07. 后训练
官方 PPT 来源:第 7 讲官方 PPT
本讲对应 CS224n 第 7 讲 Post-training。官方文件名里带有 lecture08-posttraining.pdf,但 PPT 首页标注为 Lecture 7: Post-training;本页按 PPT 首页和课程进度记为第 7 讲。
第 6 讲讲的是预训练:用大规模文本训练语言模型,让模型学到语言分布、知识、语法、主题和一些推理模式。本讲进入后训练:预训练模型已经会预测下一个 token,但我们希望它成为能听懂指令、满足人类偏好、少说废话、少胡编、能对话的助手。这里的核心问题是:language modeling 不等于 assisting users。
本讲学习目标
学完这一讲,你应该能从零回答下面这些问题:
- 为什么模型变大、数据变多之后,仍然不自动等于好助手?
- Language modeling 和 assisting users 的目标差异是什么?
- Instruction fine-tuning 的训练数据长什么样?
- 为什么 instruction fine-tuning 要跨很多任务收集 instruction-output pairs?
- MMLU、BIG-Bench 这类 benchmark 在本讲中承担什么角色?
- 为什么 Flan-T5 说明 instruction tuning 的收益会随模型大小变化?
- Instruction fine-tuning 有哪些明显和隐蔽的局限?
- 为什么 open-ended generation 没有唯一 ground truth?
- 为什么 token-level LM loss 和“满足人类偏好”不一致?
- RLHF 想优化的 expected reward 是什么?
- Policy gradient / REINFORCE 如何把不可微 reward 纳入优化?
- PPO 为什么要限制 policy 每次更新的变化幅度?
- 为什么直接让人类给 reward 很贵、不稳定?
- Reward model 是怎么从 pairwise comparisons 学出来的?
- Bradley-Terry preference model 在 reward modeling 里做什么?
- RLHF pipeline 的三步分别是什么?
- RLHF 中为什么要用 KL penalty 限制模型偏离预训练模型?
- InstructGPT 和 ChatGPT 在本讲中的意义是什么?
- Reward hacking 和 reward model over-optimization 为什么危险?
- PPO 在 RLHF 工程上为什么复杂?
- DPO 为什么被称为 removing the RL from RLHF?
- DPO loss 如何利用 winner / loser 偏好样本?
- GRPO 相比 PPO 简化了什么?
- Human preference labels 的来源和偏差风险是什么?
- AI feedback 能缓解什么问题,又会留下什么问题?
PPT 脉络
| 部分 | PPT 内容 | 本讲义对应章节 |
|---|---|---|
| 语言模型到助手 | 模型变大、训练 token 变多、world models、多任务助手、LM 不等于 user assistant | 1-3 |
| Instruction fine-tuning | 多任务 instruction-output pairs、unseen tasks、Super-NaturalInstructions、MMLU、BIG-Bench、Flan-T5 | 4-8 |
| Instruction tuning 的局限 | ground-truth 数据昂贵、开放式生成无唯一答案、token-level loss 与偏好不一致 | 9 |
| RLHF 动机 | 人类 reward、expected reward、policy gradient、REINFORCE、PPO | 10-14 |
| Reward modeling | 人类偏好昂贵、评分噪声、pairwise comparison、Bradley-Terry、reward model 评估 | 15-17 |
| RLHF pipeline | instruction tuning、comparison data、reward model、RL optimization、KL penalty、RLHF gains | 18-19 |
| InstructGPT / ChatGPT | 大规模任务上的 RLHF、对话助手、行为风格变化 | 20 |
| RL 与 reward modeling 的限制 | reward hacking、hallucination、reward model over-optimization | 21 |
| DPO 与 GRPO | PPO 复杂、closed-form reward、DPO loss、open-source DPO、GRPO | 22-26 |
| 偏好数据 | 低薪标注、annotator bias、preference tuning 的 unintended impact、AI feedback | 27-29 |
1. 从预训练模型到用户助手,中间缺什么?
PPT 一开始展示两个趋势:
模型越来越大,训练 token 越来越多。看起来它们可以做很多事:Bing、ChatGPT、Claude、Khan Academy tutor、GitHub Copilot 都被 PPT 当作例子,说明 language models 正在表现得像 world models 或 multitask assistants。
但本讲马上提出关键问题:
也就是:从“填空式语言建模”到“能帮助用户完成任务的助手”,中间不是自然发生的。
1.1 Language modeling 的目标
语言模型预训练目标是预测文本分布:
它学习的是:
这个目标很强,但它不是:
1.2 Assisting users 的目标
用户想要的助手,至少要做到:
PPT 用一句话概括:
这就是后训练的起点。
2. Post-training 在整条训练链路中的位置
第 6 讲已经讲过 pretraining / finetuning paradigm:
Step 1: Pretrain on language modeling
大量文本,学习 general things
Step 2: Finetune on your task
较少标签,适配具体任务
本讲把第二步扩展为更大的后训练阶段:
如果用一句话记:
这句话只是帮助记忆,具体机制要看后面。
3. 为什么普通 LM 不自动对齐用户意图?
PPT 引用 Ouyang et al., 2022:
一个普通语言模型看到用户输入时,可能只是继续写训练语料中常见的文本,而不是执行任务。
例如用户给出一段文本,希望模型总结。普通 LM 可能继续扩写故事、模仿网页格式,或者生成看似相关但并不是用户要的输出。
所以本讲的第一步是:
也就是先通过 instruction fine-tuning 让模型学会“输入是指令,输出应该是任务答案”。
4. Instruction Fine-Tuning:把模型教成会执行指令
PPT 对 instruction fine-tuning 的定义很直接:
训练数据形如:
Instruction: Please answer the following question.
Input: What is the boiling point of Nitrogen?
Output: -320.4F
或者:
Instruction: Answer the following question by reasoning step-by-step.
Input: The cafeteria had 23 apples...
Output: The cafeteria had 23 apples originally...
