06. 预训练
官方 PPT 来源:第 6 讲官方 PPT
本讲对应 CS224n 第 6 讲 Pretraining。官方文件名里带有 lecture07-pretraining.pdf,但 PPT 首页标注为 Lecture 6: Pretraining;本页按 PPT 首页和课程进度记为第 6 讲。
这一讲回答一个现代 NLP 的核心问题:为什么现在训练 NLP 系统时,通常不是从零训练一个任务模型,而是先在大规模文本上预训练,再对具体任务微调,甚至直接通过 prompt 和上下文示例使用模型?
本讲学习目标
学完这一讲,你应该能从零回答下面这些问题:
- 预训练为什么能改变 NLP 系统的训练方式?
- 为什么大规模预训练通常避免依赖人工标注数据?
- 固定 word-level vocabulary 为什么会遇到 OOV 和 UNK 问题?
- Byte-pair encoding 的基本算法是什么?
- Subword tokenization 为什么能同时照顾常见词和稀有词?
- 传统 pretrained word embeddings 的局限是什么?
- Whole-model pretraining 和只预训练词向量有什么本质区别?
- “重构输入”为什么能教会模型语法、指代、主题、情感等信息?
- Language model pretraining 的目标函数是什么?
- Pretraining / finetuning paradigm 的两步分别做什么?
- 预训练数据来自哪里?PPT 提到了哪些版权和隐私风险?
- Encoder、encoder-decoder、decoder 三种架构的预训练目标为什么不同?
- BERT 为什么用 masked language modeling,而不是普通 left-to-right language modeling?
- BERT 的 15 percent masking、80/10/10 替换策略是什么意思?
- Next sentence prediction 是什么?后续工作为什么认为它不一定必要?
- RoBERTa 和 SpanBERT 分别改了 BERT 的哪部分?
- T5 的 span corruption 是什么?
- Decoder-only 模型如何用于分类任务?如何用于生成任务?
- GPT 的输入格式如何把 NLI 任务变成 decoder 可处理的序列?
- In-context learning 为什么不等于普通 finetuning?
- Scaling laws 在大模型训练里解决什么问题?
- 预训练到底可能学到哪些东西?又可能学到哪些不该学的东西?
PPT 脉络
| 部分 | PPT 内容 | 本讲义对应章节 |
|---|---|---|
| 预训练动机 | pretraining revolution、大规模无监督学习、compute-aware scaling | 1 |
| Subword modeling | 固定词表、UNK、BPE、subword 示例 | 2-4 |
| 从词向量到整模型预训练 | distributional semantics、contextual meaning、pretrained embeddings 的局限、whole-model pretraining | 5-7 |
| 预训练与微调范式 | language modeling pretraining、parameter initialization、数据来源与争议 | 8-10 |
| 三类架构 | encoder、encoder-decoder、decoder 的预训练差异 | 11 |
| Encoder pretraining | BERT、MLM、NSP、BERT 规模、下游任务、局限、RoBERTa、SpanBERT | 12-16 |
| Encoder-decoder pretraining | prefix LM、T5、span corruption、open-domain QA | 17-18 |
| Decoder pretraining | 分类微调、生成微调、GPT、GPT-2、GPT-3、in-context learning | 19-23 |
| Scaling 与预训练学到了什么 | scaling laws、scaling efficiency、语言统计属性、偏见、记忆、membership inference | 24-26 |
1. 预训练革命:NLP 为什么变了?
PPT 一开始强调:
Pretraining has had a major, tangible impact on how well NLP systems work.
中文说就是:预训练不是一个小技巧,而是显著改变 NLP 系统效果的主线方法。
在预训练之前,常见流程是:
问题是:许多 NLP 任务的标注数据都不多。比如情感分类、问答、自然语言推理、语法可接受性判断,每个任务都要人工标注,成本很高。
预训练改变了流程:
它利用的是一个很重要的事实:未标注文本比标注数据多得多。
1.1 预训练的三个关键想法
PPT 列出 key ideas:
- 模型必须能处理 large-scale、diverse datasets。
- 不依赖 labeled data,否则无法规模化。
- 训练时要考虑 compute-aware scaling。
逐个解释:
第一,数据要大且多样。只在一个很小、很窄的数据集上训练,模型学到的是局部写法;大规模、多来源文本能让模型接触更多语法、词义、主题、事实和文本风格。
第二,不能主要依赖标注数据。标注数据需要人类做标签,规模很难上去;无标注文本可以从书、网页、百科、论坛、代码仓库等来源获得。
第三,计算资源不是无限的。预训练模型时,要在参数量、训练 token 数、架构选择和计算预算之间做取舍。
2. 为什么不能只用固定 word vocabulary?
