12. 推理二:加速、蒸馏、长上下文与推理时扩展
官方 PPT 来源:Lecture 13 官方 PPT:Reasoning 2/2
这一讲接在“推理一”之后。第 11 讲重点是 decoding、RL 和 CoT 如何让模型在推理任务上表现更强;第 12 讲换一个角度问:如果模型已经会推理了,我们怎样让推理更快、更稳、更长、更会利用测试时计算?
PPT 的主线可以分成四块:
speculative decoding -> off-policy/on-policy 与蒸馏 -> long context extension -> test-time compute scaling
它们看起来分散,其实都围绕同一个工程问题:现代 LLM 的推理能力不只取决于模型参数,还取决于推理系统、训练数据分布、上下文窗口和验证机制。
0. 这一讲要学会什么
学完这一讲,你应该能回答:
- 为什么大模型逐 token 生成很慢,speculative decoding 如何用小模型或其他 draft 机制加速?
- 为什么 speculative sampling 仍然可以保持目标模型的采样效果?
- Dynamic speculative decoding、universal speculative decoding、EAGLE-3、suffix decoding 分别改进了什么?
- Online/offline RL 和 on-policy/off-policy RL 是两组不同概念,它们到底如何区分?
- 为什么真实 RLHF/RLVR 系统里会出现 off-policy drift?
- On-policy distillation 为什么被说成兼具 SFT 和 RL 的优点?
- Forward KL 和 reverse KL 的行为差异是什么?
- Long context 为什么不只是“把窗口开大”,而会被数据、attention 计算和位置编码共同限制?
- RoPE 为什么适合 long-context extension?
- Test-time compute scaling 为什么能让小模型在固定预算下追上更大模型?
1. Speculative decoding:先让快模型大胆猜,再让大模型验证
大模型生成慢的根本原因是自回归生成:每生成一个 token,都要把当前上下文送进大模型,得到下一个 token 分布,然后再进入下一步。序列越长,调用越多。
PPT 给出的直觉是:并不是所有 token 都同样难生成。
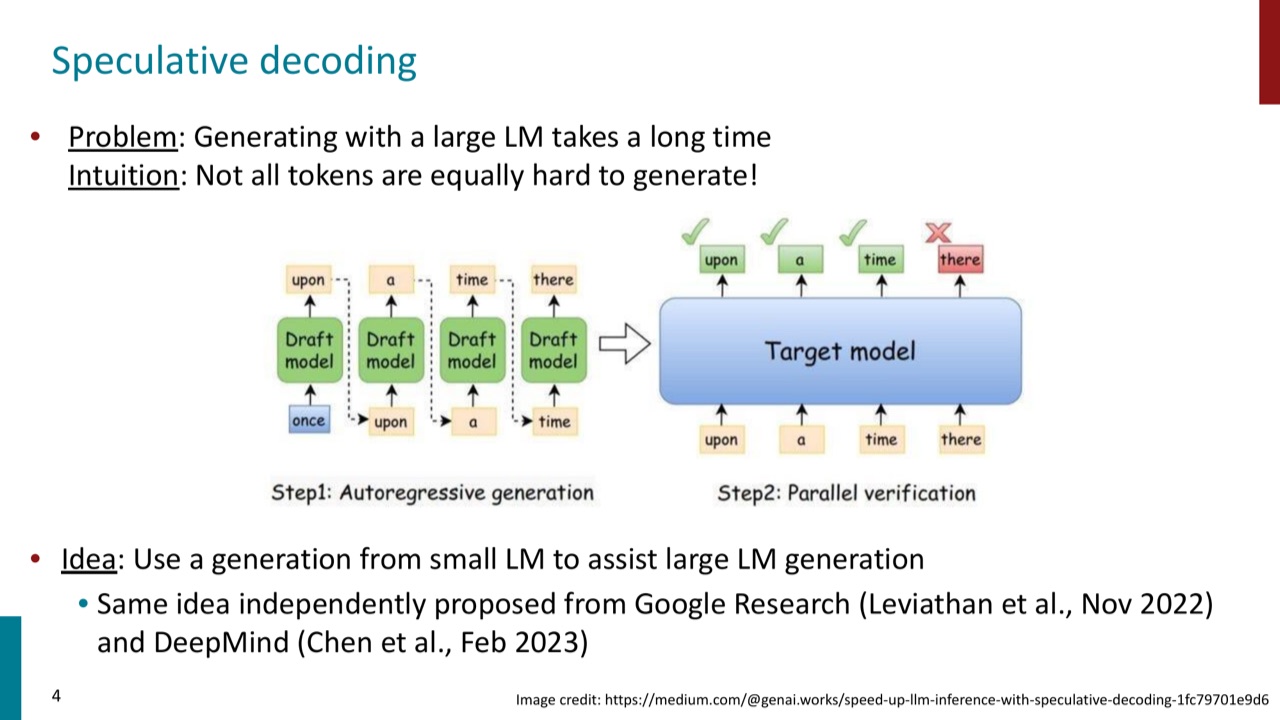
例如在一句非常常见的表达里,有些 token 几乎顺着上下文就能猜到。既然简单 token 不需要每一步都让大模型亲自决定,就可以先用一个更快的 draft 机制提出候选 token,再让 target model 一次性验证这些候选。
