09. RAG 与语言智能体
官方 PPT 来源:Lecture 10 官方 PPT:RAG and Language Agents
本页是网站中的第 9 个 CS224n 专题,内容对应官方 PPT Lecture 10: RAG and Language Agents。PPT 前几页先收尾上一讲的 Adapter 和高效适配,本页只简要定位;主体是 open-domain question answering、retrieval augmented generation、language agents、reasoning、memory、tool use、agent data 和 agent evaluation。
本讲学习目标
学完这一讲,你应该能从零回答下面这些问题:
- Reading comprehension 和 open-domain question answering 有什么区别?
- 为什么只靠语言模型参数记忆很难回答所有问题?
- Retrieval augmentation 为什么能缓解知识更新和幻觉问题?
- Retriever-reader framework 的输入、输出和两个模块分别是什么?
- RAG 中 \(K\) 个 retrieved passages 为什么不是越多越好?
- BM25、dense vector retrieval、ColBERT 这几类 retriever 的差别在哪里?
- 为什么 retriever 可以训练,Dense Passage Retrieval 的核心想法是什么?
- Fusion-in-decoder 为什么把 retrieval 和生成式模型结合起来?
- 长上下文模型为什么仍可能无法有效使用很多文档?
- RAG 的 citation 为什么本身也可能 hallucinate?
- RARR 这类方法怎样检查和修改 LLM 输出?
- Language agent 和普通文本生成模型的根本差别是什么?
- 一个 language agent 通常由哪些组件组成?
- Reasoning 对 agent 为什么有帮助?
- ReAct 怎样把 reasoning 和 acting 交替起来?
- ReAct 相比只推理的 CoT 为什么能减少一部分幻觉?
- Self-consistency 为什么不是“只生成一次答案”?
- Reflexion 怎样把失败轨迹压缩成未来可用的经验?
- Multi-agent debate 和 orchestrator 分别在解决什么问题?
- Episodic、semantic、procedural memory 分别存什么?
- 为什么 context window 不等于真正的 long-term memory?
- MemGPT 为什么被 PPT 称为 OS-inspired virtual context management?
- Toolformer 学的到底是什么:工具本身,还是调用工具的时机和参数?
- Gorilla 为什么把 LLM 连接到大量 API?
- Coding agents、web/app agents、computer use agents 的环境、观察空间、动作空间分别是什么?
- Agent data 为什么比普通文本数据更难规模化?
- Agent evaluation 为什么比 QA accuracy 更难?
PPT 脉络
| 部分 | 官方 PPT 内容 | 本讲义对应章节 |
|---|---|---|
| PEFT 收尾 | function composition、adapter、language adapter、performance comparison、knowledge distillation | 0 |
| QA 与 RAG | reading comprehension、open-domain QA、retrieval augmentation、retriever-reader、retriever 类型、trainable retriever、generative reader | 1-6 |
| RAG 的关键问题 | 文档数量、long-context limitation、web search、RARR、citation hallucination | 7-9 |
| Language agents | words to action、agent key components | 10 |
| Reasoning and planning | reasoning、ReAct、CoT/SC、Reflexion、multi-agent debate、orchestrator | 11-16 |
| Memory | episodic/semantic/procedural memory、generative agents、MemGPT | 17-21 |
| Tool use | ToolkenGPT、Toolformer、Gorilla | 22-24 |
| Agent applications, data, evaluation | coding/web/computer agents、data scaling、SWE-smith、agent evaluation、coding agent loop | 25-29 |
0. PPT 开头:从 Adapter 收束到 RAG 与 Agents
官方 PPT 的第 3-9 页延续上一讲的 Efficient Adaptation:
Function composition 可以给预训练模型叠加任务相关函数。
Adapter 在 Transformer 层之间插入小的可训练函数。
Adapter 常用 bottleneck 结构。
Adapter 可以用在 task adaptation,也可以用在 language adaptation。
Adapter 在 GLUE 等任务上能用更少 task-specific 参数接近 full fine-tuning。
这些内容已经在 08. 提示工程与参数高效微调 中系统讲过。这里要记住它和本讲的连接:当模型越来越大时,NLP 系统的能力不再只来自“改模型参数”,还来自“把模型接到外部知识、工具、环境和记忆”。RAG 和 language agents 正是这种系统化方向。
1. 从 Reading Comprehension 到 Open-Domain QA
1.1 Reading comprehension 是什么
PPT 先从 SQuAD 式 reading comprehension 开始。
Reading comprehension 的设定比较“干净”:
PPT 写成形式化输入输出:
输出是文章中的一个连续片段:
这里 \(N\) 大约是 100,\(M\) 大约是 15。也就是说,问题和文章都已经给好,模型只要在已知上下文里定位答案。
1.2 传统方法与神经方法
PPT 也回顾了 conventional methods:
先生成候选答案 a_1, a_2, ..., a_M
再为 passage、question、answer 构造特征向量
最后用 multi-class logistic regression 选择答案
这些特征可以是 word/bigram features,也可以是 parse tree matches。它们的特点是:人要先设计“什么叫可能匹配”,模型再学权重。
神经方法改变了这个模式。它把文章和问题表示成向量序列,然后直接预测 start/end。CS224n 前面的神经网络、RNN、Transformer 都是在为这类表示学习做铺垫。
1.3 Open-domain QA 难在哪里
Open-domain question answering 不再给定一段文章。
PPT 的设定是:
这比 reading comprehension 难得多,因为模型首先要解决“答案可能在哪里”。如果 reading comprehension 像开卷考试已经翻到指定页,open-domain QA 就像只知道图书馆里有答案,但不知道在哪本书、哪一页。
PPT 还区分了 open-domain 和 closed-domain:closed-domain 系统处理特定领域,比如医疗或技术支持;open-domain 系统面对更广的问题空间。
2. Retrieval Augmentation:把外部知识接进来
语言模型有一个天然矛盾:它可以在预训练阶段吸收很多知识,但参数知识并不容易更新,而且回答时可能生成没有依据的内容。
PPT 提出的核心问题是:能不能不要求语言模型记住一切,而是在回答时及时提供相关内容?
Retrieval augmentation 的思路是:
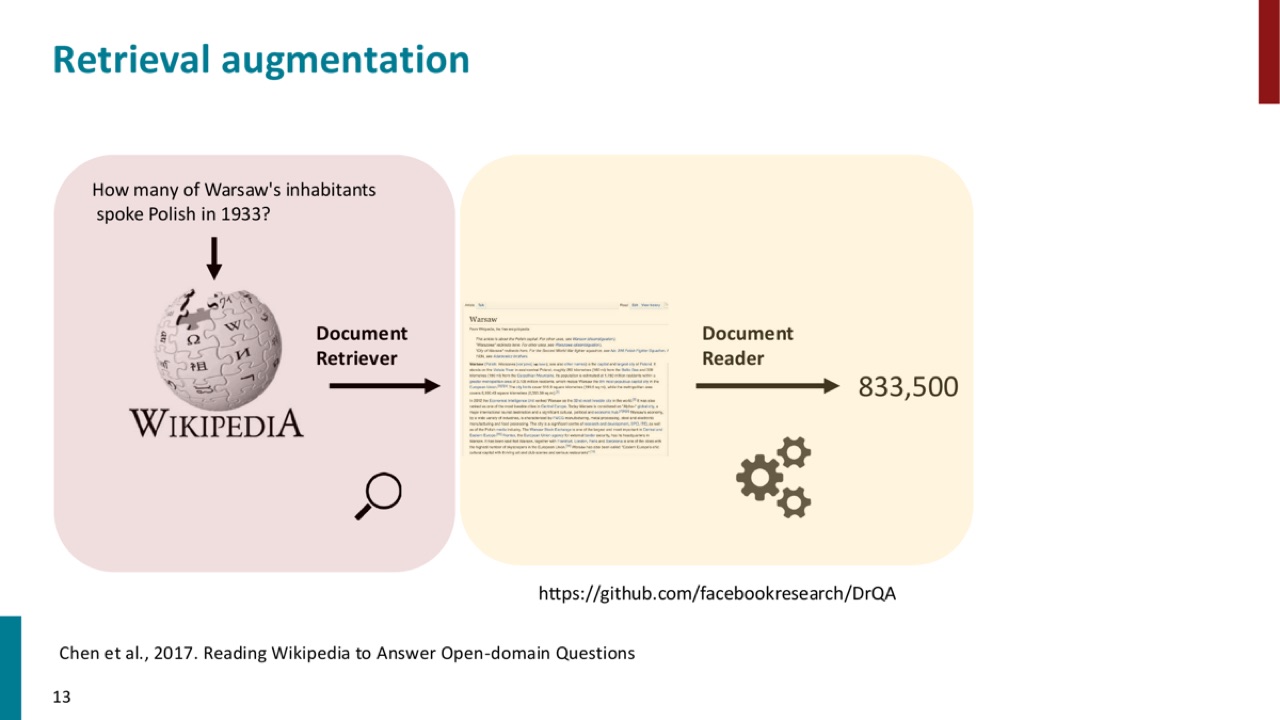
这张 PPT 图非常重要。它展示了 open-domain QA 的基本分工:
- Document retriever 负责从大型文档库里找候选文档。
- Document reader 负责读候选文档并输出答案。
- 最终答案不是直接从参数里“背出来”,而是通过外部文档支持。
2.1 为什么 retrieval 有用
PPT 强调了 retrieval 的两个直接好处。
第一,dynamic。检索系统的文档库可以更新和添加文档。如果某个事实在模型训练后发生变化,不一定要重新训练整个语言模型,可以更新外部语料。
第二,interpretable。模型可以生成指向 retrieved documents 的 pointers,也就是 citation,帮助人检查生成内容是否有依据。
这两个优点也解释了为什么 RAG 在实际系统里很常见:它把语言模型从“封闭记忆体”变成“可以临时查资料的生成器”。
3. Retriever-Reader Framework
PPT 给出了 RAG 和早期 open-domain QA 的统一框架。
输入是大型文档集合和问题:
输出是答案字符串:
系统分成两个模块:

3.1 Retriever 做什么
Retriever 的任务是从 \(\mathcal{D}\) 中找出 \(K\) 个候选 passages:
这里 \(K\) 是预先设定的,比如 100。
如果 retriever 找错了,reader 再强也很难回答。原因很朴素:答案根本没进入 reader 的上下文。
3.2 Reader 做什么
Reader 把问题 \(Q\) 和候选 passages \(\{P_1,\ldots,P_K\}\) 当成 reading comprehension 问题。
PPT 给出两种 reader:
- 训练在 SQuAD 和其他 distant-supervised QA datasets 上的 neural reading comprehension model。
- Zero-shot LLM,比如 ChatGPT 一类模型。
换句话说,RAG 可以接传统 neural reader,也可以接现代生成式 LLM。
3.3 RAG 和“直接问模型”的区别
直接问模型时,信息来源主要是模型参数和上下文中的用户输入。RAG 多了一个检索步骤,把外部文档放进上下文。
可以把差别记成:
| 系统 | 知识来源 | 主要风险 |
|---|---|---|
| Closed-book LM | 参数记忆 | 知识过期、凭空生成 |
| Retriever-reader QA | 外部文档 + reader | 检索不到正确文档 |
| RAG with LLM | 外部文档 + LLM generation | 检索错误、上下文利用失败、citation 幻觉 |
4. 不同类型的 Retriever
PPT 问了一个关键问题:retrieval system 应该怎样检索相关 passages?