在课程前几讲,我们常常假设有一个固定词表:
这对小模型或传统任务也许可以工作,但对大规模预训练很不够。
PPT 给的例子是:
| 类型 | 词 | 固定词表会怎样 |
|---|---|---|
| 常见词 | hat、learn |
映射到已知 index |
| 变体 | taaaaasty |
可能映射到 UNK |
| 拼写错误 | laern |
可能映射到 UNK |
| 新词 | Transformerify |
可能映射到 UNK |
UNK 的问题非常严重:所有没见过的词都变成同一个符号。
这意味着模型无法区分:
它们在词形、语义暗示、拼写结构上完全不同,但固定词表会把它们压成同一个 UNK。

官方 PPT 截图:固定 word-level vocabulary 会把训练集中没见过的变体、拼写错误、新词都映射到同一个 UNK,信息被直接抹掉。
3. Subword Modeling:在词和字符之间折中
PPT 说,subword modeling 是对 word level 以下结构建模:
现代预训练模型常用的基本思路是:学习一个 subword vocabulary。
训练和测试时,每个词都被拆成已知 subwords 的序列。
这样常见词可以保持整体:
稀有词、新词、变体可以拆开:
这里的 ## 只是示意:这个片段是词内部的一部分,不一定是词开头。
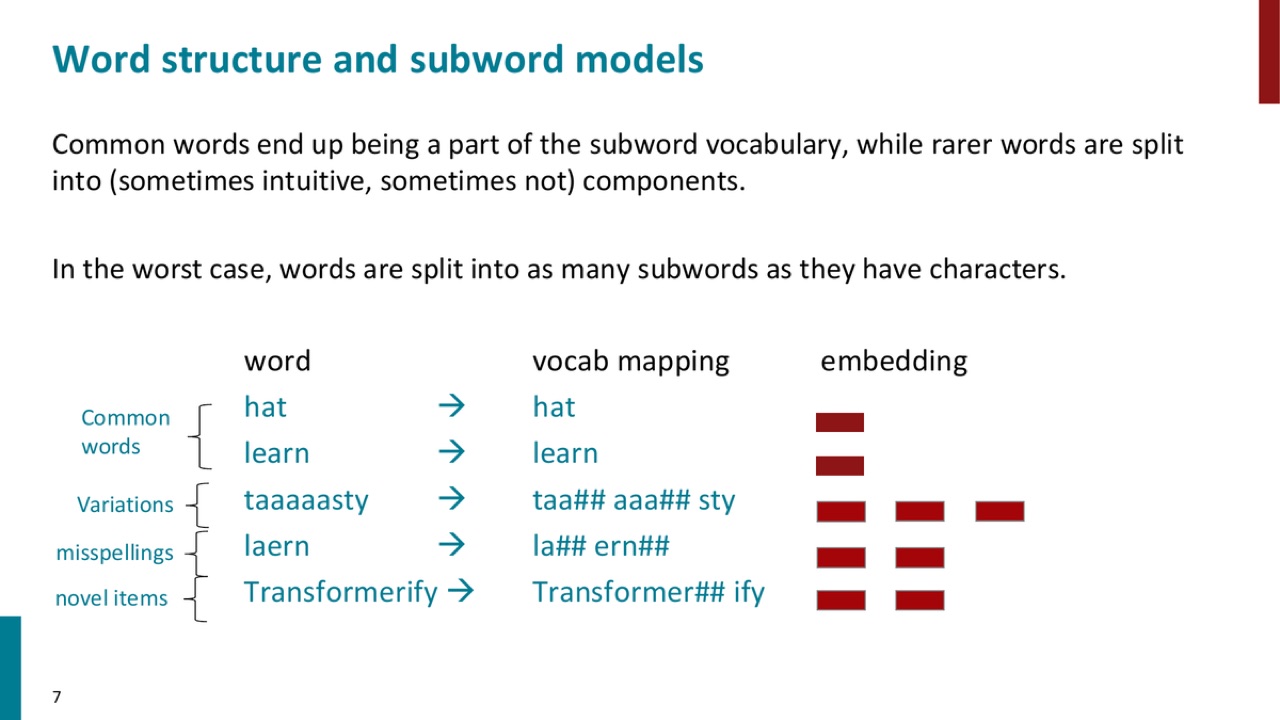
官方 PPT 截图:常见词可以作为完整 subword 出现,稀有词和新词可以拆成多个 subword,最坏情况可以退化到字符级拆分。
3.1 Subword 的好处
Subword modeling 解决了固定词表的核心问题:
- 常见词仍然高效。
- 新词不必全部变成
UNK。 - 模型能看到词内部结构,例如前缀、后缀、拼写相似性。
- 词表大小不会像 word vocabulary 那样无限膨胀。
这就是它适合大规模预训练的原因。
4. Byte-Pair Encoding:怎么学出 subword vocabulary?
PPT 介绍了 byte-pair encoding,也就是 BPE。
BPE 的目标是从语料中自动学出常用 subword。
算法可以这样理解:
- 初始 vocabulary 只包含字符和 end-of-word symbol。
- 在语料中统计最常见的相邻 pair,例如
a,b。 - 把这个 pair 合并成新的 subword,例如
ab。 - 用新 subword 替换语料里的该 pair。
- 重复,直到达到目标词表大小。
一个极简例子:
初始:l o w </w>, l o w e r </w>, n e w e s t </w>
高频 pair:l o
合并:lo
下一轮可能合并:lo w -> low
再下一轮可能合并:e r -> er
最后词表里既有字符,也有常见片段,也可能有完整常见词。
PPT 提到,BPE 最早在 NLP 中用于机器翻译;后来类似方法 WordPiece 被用于 pretrained models。
4.1 初学者最容易误解的点
BPE 不是语言学家手工定义词根词缀。
它是纯数据驱动的:
所以得到的 subword 有时符合直觉,有时不符合直觉。PPT 也特别说:rare words are split into sometimes intuitive, sometimes not components。
5. 从 Distributional Semantics 到 Contextual Meaning
课程前面讲 word2vec 时引用过一句话:
You shall know a word by the company it keeps.
