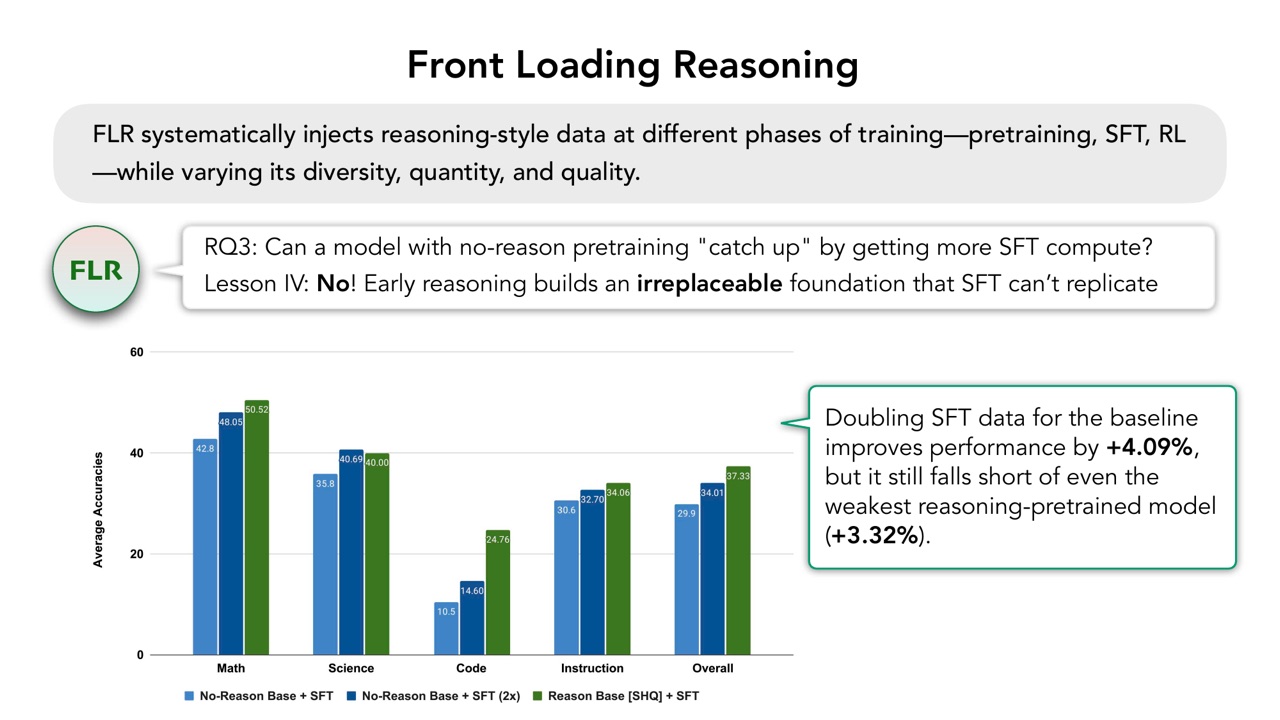
PPT 的结论是不能。Early reasoning builds an irreplaceable foundation that SFT cannot replicate。即使 baseline 的 SFT 数据翻倍,性能提升 \(4.09\%\),仍然不如最弱的 reasoning-pretrained model。
第三个问题是:如果后面做 heavy RLVR,front-loading 的收益还重要吗?