官方 PPT 列出三类:
4.1 Word-overlap retriever
Word-overlap 方法看问题和文档之间有多少词面重合。BM25 属于这一类。
它的直觉是:如果问题里有 “Warsaw inhabitants Polish 1933”,包含这些词的文档更可能相关。
这种方法快、稳定、易解释,但也容易错过语义相同而用词不同的文档。
4.2 Vector retrieval
Vector retrieval 把问题和文档编码成向量,然后比较向量相似度。PPT 提到 DPR 和 sentence vectors。
它的直觉是:问题和文档不一定要有相同词,只要语义接近,向量就应该靠近。
Dense Passage Retrieval 进一步让 retriever 可以通过问答数据训练。PPT 说:每个 passage 可以用 BERT 编码成向量,question 也编码成向量,retriever score 可以用二者 dot product 衡量。
可以写成:
其中 \(h_Q\) 是问题表示,\(h_P\) 是 passage 表示。
4.3 Neural 或 hybrid retriever
PPT 还提到 ColBERT 这类 neural systems。它介于纯预计算向量和完全用语言模型慢速计算之间,通过 document index 等方式在效果和速度之间折中。
4.4 Fast vs slow retrievers
PPT 的速度排序很直观:
这说明 RAG 不是“把所有文档塞给 LLM”这么简单。真正的系统要同时考虑 recall、precision、latency 和成本。
5. Retriever 可以训练
早期 retriever 可以是固定的 TF-IDF sparse model。PPT 随后强调:retriever 也可以训练。
5.1 Joint training 的难点
PPT 提到 latent retrieval for weakly supervised open-domain QA:可以用 BERT 编码 question 和 passage,并用 dot product 算检索分数。
难点是文档数量巨大。PPT 举例 English Wikipedia 有 21M passages。也就是说,每个问题背后都有海量候选 passage,不可能朴素地把所有 passage 都当普通分类标签处理。
5.2 Dense Passage Retrieval
DPR 的核心做法是用 question-answer pairs 训练 retriever。
PPT 的结论是:trainable retriever 使用 BERT 后,大幅超过 traditional IR retrieval models。
对学习者来说,DPR 的意义是:retrieval 不再只是信息检索课程里的固定模块,而成为神经 NLP pipeline 里可以优化的一环。
6. 从 Extractive Reader 到 Generative Reader
PPT 接着说,近期工作显示:生成答案通常比只抽取答案更有利。
例如 Fusion-in-decoder:
DPR 负责检索 passages,T5 这类生成模型负责在 decoder 中融合多段证据并生成答案。
这一步很重要,因为它把 open-domain QA 从“在文档中抽 span”推进到“基于文档生成自然答案”。现代 RAG 通常属于后者。
7. RAG 的核心瓶颈:能用多少文档?
PPT 提出一个看起来很自然的问题:
答案是:长上下文并不自动等于有效使用上下文。
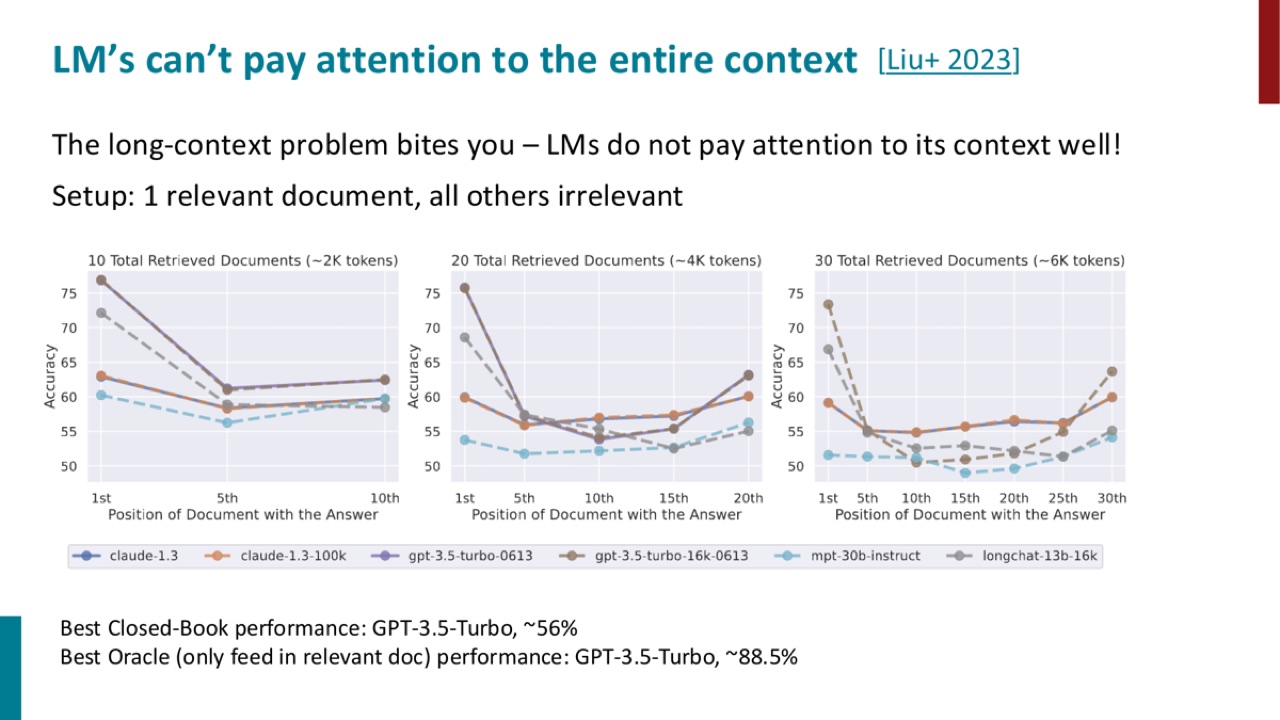
这张图的实验设定是:
PPT 的结论是:long-context problem 会影响模型。模型并不能稳定地关注整个上下文。