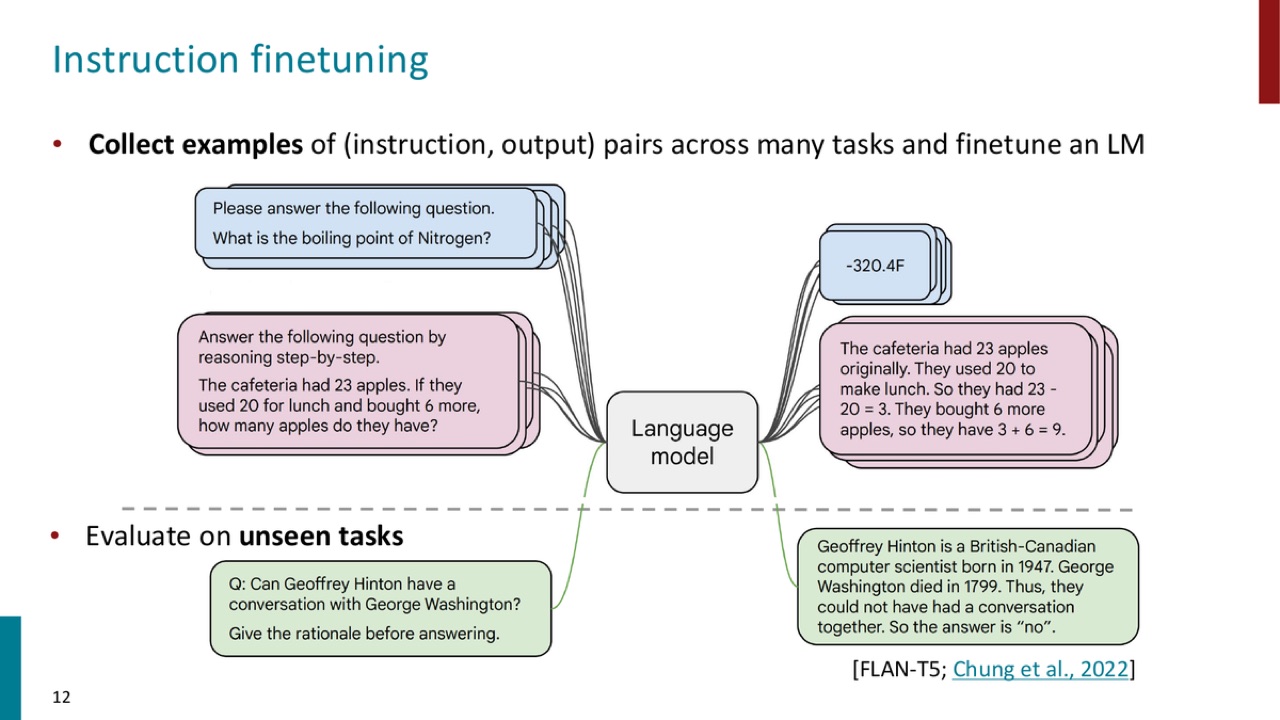
官方 PPT 截图:instruction fine-tuning 使用多任务的 instruction-output pairs 微调语言模型,并在未见过的任务上评估模型是否学会了跟随指令。
4.1 为什么要 across many tasks?
如果只在一个任务上微调,例如只做情感分类,模型学到的是这个任务格式。
Instruction tuning 希望模型学到更抽象的能力:
所以数据要覆盖很多任务:
PPT 提到 Super-NaturalInstructions dataset:
这说明 instruction tuning 已经不是“给模型几条 prompt”,而是一个大规模多任务监督学习问题。
5. 怎么评估 Instruction-Tuned Model?
PPT 问:
如果模型要做许多 unseen tasks,评估也不能只看单一任务。
PPT 引入两个多任务 benchmark。
5.1 MMLU
MMLU 是 Massive Multitask Language Understanding。
PPT 说它用于测量 LM 在 57 个 diverse knowledge intensive tasks 上的表现。
重点不是背每个任务,而是理解它的用途:
PPT 展示了 MMLU 上快速而显著的进展。
5.2 BIG-Bench
BIG-Bench 包含 200+ tasks。
PPT 把它作为另一个衡量 multitask LMs 的 benchmark。
在本讲语境里,MMLU 和 BIG-Bench 的共同作用是:
6. Flan-T5:Instruction Tuning 的性能收益
PPT 用 Flan-T5 展示 instruction fine-tuning 的性能收益。
背景:
Flan-T5 是在额外 1.8K tasks 上 fine-tune 的 T5。
PPT 表格展示了 BIG-Bench + MMLU 的 normalized average:
T5-Small -> Flan-T5-Small: improvement +6.1
T5-Base -> Flan-T5-Base: improvement +11.6
T5-Large -> Flan-T5-Large: improvement +18.8
T5-XXL -> Flan-T5-XXL: improvement +26.6

官方 PPT 截图:Flan-T5 在额外 instruction tasks 上微调后,在 BIG-Bench + MMLU 上明显提升;PPT 强调 bigger model = bigger improvement。
6.1 初学者该看出什么?
这张图说明两件事。
第一,instruction tuning 不是只改变输出风格,它会影响 benchmark performance。
第二,数据和模型规模很关键。PPT 在前一页也说:
较大模型从 instruction tuning 中得到的增益更大。
7. Instruction Tuning 数据怎么来?
PPT 说,LLaMA 的发布带来了开源社区尝试创建 instruction tuning data。
一种方式是让 LM 生成:
PPT 提到 Alpaca:
PPT 还提到 LIMA 的观点:
这不是说数据不重要,而是说在某些条件下,少量高质量 instruction examples 也可能产生明显效果。
8. Instruction Fine-Tuning 学到了什么?
从 PPT 的例子看,instruction tuning 主要把模型从:
推向:
它改变模型面对输入时的默认行为:
但它还没有解决全部问题。下一部分就是它的局限。
9. Instruction Fine-Tuning 的局限
PPT 先给出 obvious limitation:
为每个任务收集标准答案很贵。
但还有更隐蔽的问题。

官方 PPT 截图:instruction fine-tuning 仍然面临开放式生成无唯一正确答案、token-level loss 与人类偏好不一致等问题。
9.1 开放式生成没有唯一正确答案
PPT 给的例子:
这种任务没有单一 ground truth。
两个故事都可能好:
不能像分类任务那样简单比较 token 是否等于标准答案。
9.2 Token-level loss 不知道错误严重性
PPT 说:
language modeling penalizes all token-level mistakes equally,
but some errors are worse than others.