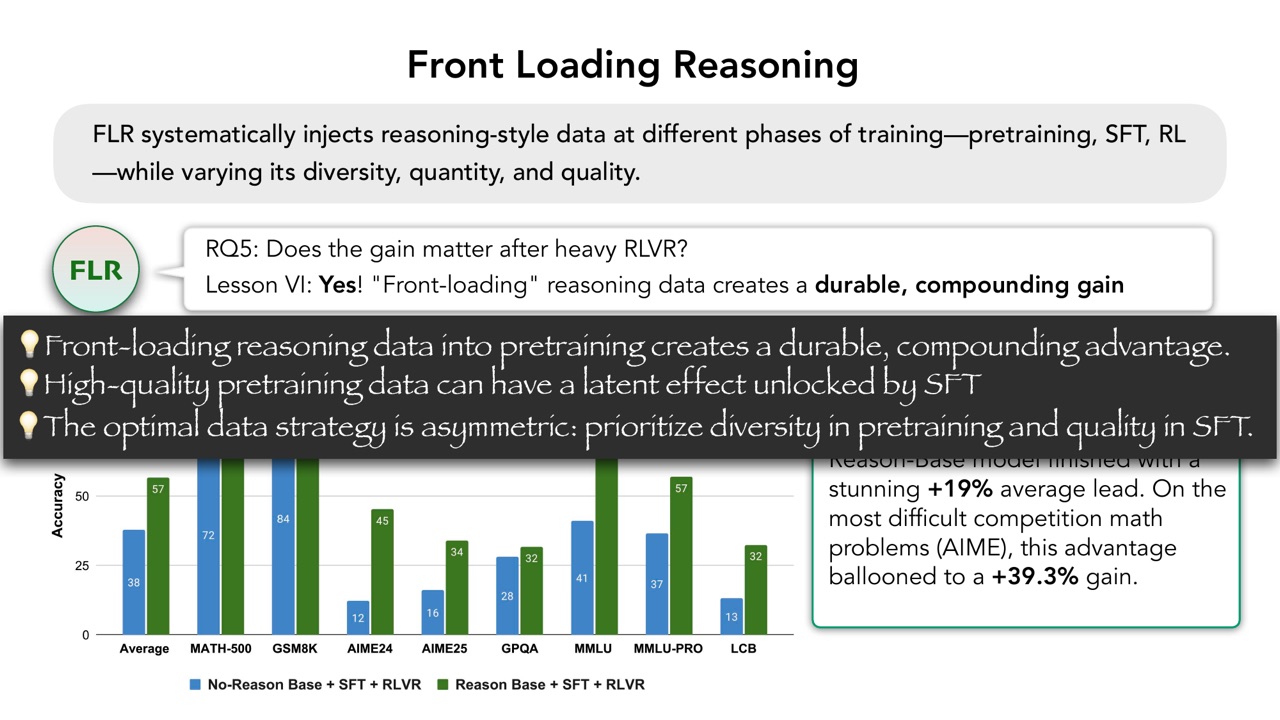
PPT 的结论仍然是重要。Front-loading reasoning data 会形成 durable、compounding gain。高质量 pretraining data 可能具有 latent effect,要通过 SFT 解锁。最优数据策略是不对称的:pretraining 阶段优先 diversity,SFT 阶段优先 quality。经过 reinforcement learning 后,Reason-Base 模型平均领先 \(19\%\),在 AIME 上领先达到 \(39.3\%\)。
这部分对整个课程很重要:模型能力不是只由最后一步 RL 决定。早期数据会改变模型之后能学到什么、能被 SFT 解锁什么、能被 RL 放大什么。
20. OpenThoughts:协作本身也是 scaling 方法
对应 slides 70-75。
PPT 接着回到三类创新:unconventional data、unconventional algorithms、unconventional collaboration。
OpenThoughts 是这里的协作例子。PPT 展示了 OpenThoughts 团队和 OpenThoughts3-1M。

OpenThoughts3 被 PPT 称为 SOTA reasoning dataset recipe。