7.1 为什么“多检索”不一定更好
如果只放一个文档,retriever 必须非常准。放更多文档可以提高正确文档进入上下文的概率,但会带来新问题:
- 无关文档变多,干扰生成器。
- relevant document 可能被放在上下文中不显眼的位置。
- 模型可能没有真正读到关键证据。
- 成本和延迟上升。
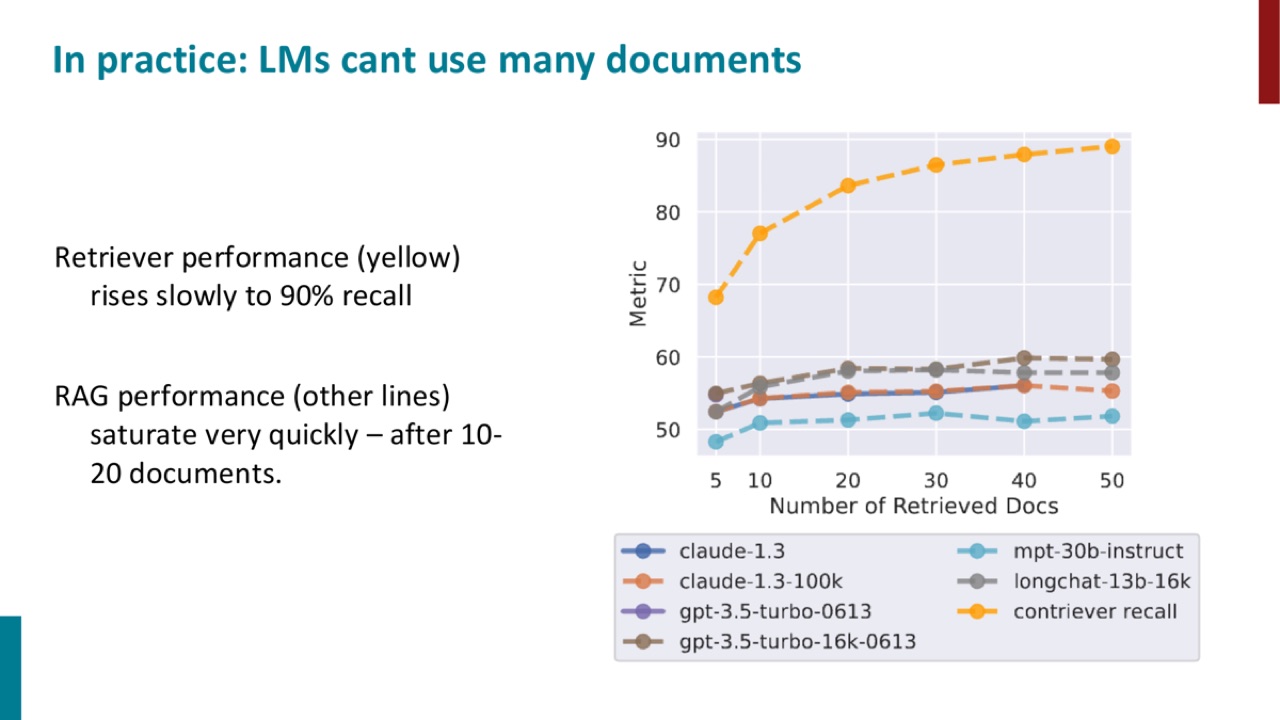
PPT 图里黄色线表示 retriever recall 随文档数上升,但其他 RAG 性能曲线很快饱和。这个现象告诉你:RAG 的优化不能只盯着“取更多文档”,还要改 retrieval quality、reranking、context organization 和 reader 行为。
7.2 一个实用判断
当 RAG 回答错时,不要马上怪生成模型。应该分三步检查:
- 正确证据有没有被 retriever 找到?
- 正确证据有没有被放进模型上下文?
- 模型有没有使用这段证据,而不是被其他文档带偏?
这三步分别对应 retrieval recall、context construction 和 generation faithfulness。
8. Web Search、RARR 与 Citation
PPT 讨论了带 web search 的 LLM 系统:模型搜索网页并给出引用。
这类系统看起来比纯语言模型更可信,因为它能显示来源。但 PPT 很快提醒:citation 自身也可能出错。
8.1 RARR 的流程
PPT 介绍 RARR:research and revise what LLMs say using LLMs。
它的大致流程是:
先用 QA 检查 source 和 response 是否一致
为每个 item 返回 citations
检测 text 和 citations 之间的不一致
如果不一致,就用 edit model 修改文本
最终选择 evidence snippets 形成 attribution report
这比“生成答案后随便附几个链接”更严肃,因为它把 citation 当成需要验证的对象。
8.2 Citation hallucination
RAG 的独特好处是可以引用来源。但 PPT 指出,citations 本身由 LLM 生成,因此 citations 也可能 hallucinate。
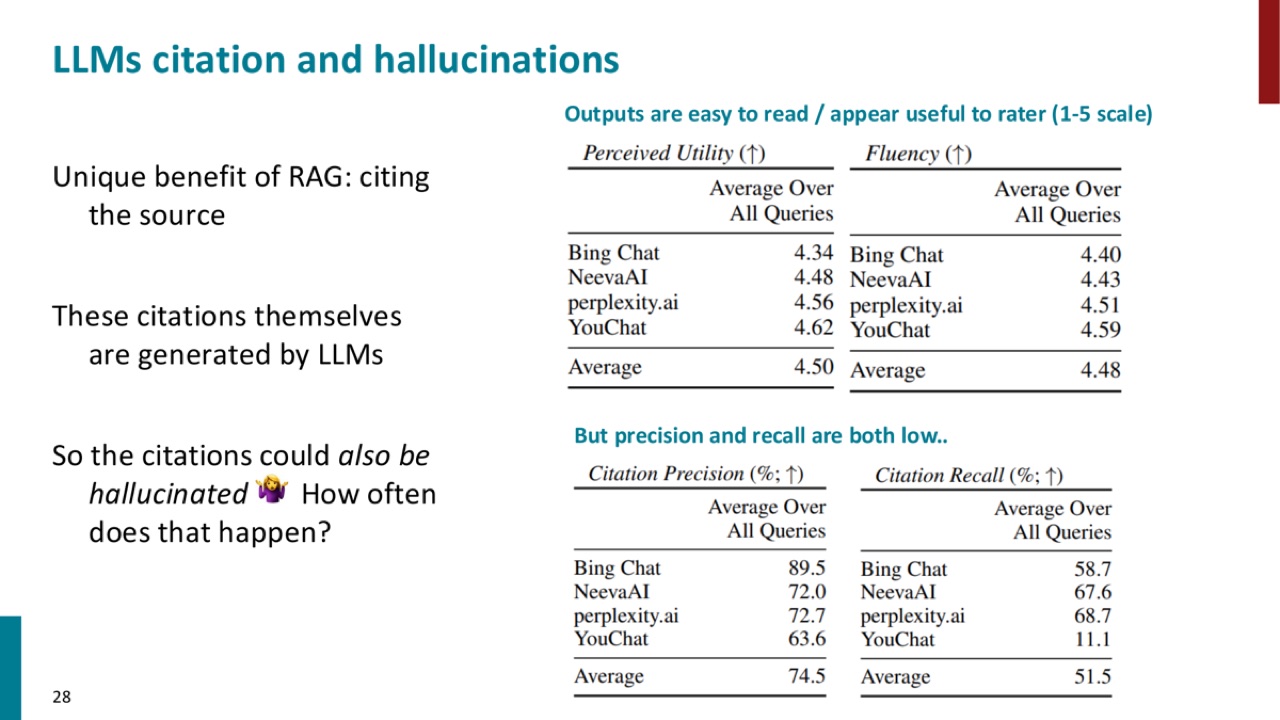
图中的重点不是某个系统名字,而是一个冲突:
这说明“看起来有引用”不等于“引用真的支持答案”。
8.3 Precision 和 recall 在 citation 中是什么意思
在 citation 语境里,可以这样理解:
| 指标 | 问的问题 |
|---|---|
| Citation precision | 给出的引用是否真的支持对应说法? |
| Citation recall | 该引用的支持证据是否被完整找出? |
如果 precision 低,说明引用可能挂羊头卖狗肉:有链接,但链接不支持答案。
如果 recall 低,说明系统可能漏掉了关键证据:答案也许部分正确,但证据覆盖不全。
所以一个好的 RAG 系统不仅要回答对,还要回答有据可查。
9. RAG 小结:它解决什么,又没解决什么
RAG 解决的是“参数知识封闭”的问题。
它让模型可以访问外部文档,从而更容易更新知识、提供证据、处理 open-domain QA。
但它没有自动解决所有幻觉:
- Retriever 可能找不到正确文档。
- 生成器可能忽略正确文档。
- 多文档上下文可能干扰模型。
- Citation 可能看起来可信但实际不支持答案。