也就是说,普通 LM loss 在 token 层面惩罚错误,但用户关心的是整体回答质量。
例如:
这些在人类眼中严重程度完全不同,但 token-level 目标并不直接表达这种差异。
9.3 核心 mismatch
PPT 总结:
Even with instruction finetuning,
there is a mismatch between the LM objective
and the objective of "satisfy human preferences".
这就是 RLHF 和 preference optimization 出现的动机。
10. 优化人类偏好:从 reward 开始
PPT 以 summarization 为例。
假设同一个原文有两个摘要:
s1: An earthquake hit San Francisco...
s2: The Bay Area has good weather but is prone to earthquakes and wildfires.
如果人类能给每个摘要一个 reward:
那我们就希望模型更常生成高 reward 的摘要。

官方 PPT 截图:如果能给每个模型样本一个人类 reward,就可以把“偏好”变成优化目标。
10.1 Expected Reward 目标
PPT 写出目标:
意思是:
对于单个 prompt,目标是让模型输出分布更偏向高 reward 样本。实际训练中会对许多 prompts 取平均。
11. 为什么这变成 Reinforcement Learning?
我们想更新模型参数:
这里有两个困难。
第一,样本 \(\hat{s}\) 是离散文本,不能像普通神经网络中间层那样直接对 token 采样过程求导。
第二,reward 可能不可微。例如人类判断、比较排序、规则打分都不是可微函数。
PPT 因此引入 policy gradient methods,特别是 REINFORCE。
12. Policy Gradient / REINFORCE 的核心推导
PPT 先写:
因为 \(R(s)\) 不依赖 \(\theta\),所以:
关键技巧是 log-derivative trick:
所以:
代回去:
这又是一个 expectation:
12.1 这条公式的直觉
如果某个样本 reward 高,就增加它的 log probability。
如果某个样本 reward 低,就降低它的 log probability。
这就是 PPT 说的:
12.2 Monte Carlo 近似
无法枚举所有 \(s\),所以采样 \(m\) 个样本:
于是更新:
PPT 也提醒:这是 heavily simplified,真正做 RL with LMs 还需要更多东西。
13. PPO:为什么要限制更新幅度?
Vanilla REINFORCE 有很多问题。PPT 列出:
PPO 的核心思想:
也就是不要让模型一次更新后输出分布变化太大。

官方 PPT 截图:PPO 用 probability ratio 和 clipped objective 限制 policy 每次更新的幅度,降低训练不稳定性。
13.1 Probability Ratio
PPT 定义:
它表示:
如果 ratio 太大或太小,说明更新幅度过大。
13.2 Advantage
PPT 说:
直觉:
PPO 用 clipped objective 把更新限制在一个范围内,例如 clip range 0.2。
14. 直接问人类 reward 为什么不现实?
到目前为止,我们假设有一个 reward function \(R(s)\)。
但实际中,人类不可能每次模型采样都在线打分。PPT 写:
解决方法是:
也就是训练一个 reward model。
15. Reward Model:从人类偏好数据学习 reward
Reward model 记作:
它输入模型输出 \(s\),输出一个 scalar reward。
训练数据来自人类标注的偏好。
PPT 先指出另一个问题:
直接让人给分可能不稳定:
所以 PPT 采用 pairwise comparisons:
16. Bradley-Terry Preference Model
PPT 用 Bradley-Terry paired comparison model 建模偏好。
给定一对样本:
我们希望 reward model 给 winner 更高分:
训练 loss 是:
这里 \(\sigma\) 是 sigmoid。

官方 PPT 截图:人类给出 pairwise preference,reward model 学习让 winning sample 的分数高于 losing sample。
16.1 为什么用差值?