1.1 两个角色:draft model 和 target model
Speculative decoding 里有两个模型角色:
- Draft model:小、快、便宜。它负责一次提出多个 candidate tokens。
- Target model:大、慢、准。它负责验证 draft tokens 是否应该被接受。
它的基本流程是:
- 当前上下文给 draft model。
- Draft model 连续生成多个候选 token。
- Target model 对这些候选 token 做 parallel verification。
- 如果候选 token 与 target model 分布相容,就接受。
- 一旦遇到不该接受的 token,就拒绝并从 target model 的剩余分布重新采样。
关键点是:加速不是因为大模型不看这些 token,而是因为大模型可以把多个候选 token 放在一次验证里处理。生成多步变成“猜一串,再验一串”。
1.2 为什么它不是乱猜:接受概率和 rejection sampling
PPT 用小模型分布 \(p_i\) 和大模型分布 \(q_i\) 解释 speculative sampling。
如果 draft model 提出某个 token \(i\),有三种情况:
- 如果 \(q_i \ge p_i\),说明 target model 对这个 token 的概率不低于 draft model,直接接受。
- 如果 \(q_i < p_i\),说明 draft model 对它过度乐观,此时以概率 \(\frac{q_i}{p_i}\) 接受。
- 如果被拒绝,就从 target model 相对 draft model 多出来的剩余质量中重新采样,也就是从 \((q_i-p_i)_+\) 对应的分布中采样。

这就是 PPT 说 speculative sampling 是 rejection sampling 的原因:我们用容易采样的分布 \(p\) 提案,但最终想模拟的是更复杂、更准确的分布 \(q\)。
PPT 特别强调:虽然过程里用了小模型采样,但这个采样过程可以达到从 target LM 采样的效果。Chen et al. 2023 的附录给出形式证明。
1.3 它快在哪里?
PPT 举了一个结果:用 60M 的 T5-small 做 draft model,用 11B 的 T5-XXL 做 target model,可以得到 2 到 3 倍加速,并保持 identical outputs。
这句话非常重要:speculative decoding 的目标不是“牺牲质量换速度”,而是尽量在保持目标模型输出分布的前提下减少昂贵计算。
直觉上,加速来自三件事:
- Draft model 很便宜,可以快速提出多个 token。
- Target model 用一次前向验证多个 token,而不是一步一步生成。