因此,RAG 更像一个可调系统,而不是一个单一算法。你要同时设计 retriever、reader/generator、context packing、citation verification 和 evaluation。
10. Language Agents:从 Words 到 Action
PPT 的第二大主题是 language agents。
普通 LLM 的基本行为是:
Language agent 的行为是:
PPT 明确说,什么算 agent、什么算 agentic 仍有争论。本讲关注的是 LLM empowered systems 或 language agents 的关键组件。
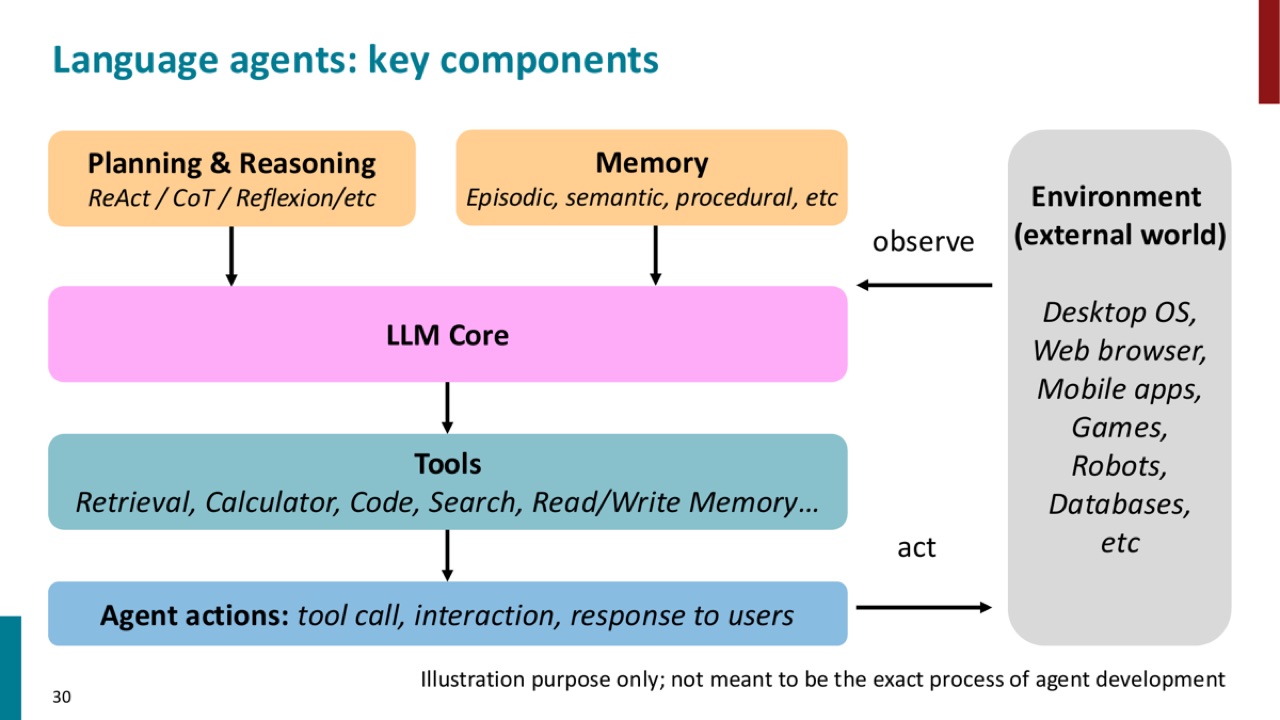
图里有五个核心部分:
- LLM core:语言模型本体。
- Planning and reasoning:ReAct、CoT、Reflexion 等。
- Memory:episodic、semantic、procedural 等。
- Tools:retrieval、calculator、code、search、read/write memory 等。
- Environment:desktop OS、web browser、mobile apps、games、robots、databases 等。
Agent actions 可以是 tool call、interaction,也可以是对用户的 response。
10.1 RAG 和 Agent 的关系
RAG 不是 agent 的全部。RAG 更像一个工具或组件:agent 可以把 retrieval 当工具调用,也可以用 retrieved documents 更新自己的工作上下文。
两者关系可以这样记:
| 概念 | 重点 |
|---|---|
| RAG | 让模型基于外部文档回答 |
| Agent | 让模型在环境中观察、推理、调用工具、执行动作 |
| RAG in agent | Retrieval 成为 agent 的一种 tool 或 memory read 操作 |
11. Reasoning:Agent 的内部动作
PPT 对 reasoning 做了三层区分:
- 对人来说,reasoning 是各种 mental processes。
- 对 LLM 来说,reasoning 是模仿某些人类思维过程的 intermediate generation。
- 对 agent 来说,reasoning 可以看成 internal actions。
这第三点很关键。Agent 的动作不只是点击、搜索、写文件。它在执行外部动作前,常常还需要先产生内部推理:
其中 \(o_t\) 是当前观察,\(r_t\) 是 reasoning,\(a_t\) 是动作。
11.1 为什么 reasoning 有帮助
PPT 用做菜例子说明:如果你发现盐没了,直接从 observation 到 action 很难。合理的 reasoning 是:
Reasoning 帮助 agent 做两件事:
- Generalization:遇到没见过的状态时,不只是复读训练动作,而是根据目标推导下一步。
- Alignment:动作更容易和任务目标保持一致。
12. ReAct:Reasoning with Acting
只做 reasoning 可能仍会幻觉。PPT 给了 Apple Remote 的例子:单纯 CoT 可能根据内部知识给出错误答案;ReAct 把 reasoning 和外部 search action 交替起来,最后借助观察修正路径。

ReAct 的结构可以记成:
它和普通 CoT 的关键差别是:每一步推理后可以采取外部动作,并把环境返回的 observation 放回下一步推理。
12.1 ReAct 为什么能减轻部分幻觉
CoT 的推理链主要来自模型内部。模型一旦在早期步骤编造了错误事实,后面可能沿着错误事实继续推理。