这是 distributional semantics 的核心直觉:词义可以从上下文中学习。
但 PPT 又引用 Firth 1935 的更强说法:
the complete meaning of a word is always contextual.
一个词的完整意义总是上下文化的。
PPT 给出例子:
两个 record 形式相同,但词性和意思不同:
如果使用静态词向量,同一个 record 只有同一个 embedding,无法直接区分这两个语境中的意义。
这正是 whole-model pretraining 出现的重要动机。
6. 只预训练词向量有什么问题?
PPT 回顾了 2017 年左右的做法:
也就是说,只有 embedding 层来自预训练;后面的上下文建模网络仍然大多随机初始化。
这带来两个问题。
6.1 词向量没有上下文
PPT 对 movie 的说明是:
同一个词在所有句子里都是同一个初始向量。
可是 NLP 任务需要的是上下文中的词义。比如:
movie 本身不够,模型还要理解整句语义和情感。
6.2 下游标注数据要教会模型所有上下文能力
如果 LSTM 或 Transformer 随机初始化,那么这些层必须靠下游任务数据学会:
但下游标注数据通常不够大。
7. Whole-Model Pretraining:预训练整个模型
现代 NLP 的做法是:
PPT 说:
All or almost all parameters in NLP networks are initialized via pretraining.
Whole-model pretraining 通常会隐藏输入的一部分,然后训练模型重构被隐藏部分。
这带来三种能力:
- 学到强语言表示。
- 为下游 NLP 模型提供强参数初始化。
- 学到可以采样的语言概率分布。
7.1 “重构输入”为什么不是无聊的填空?
PPT 连续给了几个填空例子。
这可能教模型事实知识。
这可能教模型语法,例如冠词选择。
这可能教模型指代和一致性。
这可能教模型 lexical semantics 或 topic。
Overall, the value I got from the two hours watching it
was the sum total of the popcorn and the drink.
The movie was ___.
这可能教模型情感。
这些例子说明:看似简单的重构任务,会迫使模型学习大量语言统计规律。
8. Language Modeling 形式的预训练
PPT 先从上一讲熟悉的 language modeling 开始。
语言模型目标是:
意思是:给定前面的词,预测当前词的概率分布。
预训练做法:
PPT 用 Iroh goes to make tasty tea 的例子展示:
模型每个位置都根据过去上下文预测下一个 token。
8.1 为什么 language modeling 适合大规模预训练?
因为训练标签来自文本本身。
不需要人工标注:
这就是 self-supervised learning 的典型形式:监督信号从数据自身构造出来。
9. Pretraining / Finetuning Paradigm
PPT 用一张图总结预训练和微调。
第一步:pretrain。
第二步:finetune。
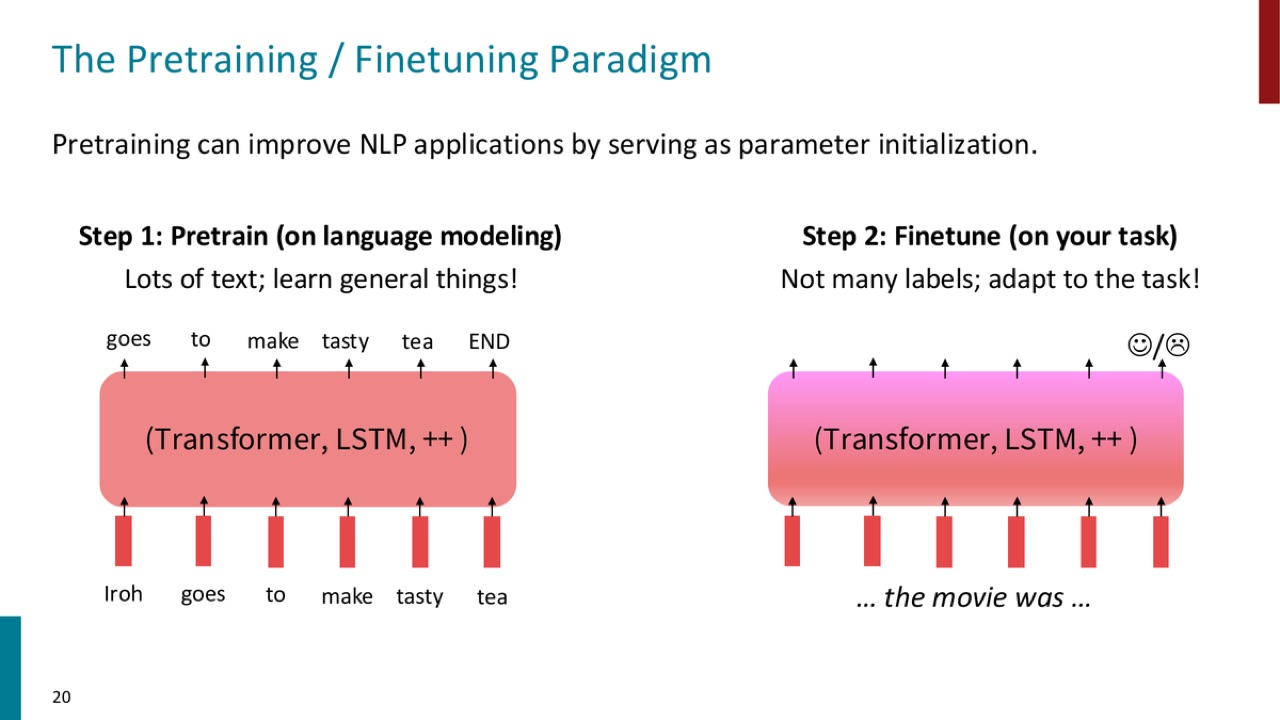
官方 PPT 截图:预训练阶段用大量文本学习一般语言能力;微调阶段用较少任务标签把模型适配到具体任务。
9.1 为什么说预训练是 parameter initialization?