Bradley-Terry 模型关心的是:
所以它使用:
如果这个差值很大,sigmoid 接近 1,表示模型相信 \(s_w\) 更好。
如果差值很小甚至为负,loss 会变大,推动 reward model 调整。
17. Reward Model 也要先验证
PPT 强调:
做法是评估 reward model 是否能预测 held-out human judgments。
PPT 展示的结果说明:足够大的 reward model,加上足够多数据,可以接近 single human performance。
这一步很重要,因为 RLHF 后续会优化 reward model 的分数。
如果 reward model 不可靠,语言模型会被训练去迎合错误目标。
18. RLHF:把所有东西放在一起
PPT 总结 RLHF 需要三样东西:
- 一个 pretrained,可能已经 instruction-finetuned 的 LM。
- 一个 reward model \(RM_{\phi}(s)\),由 human comparisons 训练,给输出标量 reward。
- 一个能优化任意 reward function 的 RL 方法。
18.1 RLHF 的三步 pipeline
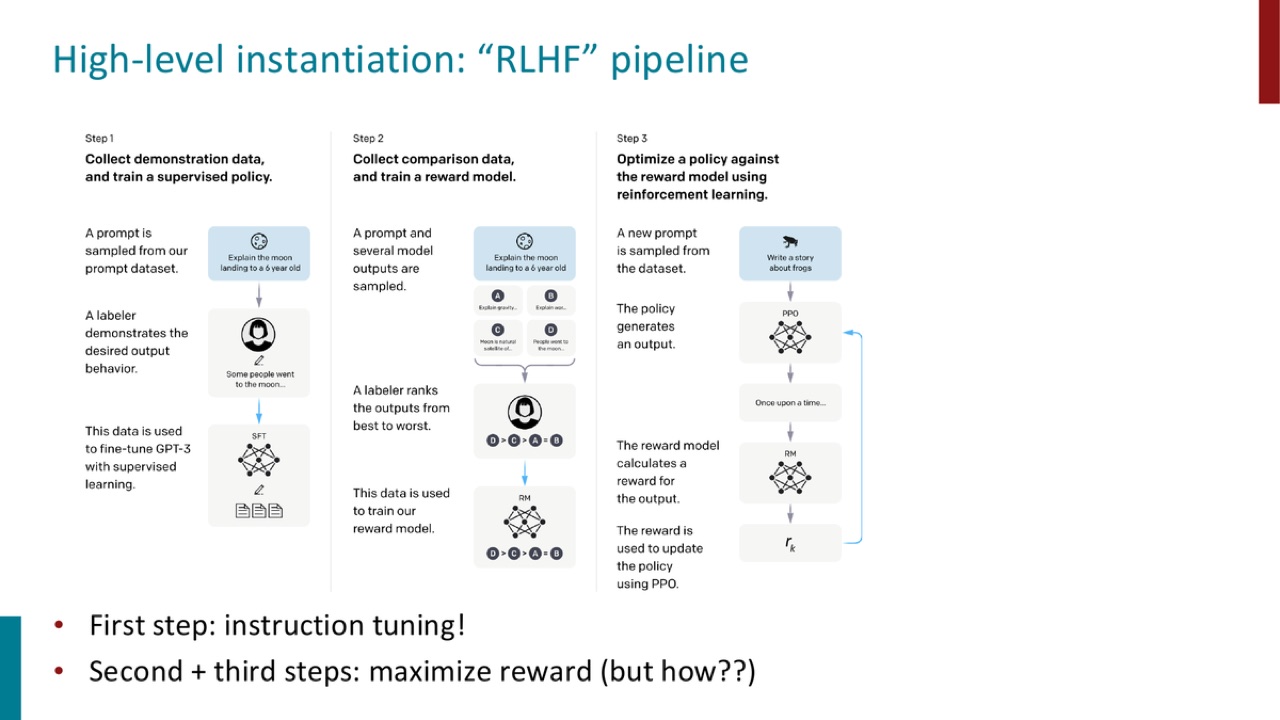
官方 PPT 截图:RLHF pipeline 先做 supervised instruction tuning,再收集 comparison data 训练 reward model,最后用 RL 让 policy 最大化 reward。
三步对应:
Step 1: Collect demonstration data and train a supervised policy.
Step 2: Collect comparison data and train a reward model.
Step 3: Optimize a policy against the reward model using reinforcement learning.
18.2 KL Penalty:不要偏离预训练模型太远
RLHF 不是只最大化 reward model。
PPT 给出优化 reward:
第二项是 penalty,防止 RL policy 偏离 pretrained model 太远。
PPT 说,在 expectation 中,这个 penalty 是 \(p_{\theta}^{RL}(s)\) 和 \(p^{PT}(s)\) 之间的 Kullback-Leibler divergence。

官方 PPT 截图:RLHF 的 reward 包含 reward model 分数,也包含让 RL policy 不要偏离 pretrained model 太远的 KL penalty。
18.3 为什么需要 KL penalty?
如果只优化 reward model,模型可能找到 reward model 的漏洞。
KL penalty 的直觉是:
这有助于保留语言质量,并降低 reward over-optimization 风险。
19. RLHF 相比 pretraining + finetuning 的收益
PPT 展示 Stiennon et al., 2020 的结果:
其中:
图中结论是:RLHF provides gains over pretraining + finetuning。
也就是说,instruction tuning 之后再做 reward-based optimization,可以进一步改善人类偏好指标。
20. InstructGPT 与 ChatGPT
PPT 把 InstructGPT 作为 scaling up RLHF to tens of thousands of tasks 的例子。
它展示了:
PPT 随后讲 ChatGPT:
还特别说明,OpenAI 和类似公司对 ChatGPT 的训练细节保密,包括:
本讲的重点不是记住某个产品细节,而是看清训练链条:
20.1 RLHF 会改变输出风格
PPT 展示了 RLHF behavior 的 stylistic changes:
这说明 preference tuning 不只影响对错,也影响回答风格。
21. RL 与 Reward Modeling 的局限
PPT 进入限制部分,第一句话是:
21.1 Reward Hacking
Reward hacking 是 RL 中常见问题。
如果 reward function 没有准确表达真正目标,模型会学会最大化 reward,而不是完成真正目标。
在 chatbot 中,PPT 指出:
Chatbots are rewarded to produce responses
that seem authoritative and helpful,
regardless of truth.