ReAct 加入外部 observation。搜索结果、工具返回值、网页内容、代码执行输出,都可以打断错误推理链。
PPT 对比 ReAct、CoT、self-consistency 时指出:
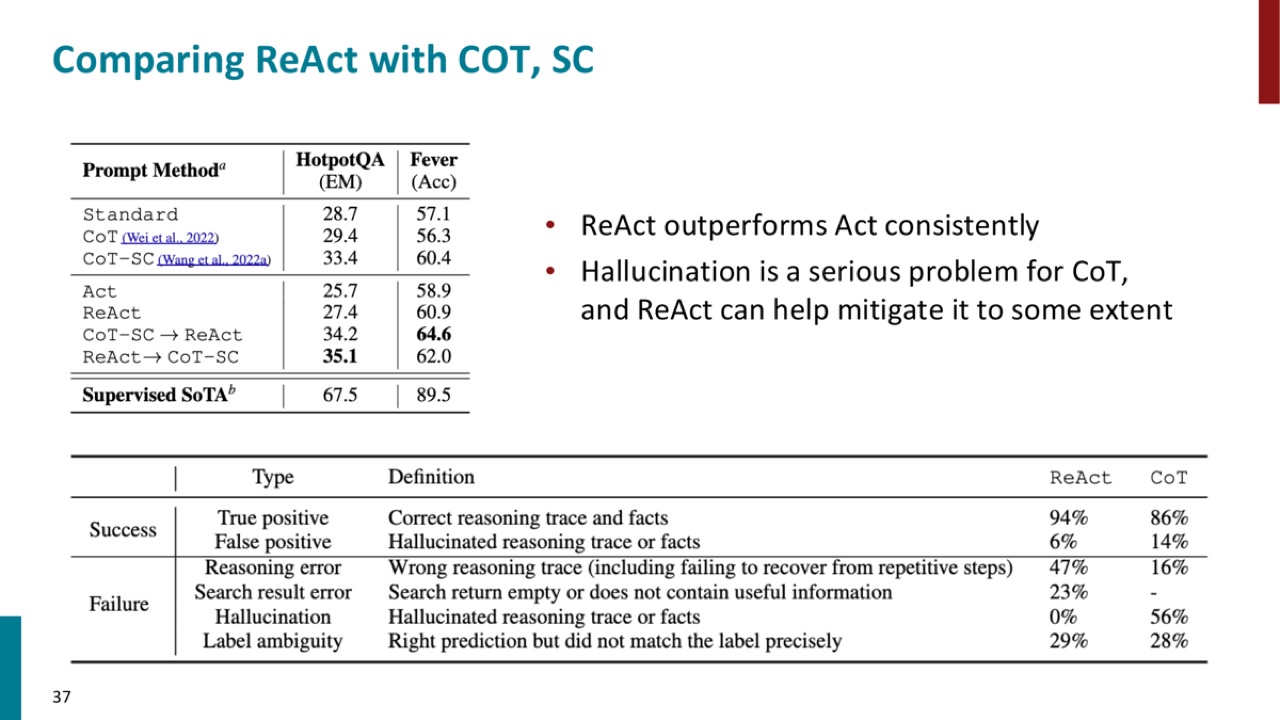
注意,ReAct 不是万能的。图里也显示 failure 仍可能来自 reasoning error、search result error、label ambiguity 等。ReAct 只是给模型提供了纠错机会,不保证每次都纠正。
13. Self-Consistency:多条推理路径投票
Self-consistency 的想法很简单:不要只采样一条 CoT 路径。
PPT 给出的步骤是:
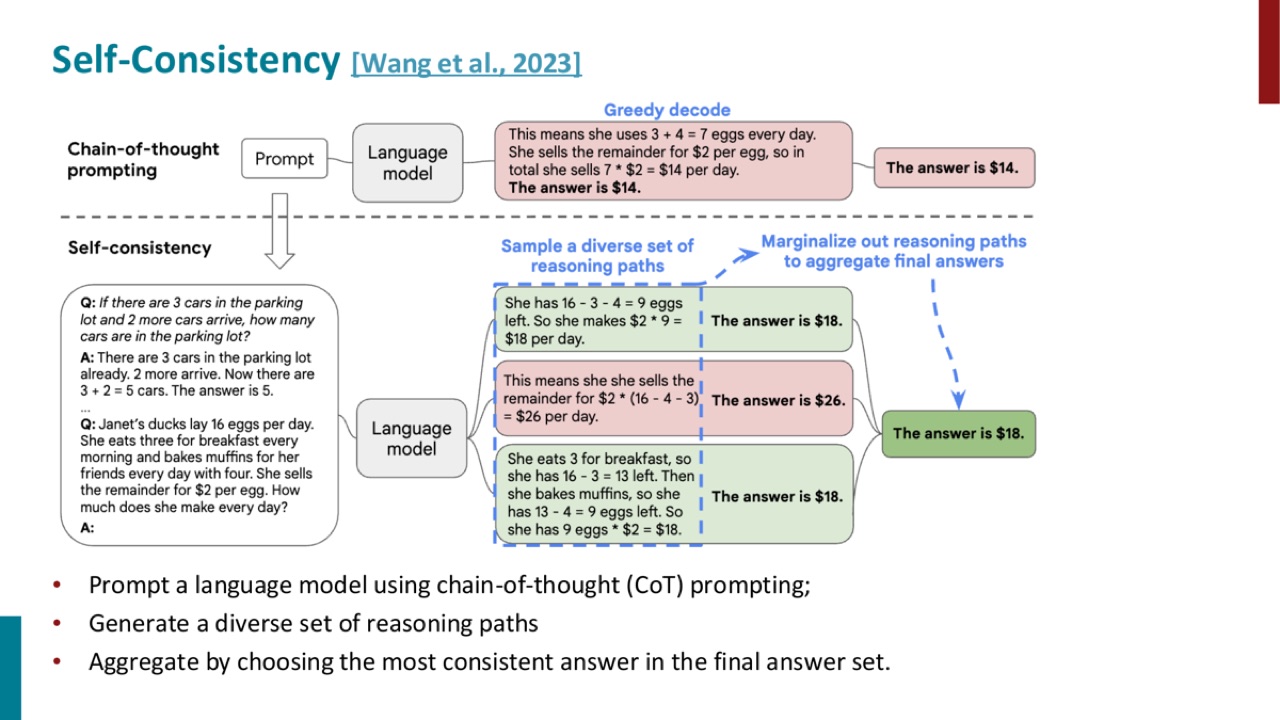
直觉上,如果一个问题有稳定答案,多条独立推理路径应该经常汇合到同一个答案。错误路径可能分散,正确答案可能更一致。
13.1 Self-consistency 和 ReAct 的区别
Self-consistency 主要在“生成多个内部推理路径”上做文章。
ReAct 主要在“把推理和外部动作交替”上做文章。
因此二者不是互斥关系。PPT 的对比表里也出现了 CoT-SC 和 ReAct 的组合。
14. Reflexion:把失败经验写成自我提示
Reflexion 的目标是通过 natural language feedback 强化 agent。
PPT 的描述是:

PPT 强调两个效果:
- 相比 ReAct 提升性能。
- 通过 self-reflection 把 long failed trajectories 蒸馏成未来可用的 self-hints,从而减少错误。
14.1 Reflexion 和普通 memory 的关系
Reflexion 不是简单把所有历史塞进上下文。它做的是“压缩失败经验”:
这和后面 memory 部分会连起来:agent 需要保存的不只是原始事件,还包括从事件中提炼出的知识。
15. Multi-Agent Debate 与 Orchestrator
PPT 还展示了 multi-agent debate:多个 agent 互相讨论,以改善 reasoning。
这里的基本动机是:一个模型的一条推理路径可能有盲点;多个 agent 产生不同观点,再通过讨论或评判聚合,有机会减少单点错误。
PPT 接着展示了 orchestrator。
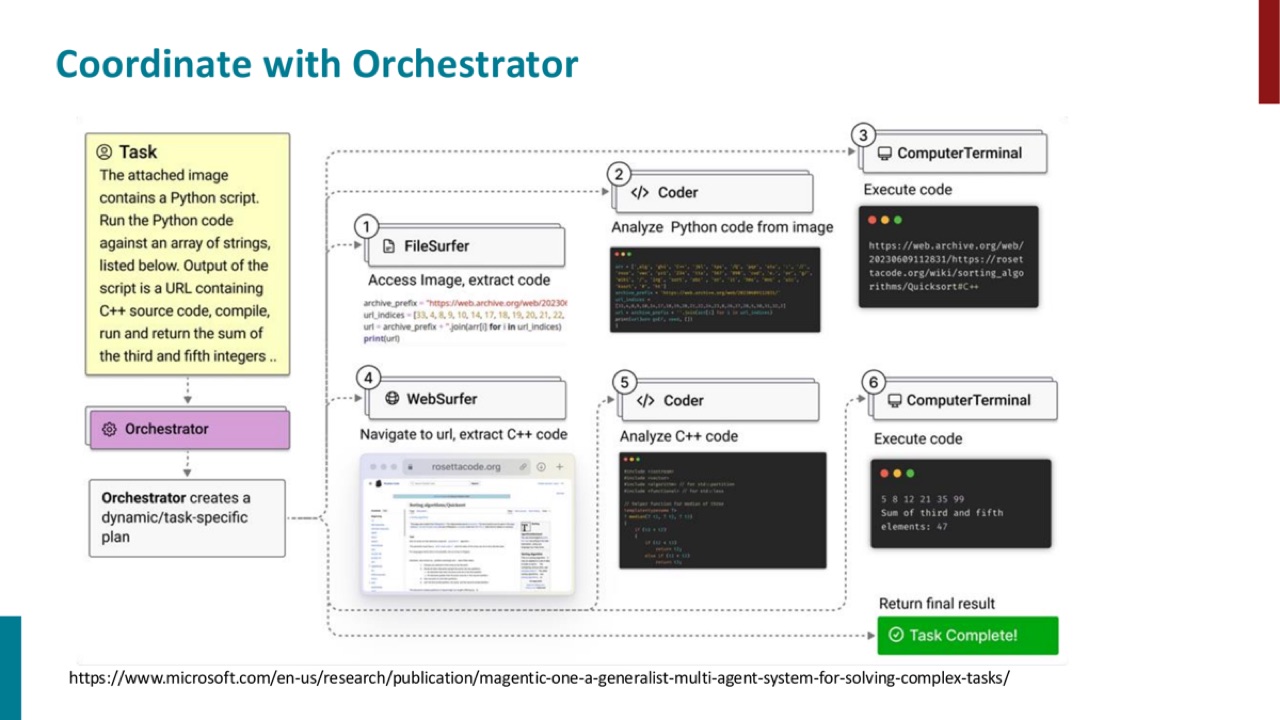
Orchestrator 的作用不是亲自完成每个细节,而是协调多个专门模块或 agent:
这和单一 agent 的不同在于:系统不再只是一条线性 Thought-Act-Observation,而是可以把任务分派给不同能力模块。
16. Reasoning and Planning 小结
到这里,你应该能区分几种方法:
| 方法 | 核心机制 | 解决的问题 |
|---|---|---|
| CoT | 生成中间推理 | 让模型显式分步 |
| Self-consistency | 多条推理路径投票 | 减少单一路径偶然错误 |
| ReAct | 推理和动作交替 | 用外部观察纠正内部幻觉 |
| Reflexion | 把反馈写成反思 | 让失败经验影响未来决策 |
| Multi-agent debate | 多 agent 讨论 | 降低单 agent 盲点 |
| Orchestrator | 协调多个模块 | 分解复杂任务和工具流 |
17. Memory:Agent 为什么需要长期记忆
PPT 转入 memory 时,先把 agent 图里的 memory 模块单独拿出来。
为什么需要 memory?