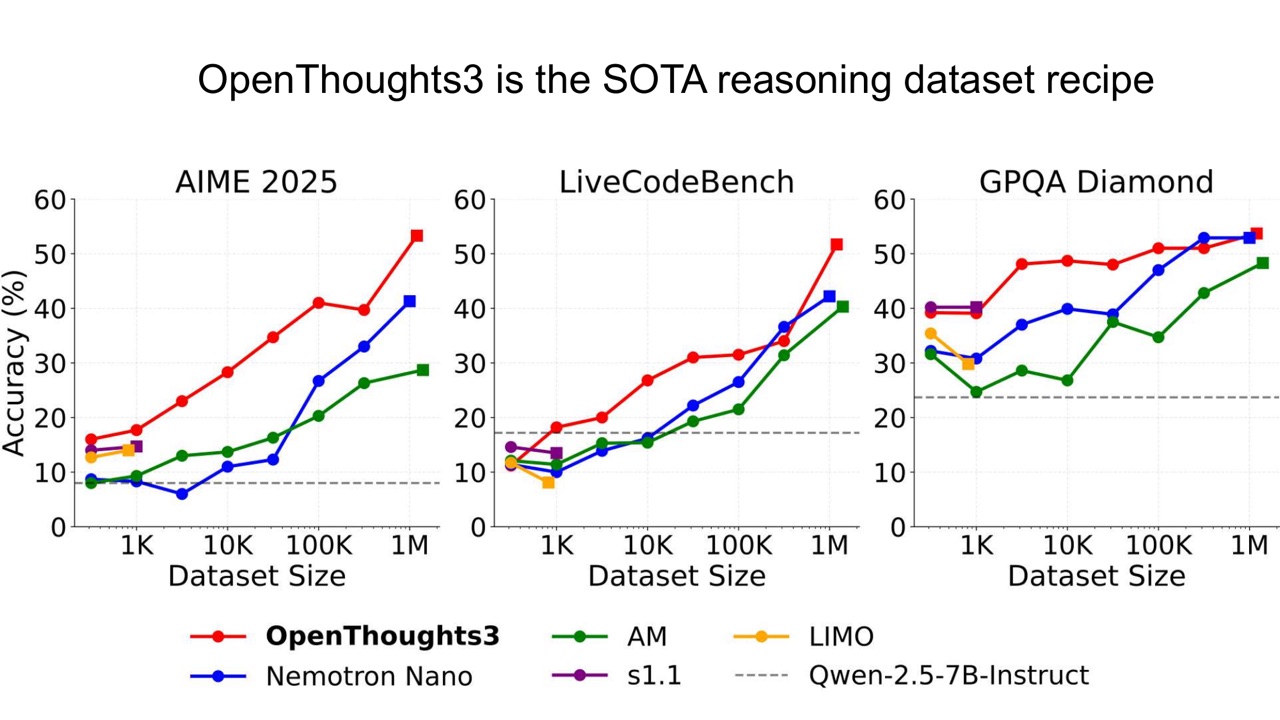
这和前面的 Prismatic、FLR 可以合起来看:
- Reasoning model 需要数据。
- 高质量 reasoning data 很难由一个小团队闭门造完。
- 数据 recipe、训练 recipe、评测结果如果开放,就能让更多模型复现和改进。
PPT 还强调:super effortful SFT can win over effortful RL。
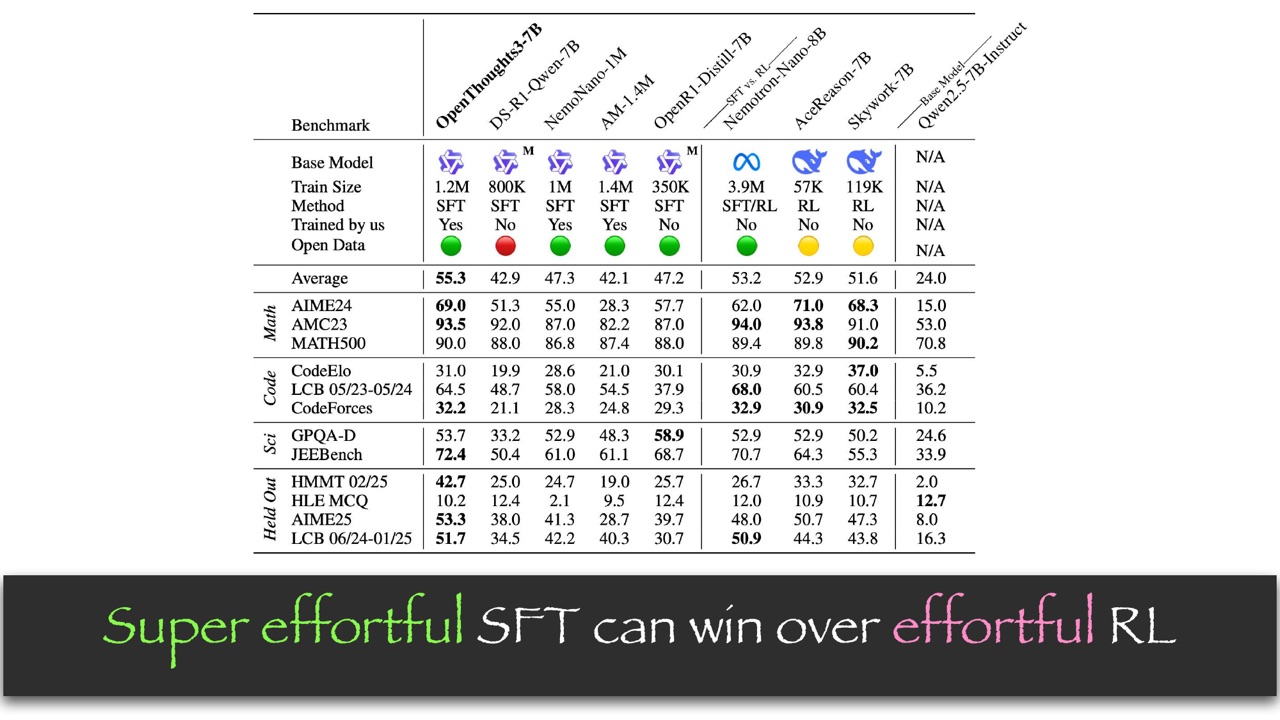
这句话和前面对 effortless SFT 的讨论呼应。不要把 SFT 想成简单模仿、把 RL 想成唯一创新。只要 SFT 数据足够好、配方足够系统、协作足够强,SFT 也可以成为 reasoning model 的强路线。
PPT 的总结页再次强调:

- Nothing is easy。
- No pain no gain。
- Everything is doable with efforts。
- Collaboration 很重要。
- Base LLM 和 RL 的 chemistry 很重要。
- Effortless RL 不等于 effortful RL。
- Effortless SFT 不等于 effortful SFT。
这些句子看起来像鸡汤,但放在本讲的技术上下文里,它们指的是:模型训练结论高度依赖训练投入、数据配方、模型基底和协作规模。不要用低投入实验的负结果否定高投入路线,也不要用单一阶段的结果解释整个训练栈。