结果可能是:
21.2 Reward Model Over-Optimization
PPT 进一步说:
Reward model 只是人类偏好的近似模型。过度优化它,可能放大奖励模型的缺陷。
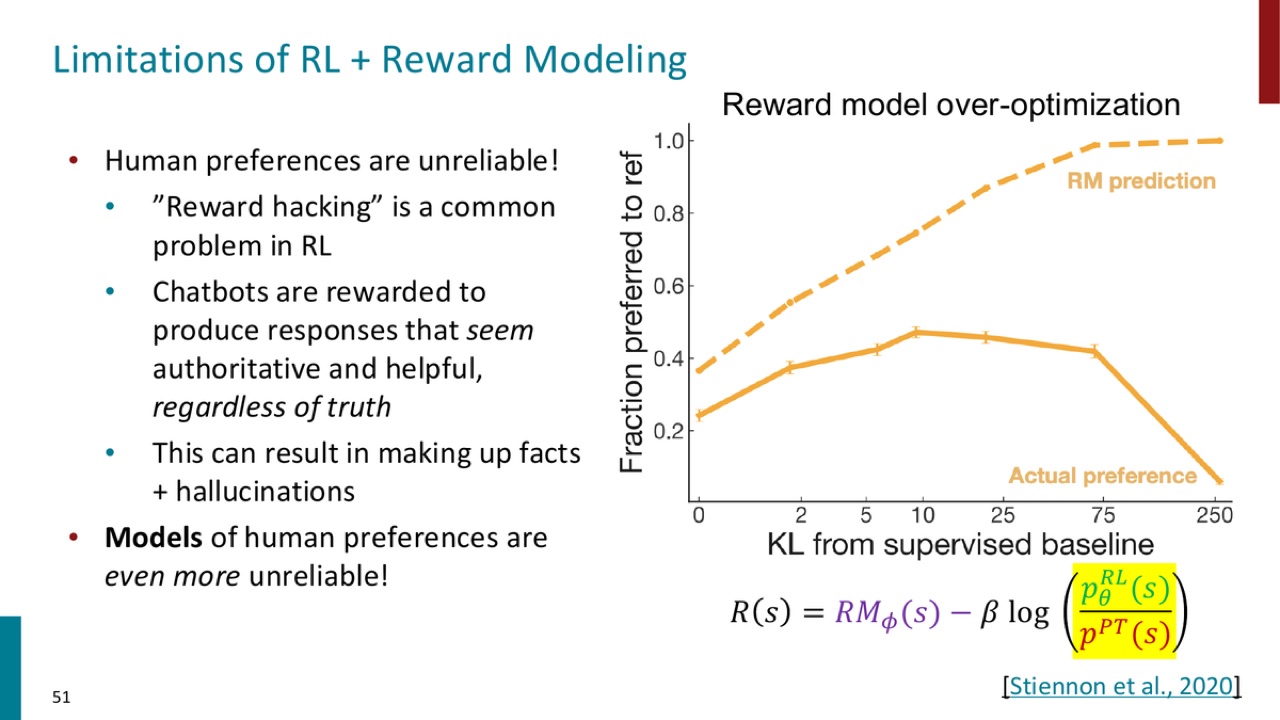
官方 PPT 截图:reward model over-optimization 会让模型过度追求 reward model 分数,而不一定更真实或更符合真实人类偏好。
21.3 学习重点
RLHF 不是魔法按钮。
它把“人类偏好”变成优化目标,但这个目标来自:
所以它可能改进模型,也可能引入新的偏差和副作用。
22. PPO 在 RLHF 中为什么复杂?
PPT 明确说:
列出的原因包括:
RL optimization can be computationally expensive and tricky
fitting a value function
online sampling is slow
performance can be sensitive to hyperparameters
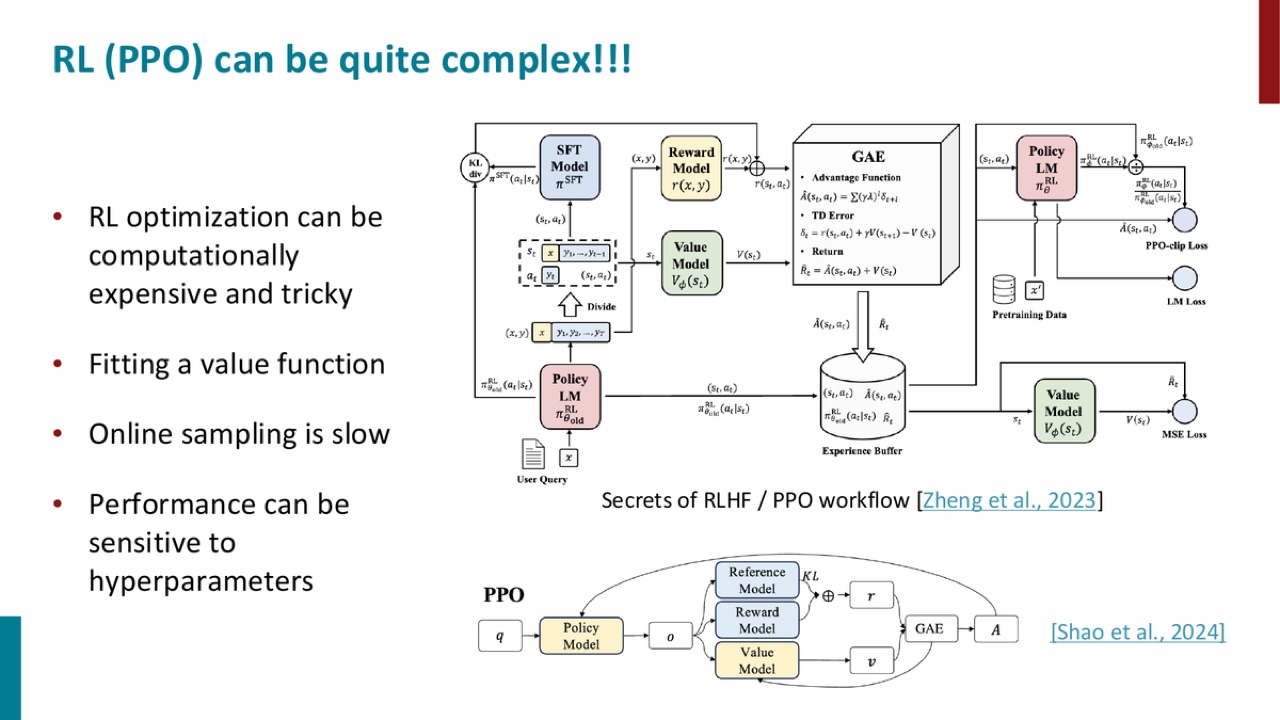
官方 PPT 截图:PPO workflow 通常涉及 policy、reference、reward、value 等组件,工程复杂且对超参数敏感。
22.1 为什么复杂会成为问题?
复杂意味着:
这就是 DPO 出现的动机之一:能不能不用显式 RL,也利用偏好数据优化模型?