PPT 用 generative agents 说明:
这句话非常关键。Context window 只是临时工作区,不等于长期记忆。
17.1 三类 memory
PPT 按内容把 language agents 的 memory 分成三类。
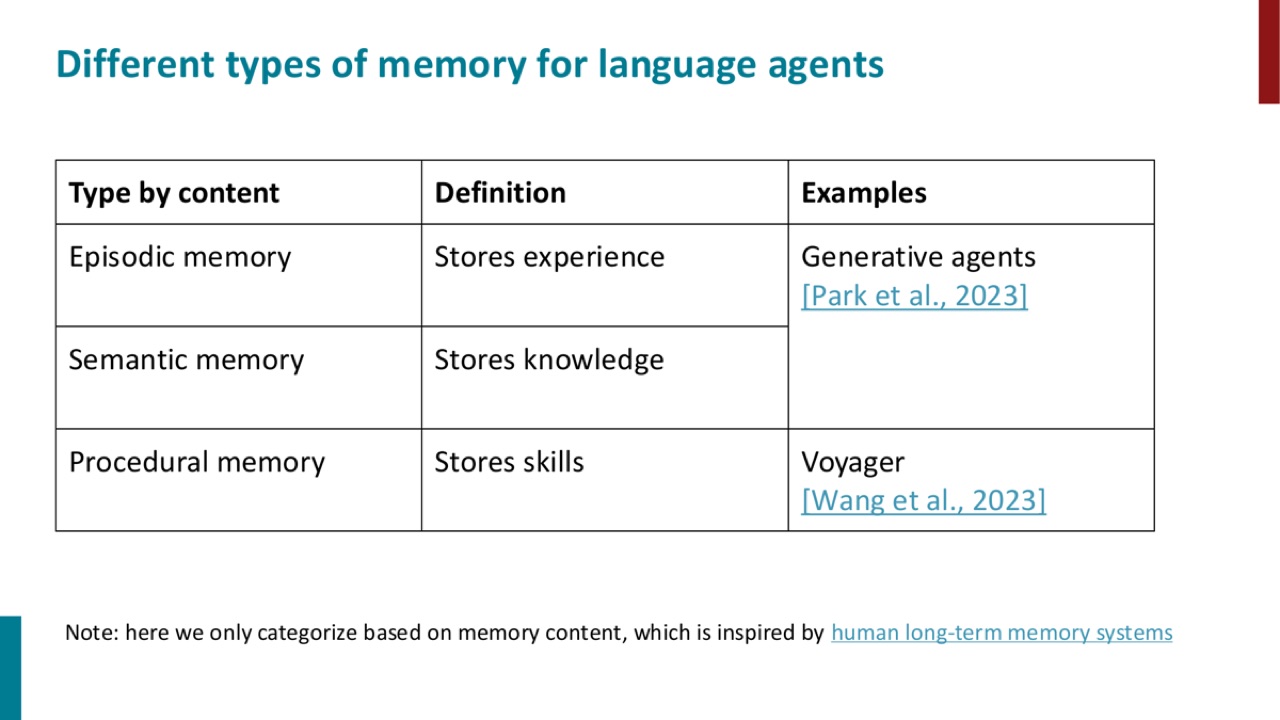
| 类型 | 存什么 | PPT 例子 |
|---|---|---|
| Episodic memory | Experience | Generative agents |
| Semantic memory | Knowledge | PPT 未展开具体系统名 |
| Procedural memory | Skills | Voyager |
这种分类来自人类长期记忆系统的启发,但 PPT 也说明这里只按 memory content 分类。
18. Episodic Memory:存经历
Episodic memory 存的是经验或事件。
PPT 对它的读写方式描述为:

Append-only event stream 的意思是:系统把发生过的事情不断追加到记录里,而不是每次都覆盖旧状态。
读取时不可能把所有历史都塞回上下文,因此要检索。PPT 图中 heuristic scores 包含 recency、importance、relevance 这类因素。
可以这样理解:
| 因素 | 问的问题 |
|---|---|
| Recency | 这件事是不是最近发生? |
| Importance | 这件事是否重要? |
| Relevance | 这件事和当前问题是否相关? |
Episodic memory 适合回答“发生过什么”“我之前做过什么”“这个角色最近经历了什么”。
19. Semantic Memory:存知识
Semantic memory 存的是知识,而不是原始事件。
PPT 对它的读写方式描述为:
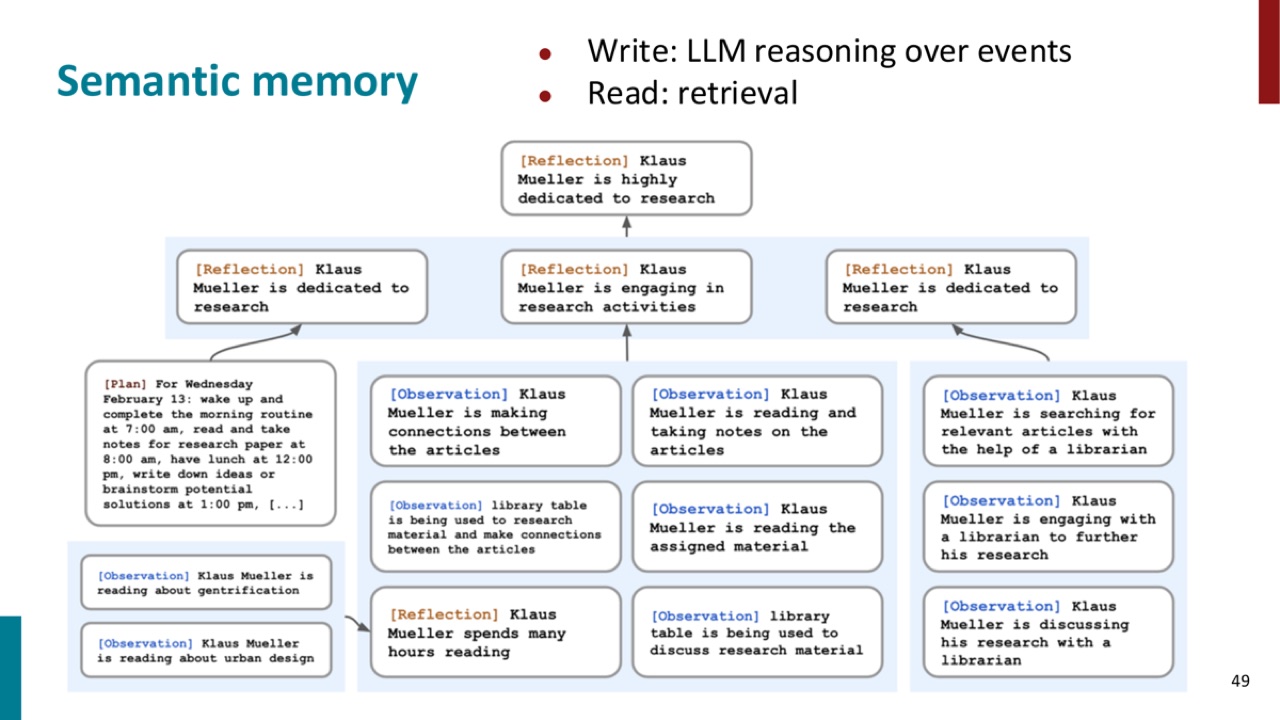
它和 episodic memory 的区别是:
例如,多个 observations 都显示某个角色经常做研究,semantic memory 可以把它压缩成“这个角色 dedicated to research”。这样后续检索时不必读回所有原始事件。
20. Procedural Memory:存技能
Procedural memory 存的是 skills。
PPT 对它的读写方式描述为:
这类 memory 面向“怎么做某事”。例如 Voyager 这类系统会把可复用的操作写成技能,再在未来任务中检索和调用。
它和 semantic memory 的差别是:
在 agent 系统里,procedural memory 尤其重要,因为 agent 不是只回答问题,还要执行动作。
21. MemGPT:把上下文当成虚拟内存管理
PPT 把 MemGPT 描述为 OS-inspired LLM system for virtual context management。
核心能力是:
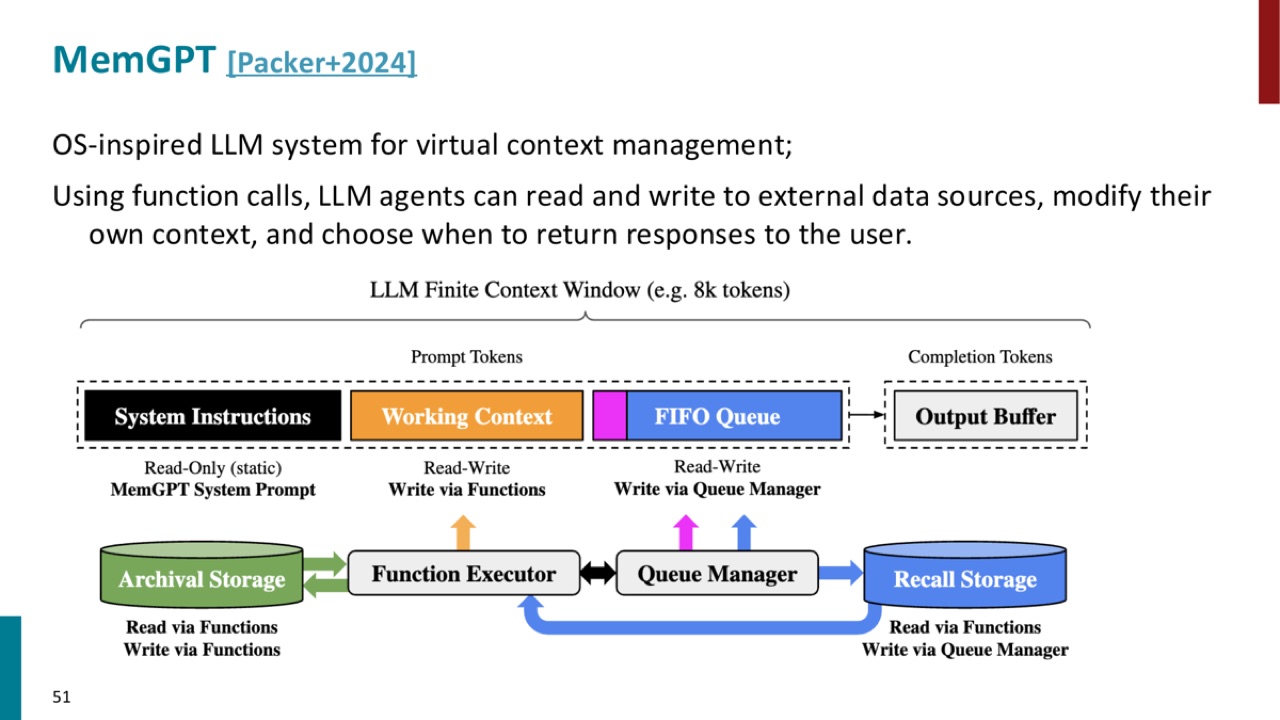
图里把 LLM 的有限 context window 分成不同区域:
- System instructions:只读的系统提示。
- Working context:可读写的工作上下文。
- FIFO queue:队列管理区域。
- Output buffer:输出区。
- Archival storage 和 recall storage:外部存储。
21.1 为什么说它像操作系统
操作系统管理内存时,不会把所有数据都放在 CPU 旁边。它会在不同层级之间调度:缓存、内存、磁盘。
MemGPT 的类比是:LLM context window 很小,所以 agent 要学会什么时候把信息写到外部存储,什么时候再读回来。
PPT 的实验图还说明,MemGPT 的 performance 不受 increased context length 明显影响。这支持了它的设计目标:不要只依赖更长上下文,而要管理上下文。
22. Tool Use:让模型从“说”扩展到“做”
PPT 的 tool use 部分把 agent 图里的 tools 模块单独拿出来。
工具可以包括:
对语言模型来说,工具调用解决两个问题:
- 模型自己不擅长的操作,比如精确计算。
- 模型参数中没有的信息,比如实时搜索或外部数据库。
23. ToolkenGPT 与 Toolformer
23.1 ToolkenGPT
PPT 介绍 ToolkenGPT:把每个 tool 表示成一个 token,也就是 toolken,并学习它的 embedding。
这样,触发工具调用就类似生成普通词。当 toolken 被触发后,语言模型再补全工具参数,让工具执行。
23.2 Toolformer
Toolformer 的目标是让语言模型学会使用工具。
PPT 明确说,它训练 LMs 决定:

Toolformer 使用 self-supervised learning,只需要每个 API 少量 demonstrations。PPT 列出的工具包括 calculator、Q&A system、search engine、translation system、calendar。
23.3 Toolformer 的训练流程
PPT 给出更形式化的流程。
对输入 \(\mathbf{x}\),采样一个位置 \(i\),以及对应 API call candidates:
然后执行这些 API calls,并过滤掉不能降低未来 token loss \(L_i\) 的调用。
剩下的 API calls 会和原文交织起来,得到新文本:

这一步的直觉是:如果某个工具调用让模型更容易预测后续文本,那么这个调用就可能是有用的训练信号。
24. Gorilla:连接大量 API
PPT 介绍 Gorilla:LLMs connected with massive APIs。
它的训练方式是:
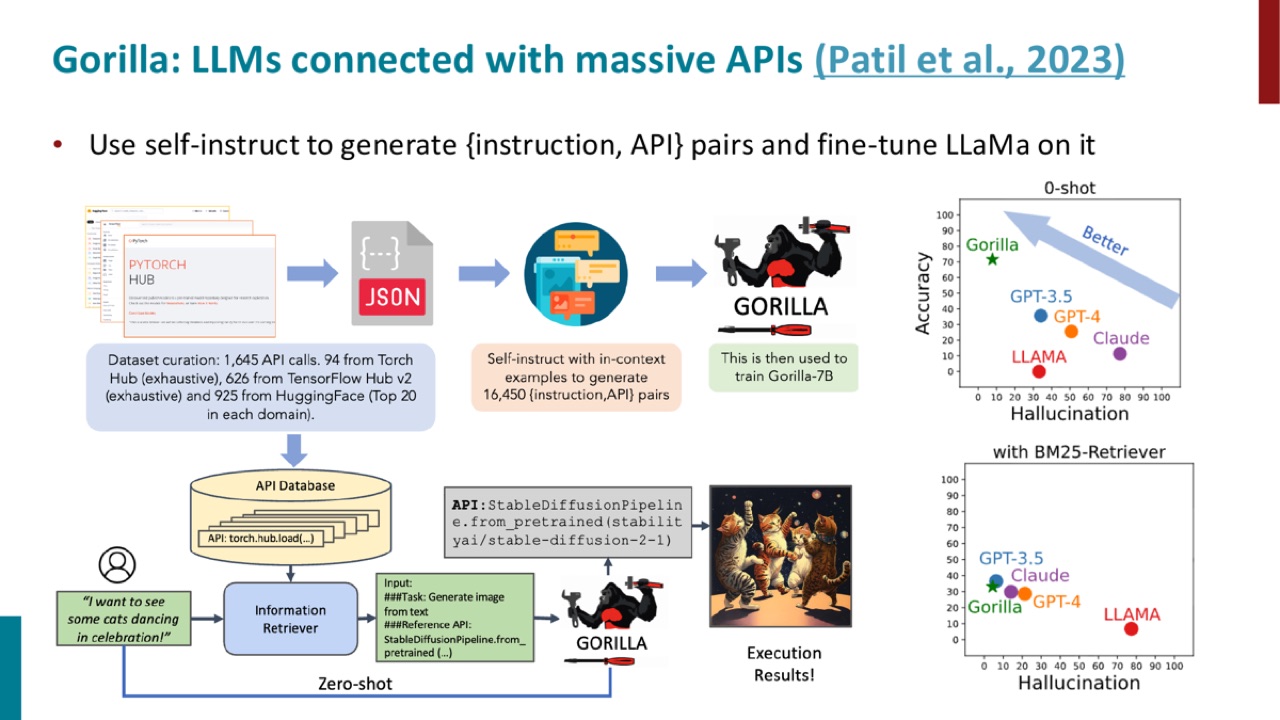
图里展示了一个 API 使用系统:
- 从 Torch Hub、TensorFlow Hub、HuggingFace 等来源整理 API。
- 生成 instruction 和 API 配对数据。