PPT 说:
Pretraining can improve NLP applications by serving as parameter initialization.
这句话很关键。
预训练并不直接完成所有任务。它先把参数放到一个“懂语言”的起点上。
下游任务训练时,不再从随机参数开始,而是从已经学过大量文本统计规律的参数开始。
因此微调所需的数据量更少,训练更稳定,泛化通常更好。
9.2 Finetuning 改的是什么?
微调时通常会:
- 加上任务需要的输出层。
- 用任务标注数据训练。
- 让梯度反传到整个网络,更新预训练参数。
所以微调不是只训练最后一层。PPT 后面讲 decoder 分类微调时也强调:gradients backpropagate through the whole network。
10. 预训练数据来自哪里?
PPT 列出不同模型的数据来源:
| 模型 | PPT 提到的训练数据 |
|---|---|
| BERT | BookCorpus, English Wikipedia |
| GPT-1 | BookCorpus |
| GPT-3 | CommonCrawl, WebText, English Wikipedia, Books 1, Books 2 |
| GPT-3.5+ | Undisclosed |
PPT 接着问:
答案是:
也就是从互联网上抓取的电子书,争议很大。
10.1 数据问题是能力问题,也是风险问题
大规模预训练依赖大规模文本。模型能力来自这些数据,但风险也来自这些数据。
PPT 在数据部分提到 fair use and other concerns,后面又回到 memorization、copyrighted material、semi-private material 等问题。
本讲 PPT 没有展开法律细节,所以这里不额外扩展。需要记住的是:
11. 三类架构,三种预训练问题
PPT 把模型架构分成三类:
- Encoders。
- Encoder-Decoders。
- Decoders。
架构会影响预训练目标和自然使用场景。

官方 PPT 截图:encoder 能获得双向上下文;decoder 是语言模型,适合生成但不能看未来;encoder-decoder 希望结合二者优点。
11.1 Encoder
Encoder 可以看双向上下文。
例如 BERT 处理句子:
每个位置都可以关注左右两边。
优点是表示强,适合理解类任务。
问题是:如果能看未来,就不能直接用普通 left-to-right language modeling 训练。
11.2 Encoder-Decoder
Encoder-decoder 同时有:
适合输入一段文本、输出另一段文本的任务,例如翻译、摘要、问答。
问题是:它应该如何预训练?PPT 后面给出 T5 span corruption。
11.3 Decoder
Decoder 天然适合 language modeling:
优点是生成自然。
限制是不能在预测时直接 condition on future words。
PPT 还特别说:
12. Encoder Pretraining:为什么 BERT 用 Masked LM?
到这里要先理解一个矛盾。
Language modeling 是:
只能看左边过去上下文。
但 encoder 的优势是双向上下文:
如果强行做普通 LM,就浪费了 encoder 的双向能力。
12.1 Masked Language Modeling
PPT 的想法是:
记原句为:
mask 后的句子为:
模型学习:
更具体地,encoder 输出:
对被 mask 的位置,用线性层加 softmax 预测原 token:
训练时只对被 mask 的位置加 loss。
12.2 一个例子
输入:
目标:
因为 encoder 可以看到左右上下文,所以它能用:
推断第一个 mask 可能是动词,用:
推断第二个 mask 可能是地点名词。