21. LLM 101:模型生产其实都是数据问题
对应 slides 78-79。
PPT 后半段用 LLM 101 总结现代 LLM 生产流程:
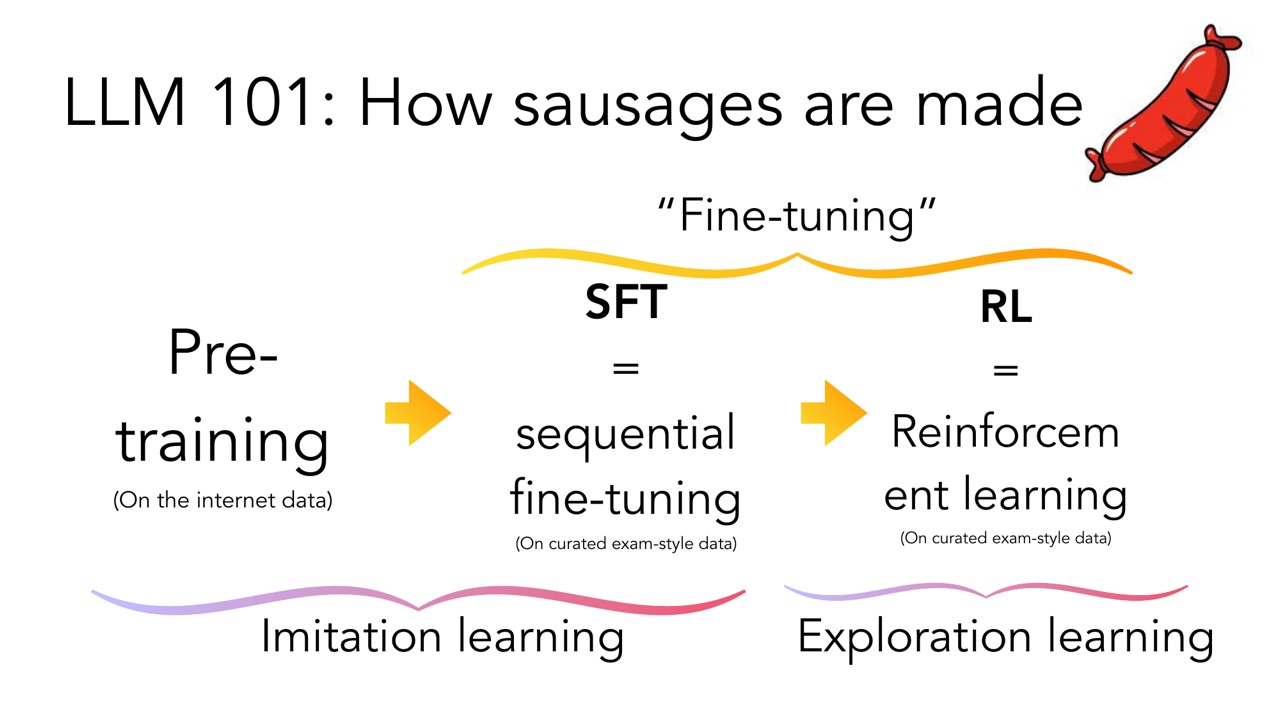
流程是:
对应学习范式是:
- Pretraining 和 SFT 更像 imitation learning。
- RL 更像 exploration learning。
但是 PPT 随后强调:it is all about data。

当 internet data 不够时,让 humans write exam data。当人工 exam data 也不够时,让 AI synthesize data。目标是把 OOD data 通过 brute-force data synthesis 变成 in-distribution data。
这句话非常关键。很多时候我们说模型“泛化”到 OOD,其实训练团队可能已经通过大量合成数据,把原本 OOD 的情况覆盖进训练分布。于是模型看起来会泛化,背后却是数据工程把外部世界搬进了训练集。
这不是贬义,而是说明现代 LLM 的能力越来越依赖 data flywheel:模型生成数据,数据训练模型,更强模型再生成更强数据。
22. Universe of Knowledge = Universe of Synthetic Data
对应 slides 83-84。