- 如果 draft model 猜得准,连续多个 token 都能被接受。
所以 speculative decoding 的收益取决于 draft 与 target 的一致程度。如果 draft model 经常猜错,大模型就频繁拒绝,加速会下降。
2. Speculative decoding 的新变体
PPT 接着讲了一批新的推测解码方法。这里不用把每个系统的实现背下来,先抓住它们分别在修什么问题。
2.1 Dynamic speculative decoding:lookahead 不是固定的
原始 speculative decoding 可以让 draft model 一次往前猜 \(k\) 个 token。问题是:所有位置都用同一个 \(k\) 不一定合理。
有些位置很容易,draft model 可以大胆多猜几个;有些位置很难,再继续猜只会增加拒绝概率。
Dynamic speculative decoding 的想法是:动态调整 lookahead size,也就是每轮候选 token 的数量。它可以用轻量 classifier 或 confidence threshold 判断 draft model 是否应该继续往前猜,还是该切换到 target model 验证。

所以 dynamic speculative decoding 的核心不是换模型,而是让“猜多远”变成自适应决策。
2.2 Universal speculative decoding:tokenizer 不同也能协作
原始 speculative decoding 通常要求 draft 和 target 使用相同 tokenization。否则 draft 生成的 token 序列无法直接被 target 对齐验证。
Universal speculative decoding 处理的是 heterogeneous tokenization:draft model 和 target model 的 tokenizer 不同,也可以通过 re-encoding 和 alignment 技术支持。
这点在真实系统里很重要,因为你不一定总能找到一个既小又快、同时 tokenizer 完全一致的 draft model。
2.3 EAGLE-3:用 target model 的内部特征来猜未来
EAGLE 是 model-based speculative decoding 路线。它不是只让一个独立小模型在文本层面猜 token,而是让 draft head 利用 target model 的内部表示。
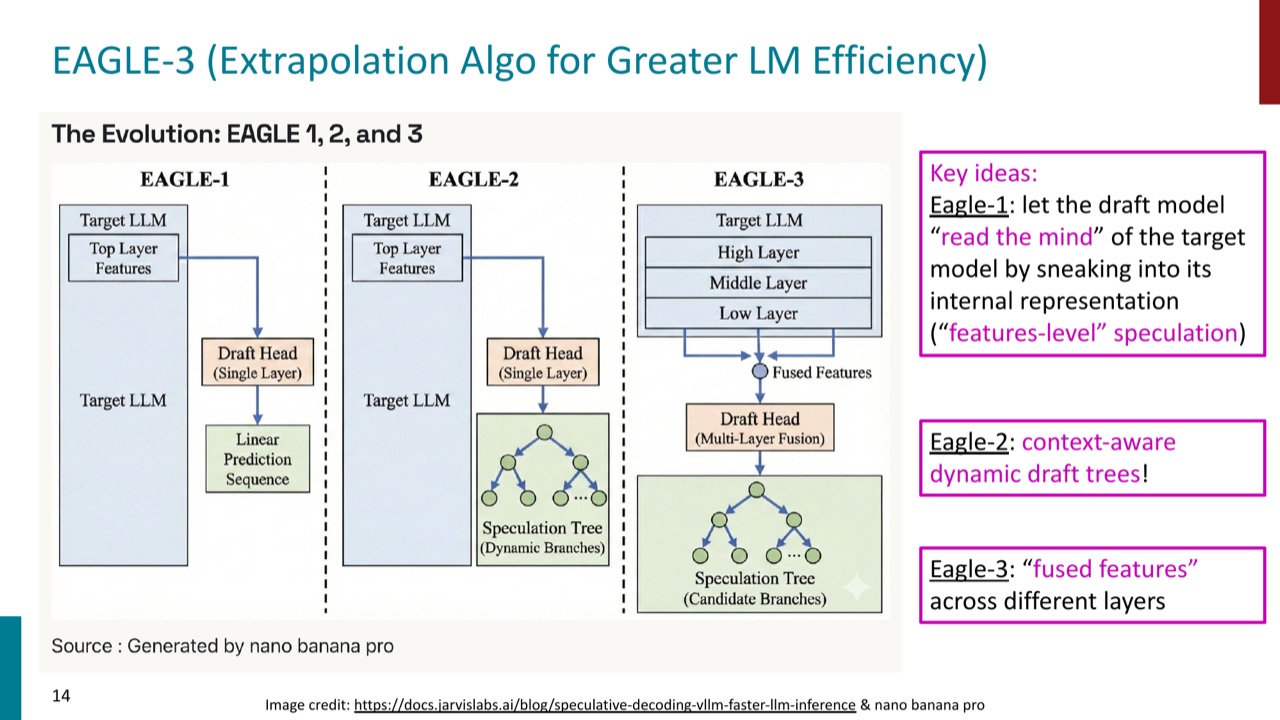
PPT 对 EAGLE-1、EAGLE-2、EAGLE-3 的说法可以这样记:
- EAGLE-1:让 draft model “读 target model 的心”,也就是偷看 target model 的内部 representation,做 feature-level speculation。