13. BERT:Masked LM 的代表模型
BERT 全称是:
PPT 说,Devlin et al., 2018 提出 masked LM objective,并发布了一个 pretrained Transformer 权重,称为 BERT。
13.1 BERT 的 15 percent masking
BERT 随机选择 15 percent 的 subword tokens 作为要预测的位置。
对这些被选中的位置:
- 80 percent 时间替换成
[MASK]。 - 10 percent 时间替换成随机 token。
- 10 percent 时间保持原 token 不变,但仍然要求模型预测它。
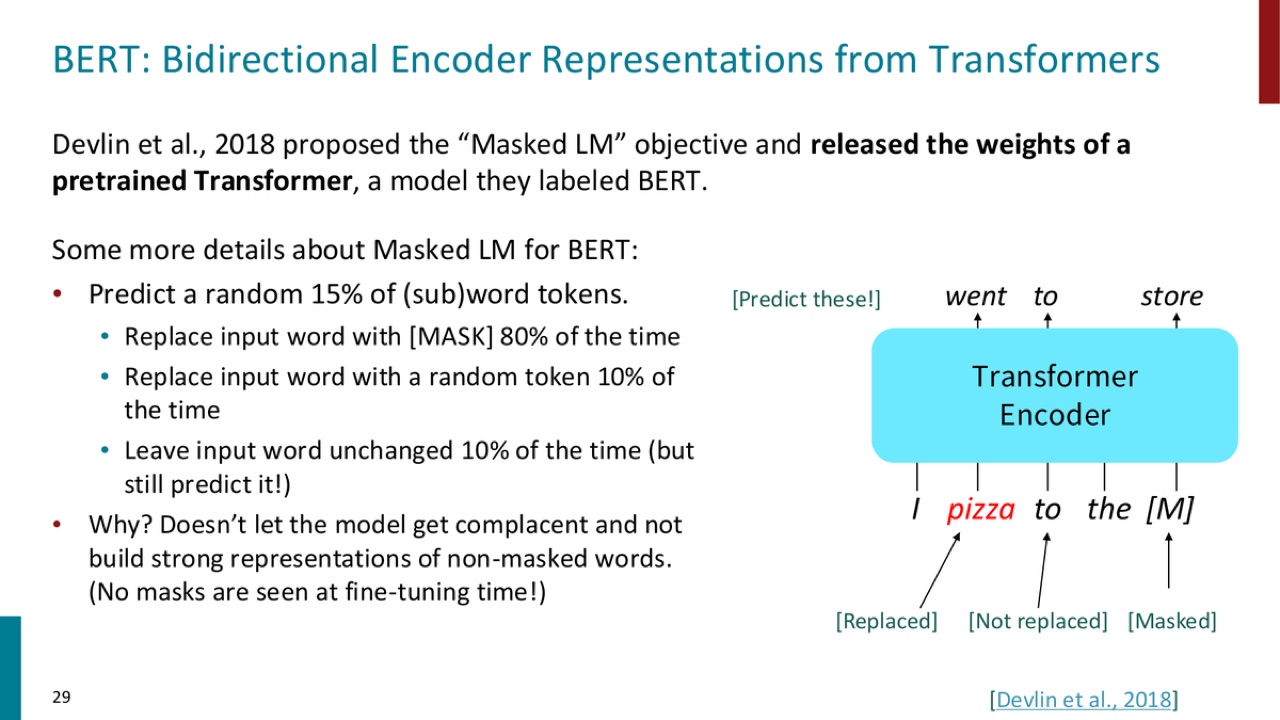
官方 PPT 截图:BERT 不是把所有被预测位置都替换成 [MASK]。有些位置被随机 token 替换,有些保持不变,但这些位置都参与预测 loss。
13.2 为什么要用 80/10/10?
PPT 给出的解释是:
如果预训练时模型总是看到 [MASK] 才预测,它可能过度依赖这个特殊符号。
但微调时下游任务输入通常没有 [MASK]。
所以 BERT 用 80/10/10 让模型不要偷懒:
13.3 Next Sentence Prediction
BERT 预训练输入是两个连续文本片段。
模型还被训练去判断:
这叫 next sentence prediction,简称 NSP。
PPT 也指出:later work has argued this next sentence prediction is not necessary。
也就是说,后续研究认为 NSP 不一定是 BERT 成功的关键。
13.4 BERT 的规模与训练数据
PPT 给出两个模型:
| 模型 | 层数 | hidden size | attention heads | 参数量 |
|---|---|---|---|---|
| BERT-base | 12 | 768 | 12 | 110 million |
| BERT-large | 24 | 1024 | 16 | 340 million |
训练数据:
训练成本:
PPT 的关键总结是:
预训练很贵,但微调相对可行。
13.5 BERT 可以用于哪些任务?
PPT 提到,finetuning BERT 在广泛任务上达到当时新的 state-of-the-art:
| 任务 | 说明 |
|---|---|
| QQP | 判断 Quora 问题对是否是复述 |
| QNLI | 基于问答数据的自然语言推理 |
| SST-2 | 情感分析 |
| CoLA | 判断句子是否语法可接受 |
| STS-B | 语义文本相似度 |
| MRPC | Microsoft paraphrase corpus |
| RTE | 小规模自然语言推理 |
这些任务多数是理解类任务:分类、匹配、判断、相似度。
14. Pretrained Encoders 的局限
PPT 问:
原因是:如果任务涉及生成序列,pretrained decoder 更自然。
BERT 这种 encoder 可以做:
但它不自然地支持:
举例:
BERT 可以预测 mask 位置可能是 make、brew、craft。
但如果要从左到右生成:
decoder 的训练目标和生成过程更一致。
15. BERT 的扩展:RoBERTa 与 SpanBERT
PPT 提到两个常见 BERT 变体。
15.1 RoBERTa
RoBERTa 的一般改进:
PPT 还指出,RoBERTa paper 的一个 takeaway 是:
more compute, more data can improve pretraining
even when not changing the underlying Transformer encoder
这说明模型效果不只由架构决定,训练数据和训练 compute 也非常关键。