PPT 用 Universe of Knowledge 解释未来数据扩展的方向。
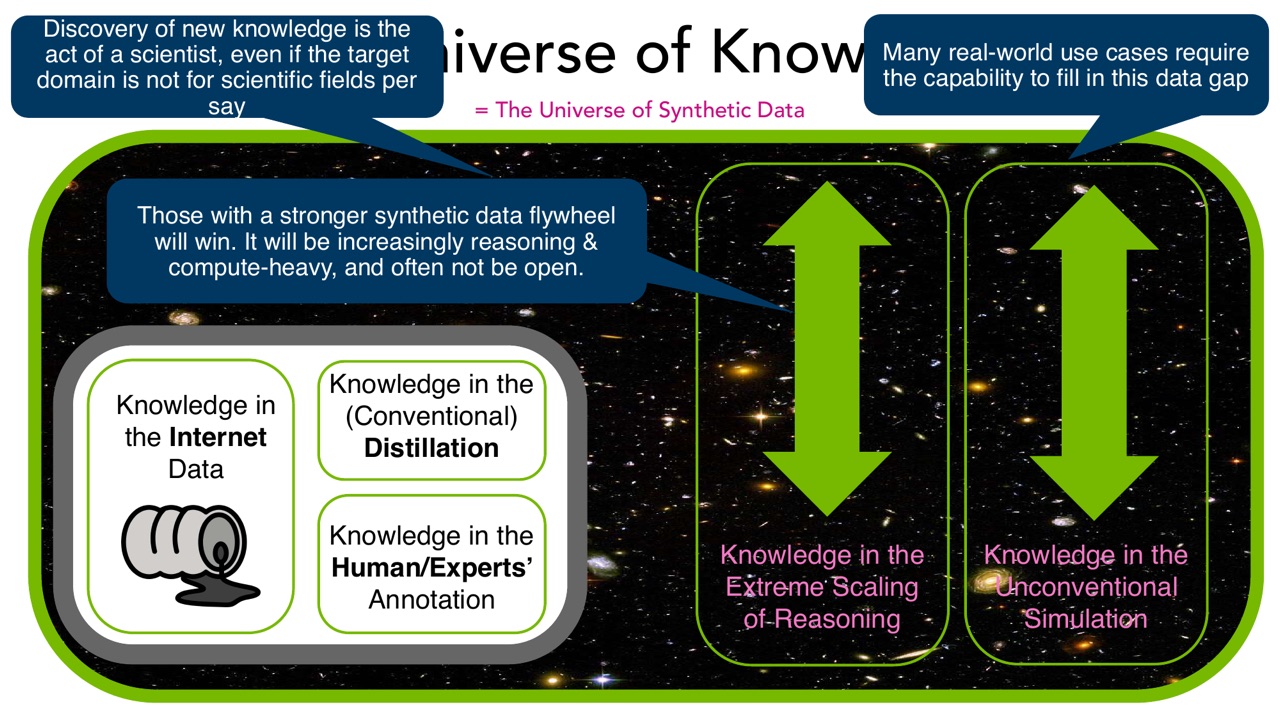
图中左侧是:
- Knowledge in the Internet Data。
- Knowledge in Conventional Distillation。
- Knowledge in Human/Experts' Annotation。
右侧是更大的空间:
- Knowledge in the Extreme Scaling of Reasoning。
- Knowledge in the Unconventional Simulation。
PPT 的结论是:拥有更强 synthetic data flywheel 的团队会赢。这个飞轮会越来越 reasoning-heavy、compute-heavy,而且 often not open。
这其实提出了一个现实矛盾:
- 一方面,第 15 讲开头希望 democratize generative AI。
- 另一方面,最强 synthetic data flywheel 可能依赖大量推理算力和闭源生产系统。
因此 open collaboration 不是装饰,而是对抗集中化趋势的一种技术与组织路线。
23. AI 和人类智能:相似处与差异处
对应 slides 87-89。
PPT 最后讨论 AI 和 human intelligence 的关系。

AI mirrors human intelligence 的地方包括:
- Reasoning 往往是 memorized knowledge。
- 都有 exploitation 和 exploration 的 trade-off。
- 多样 examples 和 experiences 会增强学习。
这和本讲前面的技术内容对应得很紧:
- ProRL 讨论 exploration/exploitation 和 entropy。
- Prismatic 讨论 diverse examples。
- RLP/FLR 讨论 reasoning knowledge 怎样在训练早期进入模型。
AI diverges from human intelligence 的地方包括:
- AI 有更多 data、compute、memory。
- AI 的 abstraction 和 conceptualization 更少。
- AI 的 training 和 testing 分离更清晰。
PPT 还用一页很直接的话说明模型是如何生产出来的:人类互联网数据、人类大规模投入、人类标注、人类工程直觉和大量细节。为了避免页面渲染问题,这里不复写 PPT 中的货币符号,但含义是:现代 LLM 并不是脱离人类凭空出现的智能,而是高度依赖人类知识、资金、标注和工程判断的系统。
最后,PPT 留下三个 open research questions:

- 是否需要新的 intelligences 理论?