- EAGLE-2:加入 context-aware dynamic draft trees,让候选树随上下文变化。
- EAGLE-3:融合不同层的 features,也就是 fused features across different layers。
EAGLE-3 的优势是它更贴近 target model 的内部状态;代价是它需要训练一个辅助 head,并且通常在 GPU 上运行,会占用主模型附近的计算与显存资源。
2.4 Suffix decoding:用 suffix tree 做 model-free 推测
Suffix decoding 是另一条路线。PPT 把它称为 extreme speculative decoding,并把它和 EAGLE-3 对比。
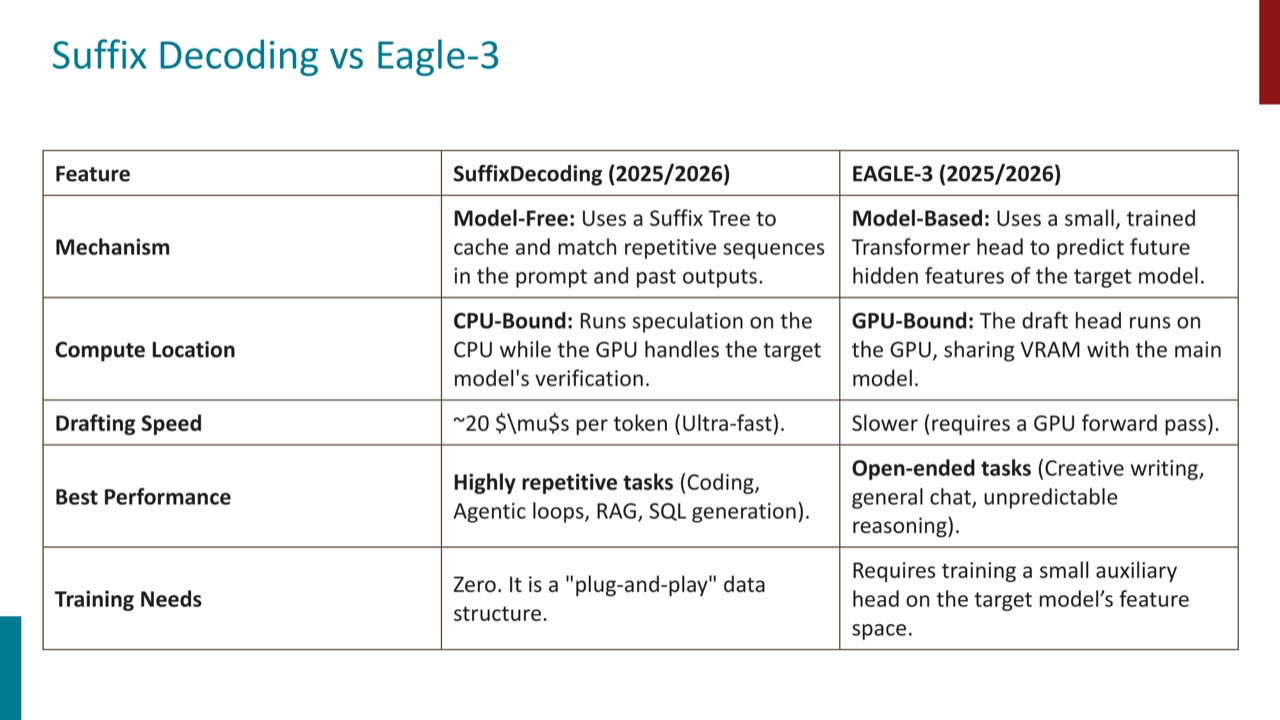
这张表的核心区别如下:
| 维度 | Suffix decoding | EAGLE-3 |
|---|---|---|
| 机制 | 用 suffix tree 缓存并匹配 prompt 和历史输出里的重复序列 | 用训练过的小 Transformer head 预测 target model 的未来 hidden features |
| 是否 model-based | model-free | model-based |
| 计算位置 | CPU 上做 speculation,GPU 处理 target verification | draft head 在 GPU 上运行,与主模型共享资源 |
| 适合任务 | coding、agent loops、RAG、SQL 等重复模式强的任务 | creative writing、general chat、不可预测 reasoning 等开放任务 |
| 训练需求 | 不需要训练,plug-and-play | 需要训练辅助 head |
可以把这两类方法理解成两种猜法:
- EAGLE-3 是“看模型内部状态来猜”。
- Suffix decoding 是“看上下文里重复结构来猜”。
如果任务本身重复性强,比如代码补全、agent 循环、RAG 生成、SQL 生成,suffix tree 很可能抓到大量可复用片段。如果任务高度开放,model-based 的 EAGLE-3 更有机会泛化。
3. Online/offline 与 on-policy/off-policy:两组概念别混
第二部分切到 RL 系统。PPT 先做概念澄清,因为很多人会把 online、offline、on-policy、off-policy 混在一起。

3.1 Online vs offline:能不能在训练中和环境交互
这组概念问的是:训练时 agent 能不能继续产生新经验?