15.2 SpanBERT
SpanBERT 的核心是 masking contiguous spans of words。
普通 BERT 可能 mask 分散 token:
SpanBERT 会 mask 连续片段:
PPT 说,这会构造更难、更有用的预训练任务。
直觉上,连续 span 被删掉时,模型不能只靠局部碎片猜词,而要更强地使用上下文。
16. Encoder-Decoder Pretraining:先读,再生成
Encoder-decoder 的目标是结合 encoder 和 decoder 的优点:
PPT 先给了一个类似 language modeling 的想法:
- 把输入前缀 \(w_1,\ldots,w_T\) 给 encoder。
- encoder 得到:
- decoder 继续预测后续 token。
PPT 的意思是:encoder 部分从 bidirectional context 获益,decoder 部分通过 language modeling 训练整个模型。
17. T5:Span Corruption
PPT 接着说,Raffel et al., 2018 发现效果最好的是 span corruption。对应模型是 T5。
做法:
- 从输入中替换不同长度的 spans。
- 每个被替换 span 用一个 unique placeholder 表示,例如
<X>、<Y>。 - decoder 输出被删除的 spans。
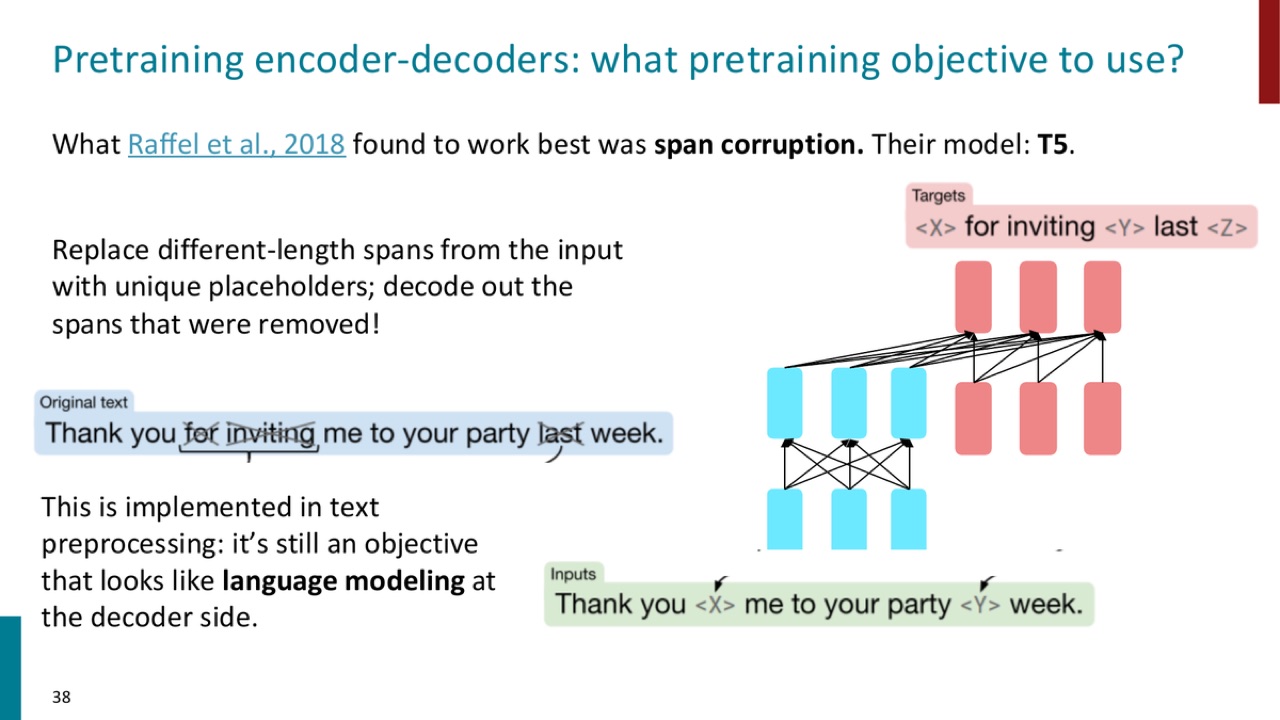
官方 PPT 截图:T5 把输入中的连续片段替换成不同 placeholder,然后让 decoder 生成被移除的片段。PPT 强调它在 decoder 侧仍然像 language modeling。
17.1 一个具体例子
原文:
span corruption 后可能变成:
目标输出类似:
重点不是这些符号本身,而是任务结构:
17.2 T5 的一个有趣性质
PPT 提到 T5 可以被 finetuned 去回答多种问题,并从自身参数中检索知识。
PPT 列出的 open-domain 任务包括:
并展示了不同参数规模:
18. Decoder Pretraining:最自然的语言模型路线
Decoder-only 模型天然适合语言建模:
因为 decoder 本来就通过 causal mask 只能看过去。
PPT 在 decoder 部分讲了两种使用方式:
- 把 pretrained decoder 用于分类。
- 把 pretrained decoder 用于生成。
19. 用 Decoder 做分类:最后一个 hidden state
假设输入为:
decoder 输出:
做分类时,可以取最后一个 hidden state:
再加一个任务特定线性层:
这里 \(A\) 和 \(b\) 是随机初始化的,由下游任务学习。
PPT 特别说明:
但整个网络会一起反向传播:
所以 decoder 的预训练参数也会被微调。
20. 用 Decoder 做生成:输出层也已经预训练
如果任务本身输出的是文本序列,decoder 预训练就更自然。
例如:
训练和生成都可以沿用 language modeling 形式:
PPT 在这里强调一个区别:
因为预训练 LM 本来就学习了从 hidden state 到下一个 token 分布的映射。
21. GPT:Generative Pretrained Transformer
PPT 介绍 2018 年的 GPT。
关键配置:
Transformer decoder
12 layers
117M parameters
768-dimensional hidden states
3072-dimensional feed-forward hidden layers
Byte-pair encoding with 40,000 merges
训练数据:
PPT 说,这些书包含 long spans of contiguous text,有助于学习 long-distance dependencies。
21.1 GPT 如何处理 NLI 这种分类任务?
Natural Language Inference 的任务是判断两个句子的关系:
Premise: The man is in the doorway
Hypothesis: The person is near the door
Label: entailment / contradictory / neutral
GPT 是 decoder,它吃的是 token 序列。
Radford et al., 2018 的格式大致是:
然后在 [EXTRACT] token 的 representation 上接线性分类器。
这说明:很多非生成任务也可以被格式化成 decoder 能处理的序列输入。
21.2 GPT-2
PPT 说,GPT-2 是更大的 GPT,规模为 1.5B,并在更多数据上训练。
它展示了 pretrained decoders 可以产生 relatively convincing samples of natural language。
22. GPT-3 与 In-Context Learning
PPT 说,到目前为止,我们通常用 pretrained models 的两种方式:
- 从它定义的分布中采样,也许提供 prompt。
- 在关心的任务上微调,然后取预测。
但 very large language models 展现出另一种现象:
这就是 in-context learning。
GPT-3 是 PPT 中的 canonical example。
PPT 对比了参数量:
22.1 In-context learning 的例子
PPT 里的翻译示例:
模型条件生成:

官方 PPT 截图:in-context examples 在同一个 decoder context 里指定任务,模型不经过梯度更新,而是基于条件分布继续生成。
22.2 它和 finetuning 的区别
Finetuning:
In-context learning:
PPT 的措辞很谨慎:
也就是说,本讲不是在断言它和人类学习一样,而是在描述一个经验现象。
23. 为什么要 Scaling?
PPT 进入 scaling laws。
第一条经验观察:
模型变大通常能让 perplexity 改善。
但这不是一句“模型越大越好”就结束了。
真正的问题是:
PPT 还说,现代做法常常是:
也就是不要只看模型是否把训练数据跑到完全收敛,还要看计算预算下怎样最有效。
24. Scaling Efficiency:参数量和 token 数的权衡
PPT 以 GPT-3 和 Chinchilla 为例。
GPT-3:
训练 large Transformer 的成本粗略按:
PPT 问:
答案是:

官方 PPT 截图:PPT 用 Chinchilla 说明,较小的 70B 参数模型如果训练 token 更多,可能优于参数更多但训练 token 较少的模型。
24.1 初学者该怎么理解这件事?
训练效果不只看参数量:
Scaling laws 的价值是让研究者能预测:
PPT 还说,可预测的 scaling 能帮助我们对 architecture decisions 做更聪明的选择。
25. 预训练到底教会了模型什么?
PPT 最后一部分回到开头那些填空例子,并归纳模型可能学到的内容。
| 例子 | 可能学习到的东西 |
|---|---|
Stanford University is located in ___, California. |
Trivia |
I put ___ fork down on the table. |
Syntax |
checking for traffic over ___ shoulder |
Coreference |
fish, turtles, seals, and ___ |
Lexical semantics / topic |
The movie was ___. |
Sentiment |
Zuko left the ___. |
Some reasoning, harder |
1, 1, 2, 3, 5, 8, 13, 21, ___ |
Some basic arithmetic, not necessarily Fibonacci rule |
PPT 的重要态度是:预训练确实能学到语言统计属性,但不要把它神秘化。
例如 Fibonacci 例子旁边写的是:
也就是说,模型可能学到某些模式,但这不等于它真正掌握了完整数学概念。
26. 预训练也可能学到不该学的东西
PPT 明确提醒:
它还提到:
以及:
有些训练数据可能是 semi-private material from the web,例如:
这部分要和第 10 节的数据来源一起理解。
预训练把互联网文本的统计规律吸收到模型参数中;这些规律包括有用语言能力,也包括偏见、版权内容和隐私风险。
27. 三种架构的学习对照表
| 架构 | 能看到什么上下文 | 常见预训练目标 | 自然强项 | 主要限制 |
|---|---|---|---|---|
| Encoder | 双向上下文 | Masked LM | 理解、分类、匹配、抽取 | 不自然做自回归生成 |
| Encoder-Decoder | encoder 双向,decoder 自回归 | Span corruption / denoising | 输入到输出的生成任务 | 结构更复杂 |
| Decoder | 过去上下文 | Language modeling | 生成、prompt、in-context learning | 不能直接看未来 |
27.1 怎么记?