- 是否需要新的 knowledge 和 reasoning 理论?
- 人类没有 1M token 的 context window,这是 limitation 还是 blessing?
第三个问题非常值得思考。超长上下文看起来一定是优势,因为模型能读更多信息。但人类没有超长上下文,反而必须压缩、抽象、遗忘、形成概念。PPT 没有给答案,而是把它作为开放问题:也许超长上下文能带来强记忆;也许有限上下文迫使系统做更高层抽象。未来 reasoning model 的理论可能必须同时解释这两种现象。
24. 把本讲串成一条学习线
第 15 讲可以用下面这条线来复习:
当前 scaling laws 太依赖极端算力
-> brute-force scaling 不够
-> smart scaling:数据、算法、协作
-> LRMs 把 long thought 和 RL 推到中心
-> 但 effortless RL/SFT 的结论不能代表 effortful RL/SFT
-> ProRL 说明 prolonged RL 和 entropy control 可以让小模型变强
-> Prismatic 说明 synthetic reasoning data 需要多样性控制
-> RLP/FLR 说明 reasoning 应该更早进入 pretraining
-> OpenThoughts 说明开放协作能 scaling 数据和 recipe
-> 最终问题回到 intelligence、knowledge、reasoning 的新理论
如果你只记一个中心句,可以记:
25. 关键概念速查
| 概念 | 本讲含义 | 为什么重要 |
|---|---|---|
| Brute-force scaling | 主要靠更大模型、更多数据、更大算力提升能力 | 门槛高,受数据与算力瓶颈限制 |
| Smart scaling | 用更好的数据、算法、训练流程和协作继续提升 intelligence | 是本讲所有技术路线的总框架 |
| Data saturation | 高质量互联网数据有限且逐渐耗尽 | 推动 synthetic data、RLP、FLR 等方法 |
| LRM | 以 long thought 和 reasoning 为核心的 language model | 表示从普通生成到推理模型的转向 |
| Pass@1 | 生成一个答案时的成功率 | 衡量默认输出能力 |
| Pass@K | 生成 \(K\) 个答案时至少一个成功的概率 | 衡量多样采样和探索覆盖 |
| Effortless RL | 低投入、短训练或缺少精细控制的 RL | 不能代表 RL 路线的上限 |
| Effortful RL | 长程、细致、控制 entropy/KL/采样的 RL | ProRL 展示其对小模型的潜力 |
| Sustainable entropy | 训练中持续保持适度探索 | 防止过早 entropy collapse |
| Dynamic sampling | 选择中等难度样本以维持学习信号 | 避免样本太易或太难导致 reward 无区分度 |
| Decoupled clipping | 分别控制 \(\epsilon_{\mathrm{low}}\) 和 \(\epsilon_{\mathrm{high}}\) | 平衡压制坏动作与提升探索动作 |
| Synthetic data | 由模型或算法生成训练数据 | 扩展 internet data 之外的 reasoning 覆盖 |
| Mode collapse | 合成数据或模型行为分布变窄 | 会损害 OOD 泛化 |
| Gradient representation | 用 \(\nabla_\theta \log P_\theta(y\mid x)\) 表示样本 | 表示样本对模型学习的作用 |
| G-Vendi Score | 基于 gradient representation 的多样性分数 | 预测泛化和 OOD 泛化 |
| RLP | Reinforcement as a Pretraining Objective | 把 reasoning 放到 pretraining 阶段 |
| Information gain reward | thought 让 next token 更可预测时获得 reward | 不依赖外部 verifier,且 reward dense |
| FLR | Front-Loading Reasoning | 研究 reasoning data 放在训练早期的收益 |
| OpenThoughts | 开放 reasoning dataset recipe 和协作路线 | 体现 unconventional collaboration |
| Synthetic data flywheel | 模型生成数据,数据训练模型,更强模型再生成更强数据 | 可能决定未来模型竞争 |
26. 公式复习
GRPO 目标:
Decoupled clipping:
Gradient representation:
G-Vendi Score:
RLP reward:
EMA no-think teacher:
RLP 核心信息增益:
27. 自测题
- 为什么 PPT 说 democratizing generative AI 需要 transcending scaling laws?