- Online RL:agent 在训练过程中可以和环境交互,产生新的 rollouts。
- Offline RL / Batch RL:学习严格发生在预先记录好的数据集上,比如 human logs 或 previous agents 的数据。agent 不能探索,也不能测试新 action。
所以 online/offline 关注的是数据来源是否可以继续刷新。
3.2 On-policy vs off-policy:训练数据是不是来自当前 policy
这组概念问的是:用于训练的 rollouts 是否来自当前正在更新的 policy?
- On-policy RL:训练数据正是当前 policy 生成的。一旦 policy 更新,旧 policy 的数据就被视为 stale,通常丢弃。
- Off-policy RL:agent 可以从任意 policy 生成的数据中学习,包括旧 policy、其他 policy、人类数据。经验通常进入 replay buffer,可重复使用。
典型例子是:
- REINFORCE、PPO、GRPO 属于 on-policy 范式。
- DQN 属于常见 off-policy 范式。
3.3 组合关系:online 不等于 on-policy
PPT 还强调:
- Online/offline 看的是“能不能交互”。
- On-policy/off-policy 看的是“rollouts 是否来自最新 policy”。
因此 online off-policy 很常见:agent 在线和环境交互,但把经验放进 replay buffer,之后反复学习,像 DQN。
那有没有 offline on-policy?PPT 的说法很直接:没有真正的 offline on-policy RL,除非非常勉强地解释。因为 on-policy 要求数据来自当前 policy,而 offline 数据集通常是过去固定下来的,不会随当前 policy 更新。
4. Off-policy drift:真实 RLHF 系统为什么会偏离 on-policy
理论上 PPO/GRPO 这类方法倾向 on-policy,但真实工程里很难做到完全同步。
PPT 提到 asynchronous RLHF、PipelineRL、generation/training cluster 分离等情况。核心问题是:生成数据的 policy 和训练时更新的 policy 不是同一个时间点的模型。
例如 PipelineRL 允许 generation engine 在生成中途收到新的 model weights,暂停、加载新权重,然后继续生成。这样一个序列的早期 token 可能由旧 policy 生成,后期 token 由新 policy 生成,形成 mixed-policy sequence。
4.1 为什么 rollouts 会 stale
PPT 列出的原因包括:
- 有意使用 asynchronous RL。
- 对同一 batch 做多个 gradient steps。
- 使用 large replay buffers。
- 把 generation cluster 和 training cluster 分离:一个集群优化 inference,一个集群优化 gradient computation,中间权重传输有延迟。
这会导致训练算法以为自己在用当前 policy 的数据,但实际 rollouts 来自旧 policy 或混合 policy。
4.2 Off-policy 为什么是问题

PPT 列出三个问题:
- Biased gradient estimates:梯度估计偏了,因为数据分布不再等于当前 policy 分布。