- 用这些数据训练模型。
- 在执行时根据用户请求检索和调用合适 API。
这个例子说明,tool use 不只是“模型会写一段 JSON”。真正难点是:在大量可用 API 中选对 API,写对参数,并把执行结果纳入下一步行为。
25. Agent Applications:环境决定观察和动作
PPT 按 environments and domains 讨论 agent applications。
Digital world 包括:
Physical world 包括 robotics。
25.1 Coding agents
Coding agent 的环境是 project code repos、filesystems、IDEs。
观察空间包括:
动作空间包括:
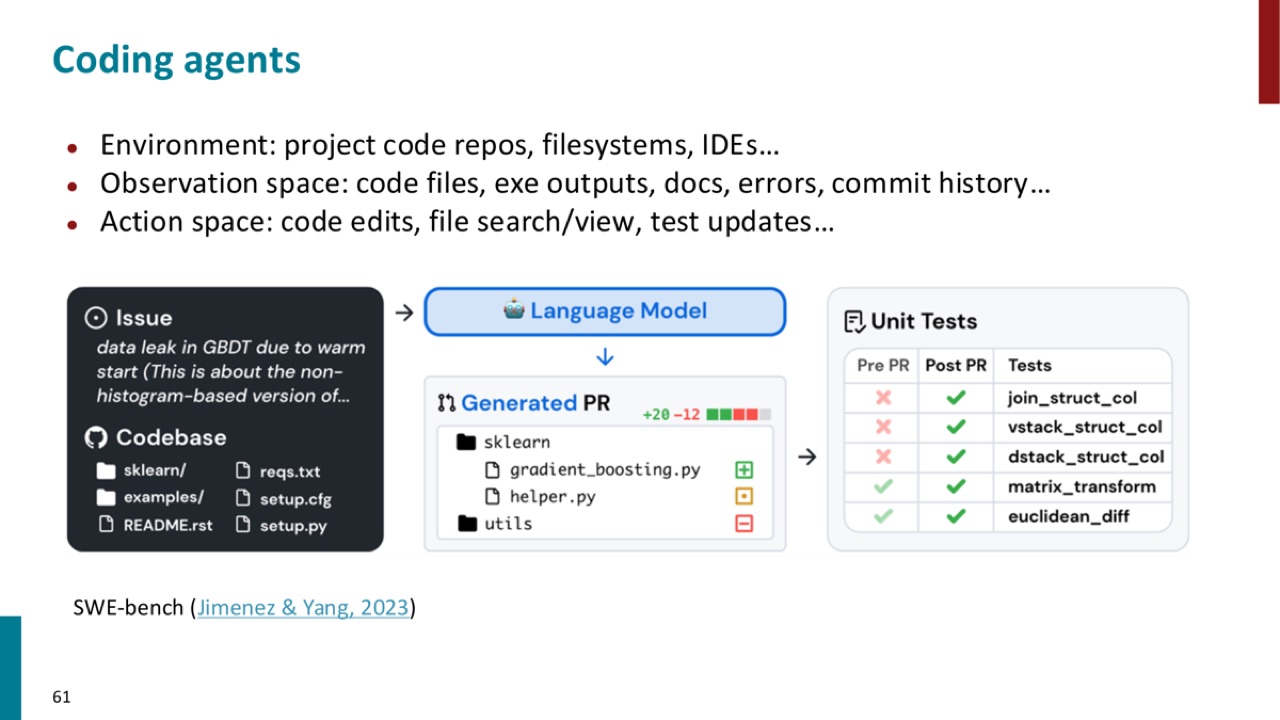
PPT 以 SWE-bench 作为例子。这里要抓住的不是 benchmark 细节,而是 agent 的任务形态:它要在真实代码库中读文件、改代码、跑测试、根据错误继续改。
25.2 Web/app agents
Web/app agents 的环境是 web browsers 或 apps。
观察空间包括:
动作空间包括:
PPT 提到 Mind2Web 和 WebArena,说明研究者会用网页环境来评测 agent 是否能完成真实交互任务。
25.3 Computer use agents
Computer use agents 的环境是 desktop operating systems。
观察空间包括:
动作空间包括 keyboard 和 mouse controls,例如 click、type、drag、shortcuts。
PPT 提到 OpenAI Universe 和 OSWorld。这里的核心是:越接近真实桌面,agent 的任务越开放,评测和安全也越复杂。
26. Agent Data:为什么数据更难规模化
PPT 把 agent data 的规模化分成三类来源。
第一,human demonstrations。
优点是质量高,缺点是:
第二,synthesis/simulation。
PPT 举例:把 online tutorials 转成直接训练 demonstrations,例如 Synatra。
第三,internet-scale data。
PPT 指出,网上有大量视频和数据展示人类如何执行 agent tasks,但它们往往没有 grounded trajectories。也就是说,你能看到人做了什么,却不一定有模型训练所需的结构化观察和动作序列。
26.1 SWE-smith case study
PPT 还展示 SWE-smith:一个用于 coding agents 数据规模化的 toolkit。
它做两件事:
- 创建 execution environments。
- 为 Python GitHub repository 合成成百上千个 task instances。
后续训练细节里,PPT 提到 rejection sampling fine tuning、expert models、student model 和 SWE-agent system。
这说明 agent training 不只需要文本,还需要可执行环境和可验证任务。
27. Agent Evaluation:为什么比 QA 难
普通 QA 常常评一个 final answer。Agent evaluation 要评整个交互过程。

PPT 列出的挑战包括:
- Real-world environmental setup complexity。
- Task coverage。
- Open-ended success criteria。
- Multiple valid solution paths。
- Cannot script evaluation metrics,需要 human judgment。
- Evaluation beyond task success。
27.1 为什么不能只看 task success
一个 agent 可能最终完成任务,但过程有问题:
因此 agent evaluation 需要同时看 final result、trajectory、tool use、environment state 和 safety。
27.2 PPT 给出的评测方式
PPT 列出三类:
这也为下一讲 Benchmarking and Evaluation 铺垫。
28. Bonus:Coding Agent 是一个大循环
PPT 最后 bonus 部分把 coding agent 简化成一个 loop:
再拆成三个函数:
query_lm: 给 messages,返回 LM response
parse_action: 从 LM response 中解析 bash action
execute_action: 执行动作,返回 standard output
这不是在说真实 coding agent 只有这么简单,而是提供了一个最小骨架:language agent 的本质是模型和环境之间的循环。
29. 全讲统一视角
这讲可以用一条线串起来:
Reading comprehension
-> Open-domain QA
-> Retrieval augmentation
-> RAG with generative models
-> Language agents
-> Reasoning, memory, tools, environment
-> Agent data and evaluation
其中每一步都在增加系统的外部连接:
| 阶段 | 模型连接到什么 | 新能力 | 新失败点 |
|---|---|---|---|
| Reading comprehension | 给定文章 | 从文章找答案 | 文章必须已给定 |
| Open-domain QA | 大型文档库 | 自己找证据 | 检索可能失败 |
| RAG | 文档库 + 生成模型 | 可更新、有引用的生成 | 多文档利用和 citation 幻觉 |
| Agent | 环境、工具、记忆 | 执行动作和长期任务 | 轨迹、工具、环境状态都可能出错 |
30. 公式与结构速查
Reading comprehension
Retriever-reader