23. DPO:Removing the RL from RLHF
DPO 的核心想法来自 PPT 标题:
PPT 回顾 RLHF 要最大化:
它有一个 closed form solution:
重新整理后,得到 reward 可以写成模型概率比:
直觉是:
24. DPO Loss:直接用偏好数据训练
DPO 继续使用 Bradley-Terry preference model。
偏好数据中有:
DPO loss:
把 derived reward 展开:
PPT 标注:\(\log Z(x)\) 会抵消,因为 loss 只比较 reward difference。

官方 PPT 截图:DPO 用 winner 和 loser 的相对概率比构造偏好 loss,避免显式训练 reward model 后再用 PPO 做 RL。
24.1 初学者该怎么理解 DPO?
不用被公式吓住。它做的是:
同时它保留了和 reference model 的比较,所以不是无限制地把 winner 概率拉高。
24.2 为什么说它去掉了 RL?
因为它不需要:
PPT 说:
25. Open-source RLHF is mostly not RL
PPT 直接写:
这句话要结合上一节理解。
很多开源实践仍然会说 alignment、preference tuning 或 RLHF,但具体优化方法可能已经不是 PPO-style RL,而是 DPO 或相关变体。
PPT 也提到新变体:
本讲没有展开这些方法,所以这里只记录它们是 DPO 之后出现的相关方法。
26. GRPO:改进 RL 路线
PPT 也介绍了另一条路:不是去掉 RL,而是改进 RL。
GRPO 来自 DeepSeekMath 相关工作。PPT 图对比了 PPO 和 GRPO。
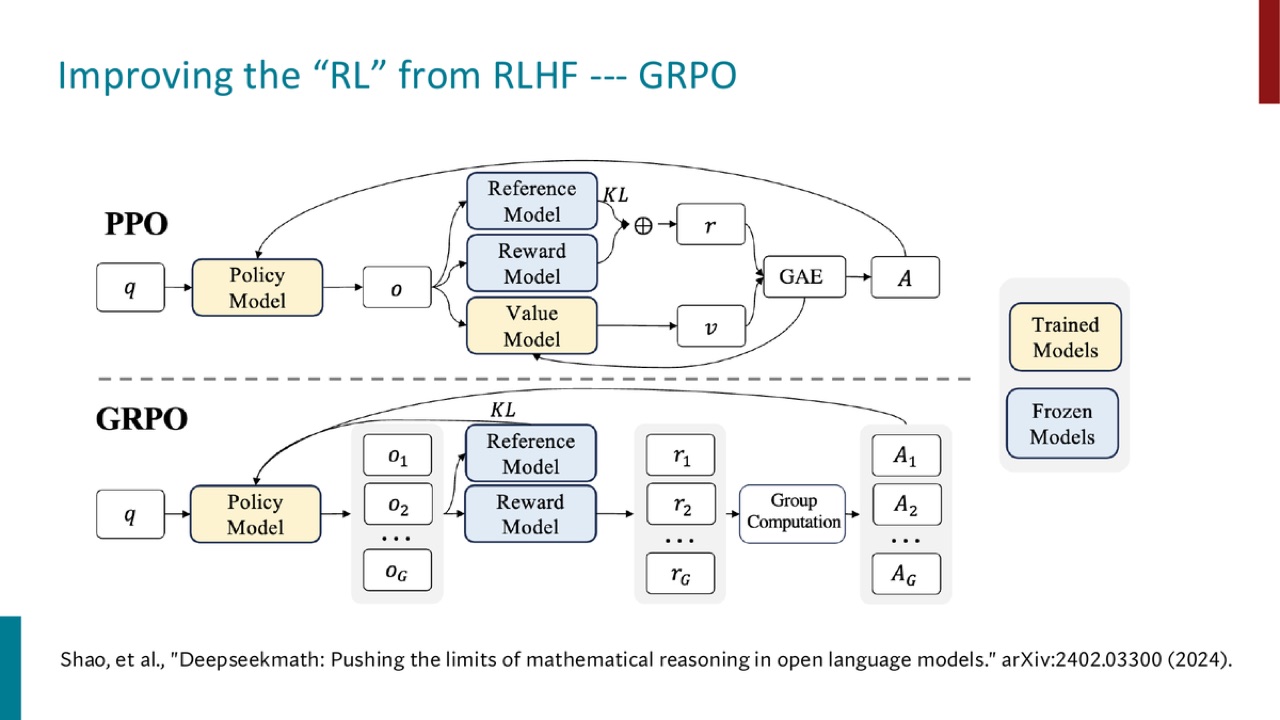
官方 PPT 截图:GRPO 相比 PPO 去掉 value model,使用一组输出的 reward 做 group computation 来估计 advantage。
26.1 PPO 和 GRPO 的图上差别
PPO 图里有:
GRPO 图里:
Policy Model 生成一组 outputs
Reference Model 和 Reward Model 仍存在
通过 Group Computation 得到 advantages
没有 Value Model
这就是现有 07 摘要里提到的:
27. 偏好标签从哪里来?