- Importance weight explosion:重要性权重可能爆炸。
- Reward hacking amplification:如果旧数据已经带有某些 exploit,重复使用可能放大 reward hacking。
重要性权重的形式是:
当当前 policy 和 old policy 差距变大时,这个比值会不稳定。PPO clipping 就是为了限制这种 ratio 变化太大。
4.3 缓解方式
PPT 给出的 mitigation strategies 包括:
- PPO clipping。
- 对 reference policy 加 KL penalty。
- 使用没有 critic/advantages 的算法,缩小 off-policy drift 窗口,例如 GRPO 或 REINFORCE。
- 减少 epochs。
- SGLang / vLLM 的 continuous batching with weight streaming。
- PipelineRL 的 in-flight weight update。
可以把它们分成两类:
- 算法层面:用 clipping、KL、少做 epochs、减少 critic/advantage 链条来稳住更新。
- 系统层面:让生成端和训练端的权重更快同步,减少 rollouts 变 stale 的时间。
5. On-policy distillation:让学生在自己的分布上向老师学习
第三部分讲 on-policy distillation,也叫 generalized knowledge distillation。PPT 的定义很清楚:
- 过去很多 distillation 是 teacher-centric,所以相对于 learner 是 off-policy。
- On-policy distillation 是 student-centric,所以相对于 learner 是 on-policy。
5.1 标准蒸馏的问题:学生学的是别人的上下文
传统知识蒸馏里,teacher 在固定数据上给 soft target,student 去拟合 teacher 分布。问题是训练上下文通常来自 ground truth 或 teacher generation,而不是 student 自己实际会生成的上下文。
这会带来 train-test mismatch,也就是 exposure bias:训练时学生总在“干净上下文”里学习,测试时却必须接着自己生成的 token 往下走。一旦前面犯错,后面的上下文就偏离训练分布。
5.2 On-policy distillation 的核心:student-generated context
On-policy distillation 改成:
- Student 自己生成上下文 \(\tilde{y}_{<t}\)。
- Teacher 在 student 生成的上下文上给出 soft distribution。
- Student 学会在自己会遇到的状态上恢复和变强。

PPT 用三种 loss 对比:
- 标准 KD:loss 是 forward KL,context 是 ground-truth context,是 off-policy。
- Sequential KD:loss 是 NLL,context 是 teacher-generated context,也是 off-policy。
- On-policy KD / GKD:loss 是 reverse KL,context 是 student-generated context,是 on-policy。
5.3 Forward KL 与 reverse KL:覆盖所有模式,还是集中到一个模式