一句话:
28. 公式小抄
28.1 Language Modeling
给定过去 token,预测下一个 token。
28.2 Masked Language Modeling
只对被 mask 的 token 位置计算 loss。
28.3 Masked 输入到原输入
\(\tilde{x}\) 是被 mask 或破坏后的输入。
28.4 Decoder 分类微调
用最后一个 hidden state 做分类。
28.5 大模型训练成本粗略关系
PPT 用这个关系引出 scaling efficiency。
29. 常见误区
29.1 误区:预训练就是把知识库背下来
不是。
PPT 的例子说明模型会学到很多统计属性,包括 trivia、syntax、coreference、sentiment 等。
但 PPT 也提醒模型会 memorization。这意味着:
它包含模式学习,也可能包含记忆。
29.2 误区:BERT 和 GPT 只是名字不同
不是。
BERT 是 encoder-only,训练目标主要是 masked LM。
GPT 是 decoder-only,训练目标是 left-to-right language modeling。
这导致它们自然适合不同任务。
29.3 误区:Masked LM 就是普通填空题
Masked LM 看起来像填空,但训练目标更系统:
BERT 的 80/10/10 替换策略也说明它不只是简单把词换成 [MASK]。
29.4 误区:In-context learning 会更新模型参数
不会。
PPT 强调它是 without gradient steps。
上下文示例改变的是条件输入,不是模型参数。
29.5 误区:模型越大一定越好
PPT 的 scaling efficiency 部分正是在纠正这个想法。
参数量、token 数和 compute 要一起考虑。
30. 自学路线
如果你是第一次学预训练,建议按下面顺序复习:
- 先理解固定词表为什么会出现
UNK。 - 再理解 BPE 如何把词拆成 subwords。
- 回忆 word2vec 的 distributional semantics,然后问:为什么静态词向量不够?
- 理解 whole-model pretraining:隐藏输入的一部分,再训练模型重构。
- 学会区分 encoder、encoder-decoder、decoder。
- 用 BERT 掌握 masked LM。
- 用 T5 掌握 span corruption。
- 用 GPT 掌握 decoder LM 与 in-context learning。
- 最后把 scaling laws 和数据风险接上。
31. 自测题
- 为什么预训练通常尽量使用无标注数据?
- 固定 word vocabulary 为什么会导致
UNK问题? - BPE 的基本步骤是什么?
- Subword tokenization 为什么能处理
Transformerify这样的新词? - 为什么静态 word embeddings 不能表示
I record the record中两个record的差别? - Whole-model pretraining 相比 pretrained word embeddings 多预训练了什么?
- Language modeling 预训练的目标是什么?
- Pretraining / finetuning paradigm 中,pretraining 和 finetuning 分别解决什么问题?
- Encoder 为什么不能直接使用普通 left-to-right language modeling 作为最佳预训练目标?
- BERT 的 masked LM 只在哪些位置计算 loss?
- BERT 的 80/10/10 masking 策略为什么存在?
- NSP 是什么?PPT 对后续工作的评价是什么?
- RoBERTa 和 SpanBERT 分别改变了什么?
- T5 的 span corruption 如何构造输入和输出?
- Decoder-only 模型做分类时,为什么最后的线性层通常需要从零学?
- Decoder-only 模型做生成时,为什么输出层已经预训练过?
- GPT 的 NLI 输入格式中
[EXTRACT]有什么用? - In-context learning 和 finetuning 的区别是什么?
- Scaling efficiency 为什么不能只看参数量?
- 预训练可能学到哪些不希望模型学到的内容?
32. 自测题答案
- 因为无标注文本规模远大于人工标注数据,可以从数据自身构造监督信号,例如预测下一个 token 或预测被 mask 的 token。
- 测试时没见过的新词、变体、拼写错误都会被映射成同一个
UNK,模型无法区分它们的内部结构和语义线索。 - 从字符和词尾符号开始,反复统计最常见相邻 pair,把它合并成新 subword,并替换语料中的对应 pair,直到达到目标词表大小。
- 因为新词可以拆成已知 subwords,例如
Transformer## ify。即使整体没见过,组成片段仍可能有表示。 - 静态词向量给同一个词形一个固定 embedding;两个
record的词性和语义依赖上下文,固定 embedding 无法直接区分。 - 它不仅预训练 embedding 层,还预训练 Transformer 或其他上下文网络的几乎全部参数。
- 给定过去 token \(w_{1:t-1}\),预测当前 token \(w_t\),即学习 \(p_{\theta}(w_t \mid w_{1:t-1})\)。
- Pretraining 用大量文本学习通用语言能力和参数初始化;finetuning 用较少任务标签把模型适配到具体任务。
- Encoder 能看双向上下文,普通 left-to-right LM 只用过去上下文,不能充分利用 encoder 的优势。
- 只在被选中并需要预测的 masked-out token 位置计算 loss。
- 因为微调时没有
[MASK],所以不能让模型只依赖[MASK];随机替换和保持不变迫使模型为普通 token 也构造强表示。 - NSP 判断两个文本片段是否连续;PPT 指出后续工作认为 NSP 不一定必要。
- RoBERTa 主要训练更久并移除 NSP;SpanBERT mask 连续词片段,构造更难的预训练任务。
- 输入中不同长度的 span 被 unique placeholders 替换,decoder 输出被删除的 spans。
- 分类任务的 label space 是下游任务特定的,新加线性层 \(A,b\) 没有在 LM 预训练中学过。
- 生成任务仍然预测下一个 token,LM 的输出层 \(A,b\) 已经在预训练中学过从 hidden state 到 token 分布的映射。
[EXTRACT]是用于承载整个输入序列最终分类 representation 的位置,线性分类器作用在它的表示上。- Finetuning 会计算 loss 并更新参数;in-context learning 只把示例放入上下文,不做梯度更新。
- 训练成本粗略随 parameters × tokens 变化。较小模型配更多训练 token 可能优于更大但训练不足的模型。
- 偏见,例如 racism、sexism;copyrighted material;semi-private material,例如地址和邮箱;以及可能通过 membership inference 暴露训练数据片段。