Dense retrieval score
Agent loop
Toolformer
31. 常见误区
误区一:RAG 等于不会幻觉
不对。RAG 只是引入外部文档。检索错、上下文利用失败、citation 不真实,都可能导致幻觉。
误区二:文档越多越好
不对。PPT 明确展示了 long-context problem。检索更多文档可能提高 recall,但 RAG 性能可能很快饱和。
误区三:citation 看起来存在就可信
不对。PPT 专门讨论 citation hallucination。引用需要检查 precision 和 recall。
误区四:Agent 就是加了工具的 chatbot
不够准确。Agent 的重点是 observation-action loop。工具只是其中一个组件,memory、reasoning、environment interaction 同样重要。
误区五:Context window 就是 memory
不对。PPT 强调 event streams 不可能都放进 context window,即使能放也很难有效注意和消化。Memory 需要写入、检索、压缩和管理。
误区六:Agent 评测只看最终答案
不对。Agent 的动作会改变环境,轨迹也有质量差异。评测要看成功、过程、工具调用、环境状态和安全。
32. 自学路线
如果你是第一次学这一讲,建议按下面顺序复习:
- 先掌握 reading comprehension 和 open-domain QA 的差别。
- 手画 retriever-reader framework,标出 \(\mathcal{D}\)、\(Q\)、\(P_1,\ldots,P_K\)、\(A\)。
- 对比 BM25、DPR、ColBERT,理解 sparse、dense、hybrid retrieval。
- 解释为什么 long-context 不等于能用很多文档。
- 用 precision 和 recall 解释 citation hallucination。
- 画 language agent 组件图:LLM core、reasoning、memory、tools、environment。
- 用 Thought、Act、Observation 写出 ReAct 流程。
- 区分 self-consistency、Reflexion、multi-agent debate、orchestrator。
- 画三类 memory:episodic、semantic、procedural。
- 复述 Toolformer 如何筛选 API calls。
- 最后用 coding agent 或 web agent 说明 environment、observation space、action space。
33. 自测题
- Reading comprehension 和 open-domain QA 的最大区别是什么?
- RAG 为什么比 closed-book LM 更容易更新知识?
- Retriever-reader framework 中 \(K\) 的含义是什么?
- 为什么 retriever 找错会导致 reader 再强也答不出?
- Dense retriever 为什么可以用 dot product 作为 score?
- 为什么检索更多文档后,RAG 性能可能不继续上升?
- Citation precision 和 citation recall 分别检查什么?
- Language agent 和普通 LLM 的区别是什么?
- ReAct 的 Thought、Act、Observation 分别对应什么?
- Self-consistency 为什么要生成多条 reasoning paths?
- Reflexion 怎样利用失败轨迹?
- Episodic memory 和 semantic memory 的差别是什么?
- MemGPT 为什么要读写外部存储?
- Toolformer 是如何筛选有用 API calls 的?
- Coding agent 的 observation space 和 action space 分别包括什么?
- Agent evaluation 为什么常常需要 human judgment?
34. 自测题答案
- Reading comprehension 给定 passage,只需在上下文中找答案;open-domain QA 不给指定 passage,只给大型文档集合,需要先找到答案所在位置。
- RAG 的知识在外部文档库中,可以更新或添加文档,不必把所有知识重新写进模型参数。
- \(K\) 是 retriever 返回的候选 passages 数量,例如 100。
- 因为 reader 只能基于进入上下文的 passages 回答;正确证据没被检索到时,reader 无法读到答案。
- 因为 question 和 passage 都可编码成向量,dot product 衡量二者表示的相似度。
- 无关文档会干扰模型,正确文档的位置会影响注意,长上下文模型也不一定能有效使用全部上下文。
- Precision 看给出的引用是否真的支持说法;recall 看该找出的支持证据是否被找全。
- 普通 LLM 主要预测文本输出;language agent 会观察环境、推理、调用工具或执行动作,并根据新观察继续循环。
- Thought 是内部推理,Act 是工具调用或环境动作,Observation 是环境返回的信息。
- 多条路径可以降低单一路径偶然错误,通过最终答案的一致性进行聚合。
- Reflexion 把失败轨迹压缩成自然语言反思,作为未来决策的 self-hints。
- Episodic memory 存经历或事件;semantic memory 存从事件中抽象出的知识。
- 因为 context window 有限,长期信息需要外部存储和检索,不能只靠一次性上下文。
- 它采样候选 API calls,执行后检查是否降低未来 token loss,只保留有帮助的调用并写回训练文本。
- Coding agent 的 observation space 包括代码文件、执行输出、文档、错误、提交历史;action space 包括代码编辑、文件搜索/查看、测试更新。
- 因为任务路径开放,可能有多个有效解,环境设置复杂,而且很多成功标准无法完全脚本化。