理解 on-policy distillation 前,要先理解 KL 方向。

Forward KL 是:
它由 \(p(x)\) 加权,所以如果 \(p\) 在某个区域有质量但 \(q\) 没覆盖,会被强烈惩罚。PPT 把它称为 mean-seeking 或 mass-covering:倾向让 \(q\) 覆盖 \(p\) 的所有 modes。
Reverse KL 是:
它由 \(q(x)\) 加权,所以如果 \(q\) 只集中到 \(p\) 的某个高概率 mode,也未必会被强迫覆盖所有 modes。PPT 把它称为 mode-seeking 或 mode-collapsing。
5.4 为什么 on-policy distillation 更像“轻量 RL”
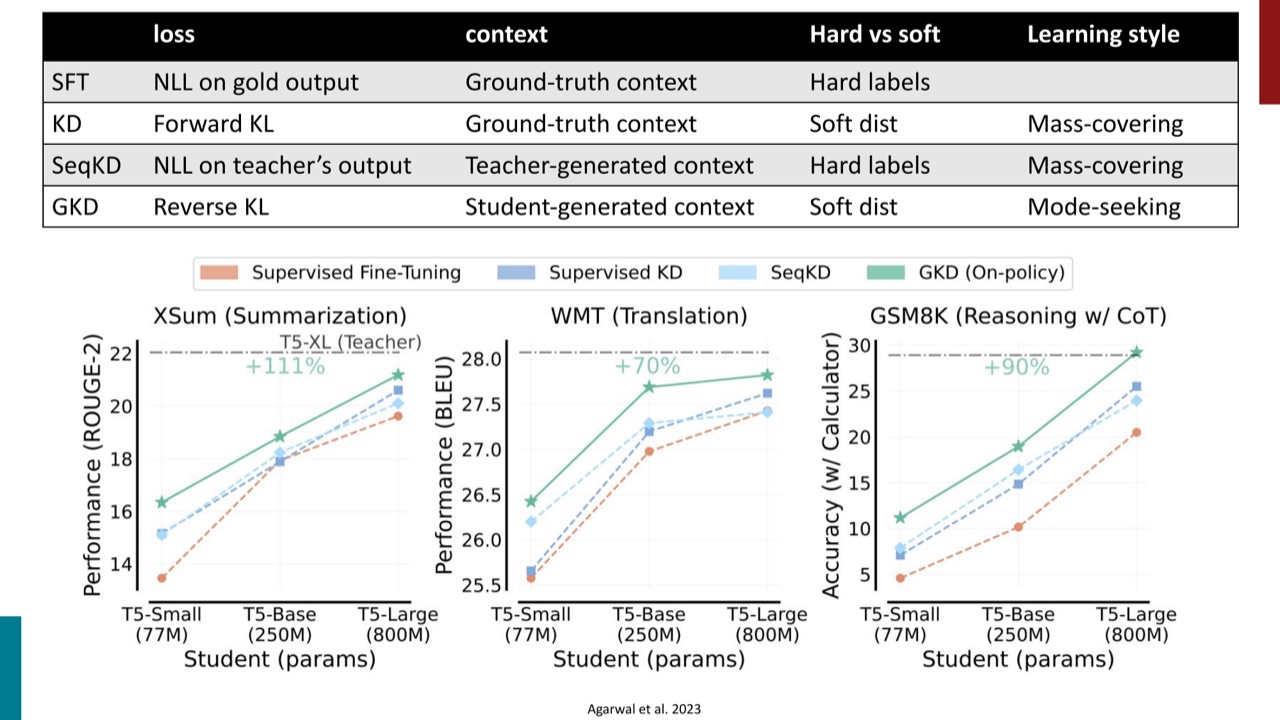
PPT 的对比表可以这样整理:
| 方法 | loss | context | 标签 | 学习风格 |
|---|---|---|---|---|
| SFT | gold output 上的 NLL | ground-truth context | hard labels | 官方 PPT 未标注 |
| KD | forward KL | ground-truth context | soft distribution | mass-covering |
| SeqKD | teacher output 上的 NLL | teacher-generated context | hard labels | mass-covering |
| GKD | reverse KL | student-generated context | soft distribution | mode-seeking |
On-policy distillation 的 implication 是:
- context 来自学生自己的 generation。
- 这减少 train-test mismatch。
- 学生学会从自己的错误里恢复。
- Reverse-KL 的 mode-seeking 性质让学生更尖锐、更自信地学习自己最好的行为,而不是试图 diffuse 地覆盖 teacher 的所有模式。
PPT 还把 on-policy distillation 和 RL 对比:
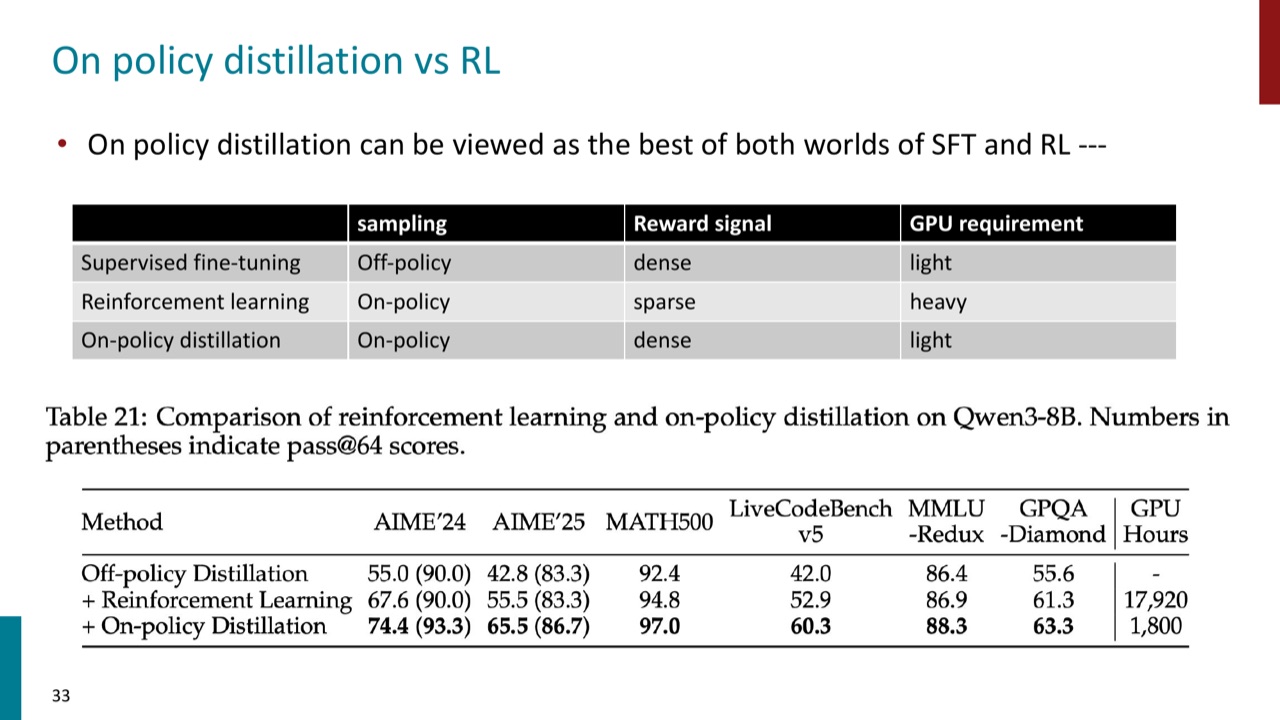
| 方法 | sampling | reward signal | GPU requirement |
|---|---|---|---|
| Supervised fine-tuning | off-policy | dense | light |
| Reinforcement learning | on-policy | sparse | heavy |
| On-policy distillation | on-policy | dense | light |
所以它被说成 SFT 和 RL 的“best of both worlds”:像 RL 一样 on-policy,但像 supervised learning 一样有 dense signal,工程负担又更轻。
5.5 用于 domain-specific adaptation
PPT 给了一个很实用的例子:对开源模型做领域适配,比如在公司内部文档上微调 Qwen-8B。

如果直接在已经 post-trained 的 off-the-shelf OSS model 上做 naive midtraining,可能会学到新领域知识,却损坏原先 post-training 得到的能力,例如 instruction following。