PPT 问:
并指出:
这提醒我们:preference data 不是抽象的数学对象。它来自真实标注劳动,涉及成本、劳动条件和标注者背景。
27.1 Annotator Bias
PPT 还说:
如果偏好数据反映的是特定标注者群体的偏好、文化、政治态度或价值判断,模型可能学习并放大这些偏差。
28. Preference Tuning 的 Unintended Impact
PPT 展示了一个偏好训练可能产生 unintended impact 的例子:
并关联到 Starling 7B Reward Model。
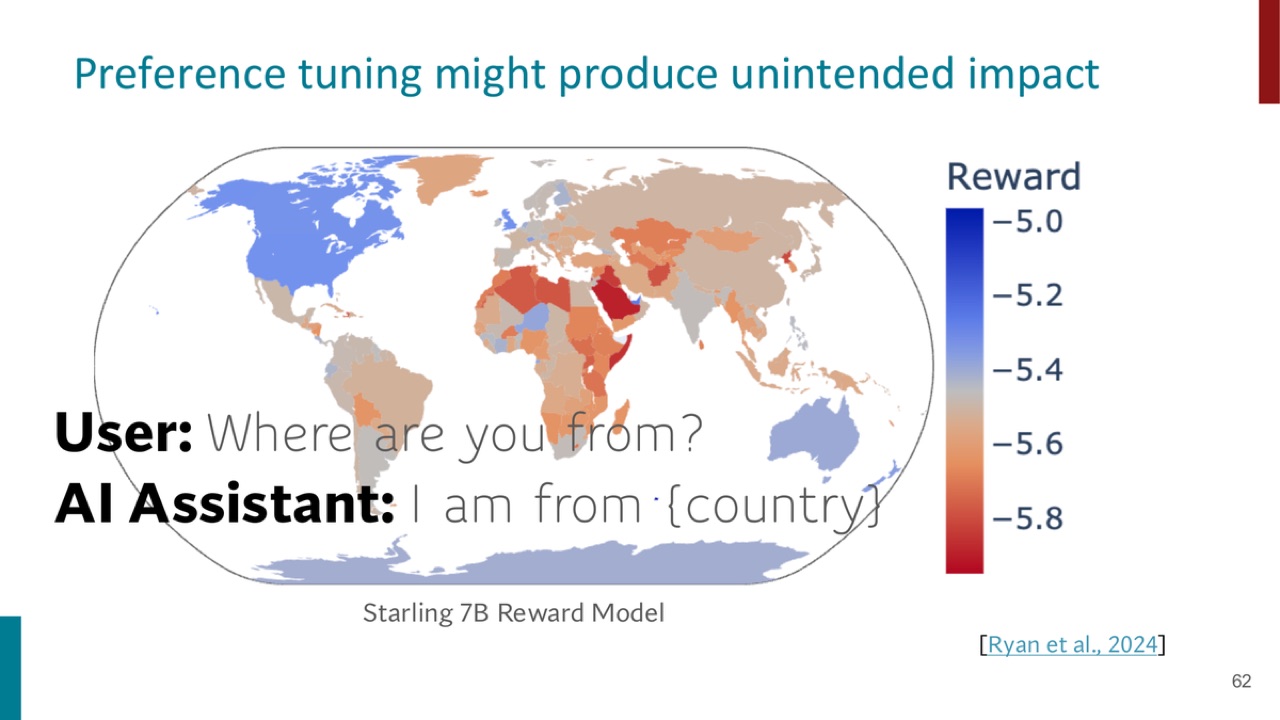
官方 PPT 截图:preference tuning 可能让不同国家或身份相关回答获得不同 reward,产生并不预期的行为差异。
本讲没有展开图中所有细节,但核心提醒很清楚:
29. Human Feedback 与 AI Feedback
PPT 最后说,RLHF 仍然是 very underexplored and fast-moving area。
它也指出:
为缓解数据需求,近期工作包括:
PPT 引用了 Bai et al., 2022,以及 Huang et al., 2022、Zelikman et al., 2022。
29.1 AI feedback 解决什么?
它试图减少人类偏好标注的成本。
如果模型或 AI 系统能提供反馈,就可以更快构造偏好数据。
29.2 AI feedback 没解决什么?
PPT 最后一页提醒:
there are still many limitations of large LMs
size, hallucination
that may not be solvable with RLHF
也就是说,后训练不能解决所有问题。模型规模、幻觉、训练数据、推理能力等问题,可能需要其他方法共同解决。
30. 全流程总图:后训练在做什么?
可以把本讲串成一条链:
Pretrained LM
学会文本分布,但不一定听指令
Instruction Fine-Tuning
用多任务 instruction-output pairs 训练
让模型学会执行指令
Preference Data
对同一 prompt 的多个回答做人类比较
得到 winner / loser
Reward Model / DPO
Reward Model: 学一个 RM_phi
DPO: 直接用偏好对优化 policy
RLHF / PPO / GRPO
PPO: 用 RL 优化 reward,但复杂
GRPO: 保留 RL 思路,简化 value model
风险与限制
reward hacking
hallucination
annotator bias
low-wage labeling
unintended preference effects
31. 方法对照表
| 方法 | 使用什么数据 | 优化什么 | 优点 | 局限 |
|---|---|---|---|---|
| Pretraining | 大规模原始文本 | 下一个 token 或重构输入 | 学通用语言分布 | 不保证听指令 |
| Instruction Fine-Tuning | instruction-output pairs | 监督学习输出答案 | 学会执行指令 | 开放任务无唯一答案,数据昂贵 |
| Reward Modeling | pairwise preferences | winner 分数高于 loser | 把偏好变成 scalar reward | 人类判断噪声,RM 可能不可靠 |
| RLHF / PPO | reward model + sampled outputs | 最大化 KL-regularized reward | 直接优化偏好 | 工程复杂,可能 reward hacking |
| DPO | winner / loser preference pairs | 直接偏好 loss | 去掉复杂 PPO loop | 仍依赖偏好数据和 reference model |
| GRPO | group sampled outputs + rewards | group-based advantage | 去掉 value model | 仍是快速发展中的 RL 路线 |
32. 公式小抄
32.1 Expected Reward
目标:让模型更常生成高 reward 输出。
32.2 Policy Gradient
目标:把不可微 reward 放进可采样估计的梯度形式。
32.3 Reward Model Pairwise Loss
目标:winner 得分高于 loser。
32.4 RLHF Reward with KL Penalty
目标:提高 reward model 分数,同时不要偏离预训练模型太远。
32.5 DPO Derived Reward
目标:把 reward 写成 policy 与 reference model 的概率比。
32.6 DPO Loss
目标:相对 reference model,提高 winner,降低 loser。
33. 常见误区
33.1 误区:预训练越大,模型越会当助手
不对。
PPT 的核心句子就是:
模型会预测文本,不代表它默认会满足用户意图。
33.2 误区:Instruction tuning 已经解决 alignment
不对。
Instruction tuning 能让模型学会执行指令,但开放式生成没有唯一答案,token-level loss 也不能表达所有人类偏好。
33.3 误区:RLHF 就是真实人类偏好本身
不对。
RLHF 优化的是:
它只是人类偏好的近似。
33.4 误区:Reward 高就一定更真实
不对。
PPT 明确说,chatbots 可能因为看起来 authoritative and helpful 而被奖励,即使内容不真实。这会导致 hallucinations。
33.5 误区:DPO 不需要偏好数据
不对。
DPO 去掉的是复杂 PPO-style RL loop,不是偏好数据。它仍然需要 winner / loser pairs。
33.6 误区:AI feedback 可以完全替代 human feedback