- Brute-force scaling 和 smart scaling 的区别是什么?
- Data saturation 后,PPT 给出的三条路线分别是什么?
- LRMs 相对普通 LLMs 的三个关键变化是什么?
- 为什么 RLVR 可能让 Pass@1 变好、Pass@K 变差?
- Effortless RL 和 effortful RL 的区别是什么?
- ProRL 为什么强调 sustainable entropy?
- Dynamic sampling 为什么要选择中等难度样本?
- Decoupled clipping 中 \(\epsilon_{\mathrm{low}}\) 和 \(\epsilon_{\mathrm{high}}\) 分别控制什么?
- 为什么提高 \(\epsilon_{\mathrm{high}}\) 可以鼓励 broader exploration?
- ProRL 的结果如何支持 small model 的研究价值?
- 为什么 effortless SFT 的结论也不能代表 effortful SFT?
- Synthetic data 为什么会有 mode collapse 风险?
- Gradient representation 为什么比只看文本表面更适合衡量 reasoning data?
- G-Vendi Score 想衡量什么?
- Prismatic Synthesis 的 pipeline 包含哪些步骤?
- RLP 为什么说 reasoning is not just an add-on?
- RLP 的 reward 为什么可以被称为 information gain?
- 为什么 RLP 是 verifier-free?
- FLR 的结果为什么说明 early reasoning exposure 不容易被后训练洗掉?
- 为什么 pretraining 阶段更强调 diversity,而 SFT 阶段更强调 quality?
- OpenThoughts3 在本讲中代表了什么?
- 为什么 super effortful SFT 可能胜过 effortful RL?
- Synthetic data flywheel 为什么可能成为未来竞争核心?
- 人类没有 1M token context window 可能为什么既是限制又可能是 blessing?
28. 复习时最容易混淆的点
第一,不要把 smart scaling 理解成不再 scaling。 它仍然追求能力增长,只是从单纯扩大模型和数据,转向更聪明地组织数据、训练目标、推理过程和协作。
第二,不要把 RL 的负面发现直接推广到所有 RL。 PPT 特意区分 effortless RL 和 effortful RL。ProRL 说明,只要训练足够持久并控制 entropy,结论可能不同。
第三,不要把 SFT 看成低级模仿。 PPT 同样提醒 effortless SFT 不等于 effortful SFT。OpenThoughts 和 super effortful SFT 表明,高质量数据配方和协作可能让 SFT 非常强。
第四,不要把 synthetic data 等同于更多样本。 更多样本如果模式单一,可能只是更大的 mode collapse。Prismatic 关心的是多样性和质量,而不是纯数量。
第五,不要把 reasoning 只当后训练技巧。 RLP 和 FLR 的核心就是:reasoning 可以更早进入 pretraining,并且这种早期基础可能在 SFT 和 RL 后继续发挥作用。
第六,不要把开放问题当成“还没讲完”。 这讲的开放问题本身就是研究入口:新的 intelligence 理论、knowledge/reasoning 理论、context window 和 abstraction 的关系,都是未来 NLP 的核心问题。