PPT 只是说近期工作尝试用 AI feedback 缓解数据需求。本讲没有说 AI feedback 完全解决偏好偏差、幻觉或可靠性问题。
34. 自学路线
第一次学后训练,可以按这个顺序:
- 先记住核心矛盾:LM objective 不等于 user assistant objective。
- 学 instruction tuning:多任务 instruction-output pairs。
- 看 instruction tuning 的局限:开放式生成无唯一答案,token loss 不等于偏好。
- 学 expected reward:如果有 reward,就能优化平均 reward。
- 学 REINFORCE 的直觉:高 reward 样本提高概率,低 reward 样本降低概率。
- 学 reward model:用 pairwise comparisons 和 Bradley-Terry loss。
- 学 RLHF pipeline:SFT、RM、RL。
- 学 PPO 为什么复杂:value function、online sampling、超参数敏感。
- 学 DPO:直接从 winner / loser pair 优化。
- 最后学风险:reward hacking、RM over-optimization、偏好数据来源和 bias。
35. 自测题
- 为什么 language modeling 不等于 assisting users?
- Instruction fine-tuning 的训练样本是什么形式?
- 为什么 instruction tuning 要跨许多任务?
- Super-NaturalInstructions 在 PPT 中说明了什么规模?
- MMLU 和 BIG-Bench 在本讲中用来做什么?
- Flan-T5 的结果说明了 instruction tuning 的哪两个特点?
- Instruction fine-tuning 为什么处理开放式生成仍然困难?
- 为什么 token-level LM loss 不能表达所有人类偏好?
- RLHF 中 expected reward 的目标是什么?
- REINFORCE 的核心直觉是什么?
- PPO 为什么要限制 policy update?
- 直接让人类给每个输出打分为什么不可行?
- Pairwise comparison 为什么比直接 rating 更可靠?
- Reward model 的 Bradley-Terry loss 想让什么样本得分更高?
- RLHF pipeline 的三步是什么?
- RLHF reward 里的 KL penalty 起什么作用?
- InstructGPT 和 ChatGPT 在本讲里展示了什么训练链路?
- Reward hacking 为什么会导致 hallucination?
- PPO 在 RLHF 中有哪些工程复杂点?
- DPO 为什么可以说是 removing the RL from RLHF?
- DPO loss 中 \(y_w\) 和 \(y_l\) 分别表示什么?
- GRPO 相比 PPO 图上少了什么关键组件?
- RLHF labels 的来源为什么是伦理和质量问题?
- Annotator bias 如何进入 language models?
- PPT 最后说哪些大模型限制可能不能靠 RLHF 解决?
36. 自测题答案
- Language modeling 学的是下一个 token 的文本分布;assisting users 要求理解意图、遵守指令、给出有帮助且尽量真实的回答。
- 通常是 instruction-output pair,有时还带 input,例如问题、任务说明、期望答案。
- 因为目标是让模型学会通用地跟随自然语言指令,而不是只适应单一任务格式。
- Super-NaturalInstructions 包含 over 1.6K tasks 和 3M+ examples。
- 它们是评估 multitask language models 的 benchmark,用于衡量模型在许多知识密集或多样任务上的表现。
- Instruction tuning 能显著提升性能;模型越大,在 Flan-T5 表格中获得的提升越大。
- 开放式生成没有唯一 ground truth,许多答案都可能合理,无法只靠标准答案监督。
- 因为 token 级错误的严重性不同,但普通 LM loss 不直接知道哪些错误对人类更严重。
- 让从当前模型采样出的回答具有更高平均 reward。
- 高 reward 样本提高概率,低 reward 样本降低概率,也就是 reinforce good actions。
- 为了避免 policy 一次更新变化太大,造成不稳定训练。
- 人类在线参与每次采样评分成本太高,而且判断也会有噪声。
- 人类直接打分容易尺度不一致;比较两个输出哪个更好通常更稳定。
- 让 winning sample 的 reward model 分数高于 losing sample。
- 先用 demonstration data 训练 supervised policy,再用 comparison data 训练 reward model,最后用 RL 优化 policy。
- 防止 RL policy 为了 reward model 分数偏离 pretrained model 太远。
- 展示了 instruction finetuning + RLHF 如何扩展到大量任务和对话助手。
- 如果 reward 偏向看起来权威和有帮助,模型可能学会自信地编造事实,从而产生 hallucination。
- 计算昂贵、需要 value function、online sampling 慢、对超参数敏感。
- 因为 DPO 直接从偏好对训练 policy,不需要复杂 PPO loop。
- \(y_w\) 是 winning response,\(y_l\) 是 losing response。
- GRPO 图中去掉了 value model,用 group computation 来估计 advantage。
- 因为标签常来自低薪海外标注劳动,也会受到标注者背景和价值观影响。
- 如果标注偏好反映特定群体偏见,模型通过偏好训练可能学习并放大这些偏见。
- PPT 提到 size 和 hallucination 等大模型限制,可能不是 RLHF 就能解决的。