PPT 的例子是:
- 70% 做 midtraining,让模型获得新领域知识。
- 30% 做 on-policy distillation,用 instruction-tuning dataset 恢复 instruction following。
这说明 on-policy distillation 不只是压缩 teacher,也可以作为领域适配之后的能力恢复机制。
6. Long context:推理要变强,窗口也要变长
第四部分讨论 long-context extension。PPT 的核心判断是:Scaling reasoning requires scaling long-context.

长上下文需求来自很多真实任务:
- 软件工程:理解整个代码仓库。
- 法律分析:阅读跨越数百页的文件。
- 个性化对话:利用长期交互历史。
- 极难数学题:需要大量 trial and error 和不同 problem-solving strategies。
如果模型只能看很短窗口,就算单步推理能力强,也无法利用跨文档、跨文件、跨长历史的信息。
6.1 长上下文难在哪里

PPT 列出三类限制:
- Data limitation:大多数互联网文档不够长,不能支撑极长上下文预训练。
- Compute/memory limitation:标准 attention 需要 quadratic computation。
- Generalization limitation of positional embeddings:在短序列上训练的位置编码,不一定能泛化到更长序列。
这三类限制分别对应数据、算法复杂度和表示学习。
6.2 数据长度本身就是瓶颈
PPT 列了典型互联网数据长度:
- Common Crawl 网页常见长度约 600 到 1200 tokens,很多页面很碎。
- Wikipedia 约 500 到 1500 tokens。
- arXiv 科学论文可到 5000 到 10000+ tokens。
- Project Gutenberg 书籍可到 50000 到 100000+ tokens,但属于长尾。
- GitHub code 长度变化很大,很多脚本短,库文件长。
这说明:想让模型学会长上下文,不只是把模型窗口调大,还要让训练数据真的包含长距离依赖。
7. Positional embeddings:为什么长上下文卡在位置表示上
Transformer 本身没有序列顺序感。如果不加入位置编码,token 只是一组无序向量。Long context extension 绕不开 positional embeddings。
7.1 Learned positional embeddings 的问题
早期 LLM 广泛使用 learned positional embeddings,例如 BERT、RoBERTa、GPT-2、GPT-3、ALBERT、ELECTRA、BART。

它的问题是:
- 位置向量随机初始化,然后通过 backprop 学出来。
- 对训练时没见过的位置,没有自然定义。
- 对超过训练长度的位置,泛化不好。
- 虽然学习式位置编码一度性能较好,但它成为 long-context extension 的主要瓶颈,因此最近 LLM 不再常用。
直观地说,如果模型只学了位置 1 到 4096 的 embedding,那么位置 4097、10000、100000 不会自动有合理表示。
7.2 RoPE:把位置编码进 query/key 的旋转
RoPE 是 Rotary Position Embedding。它不是把位置向量加到 token embedding 上,而是在 attention 里旋转 query 和 key。
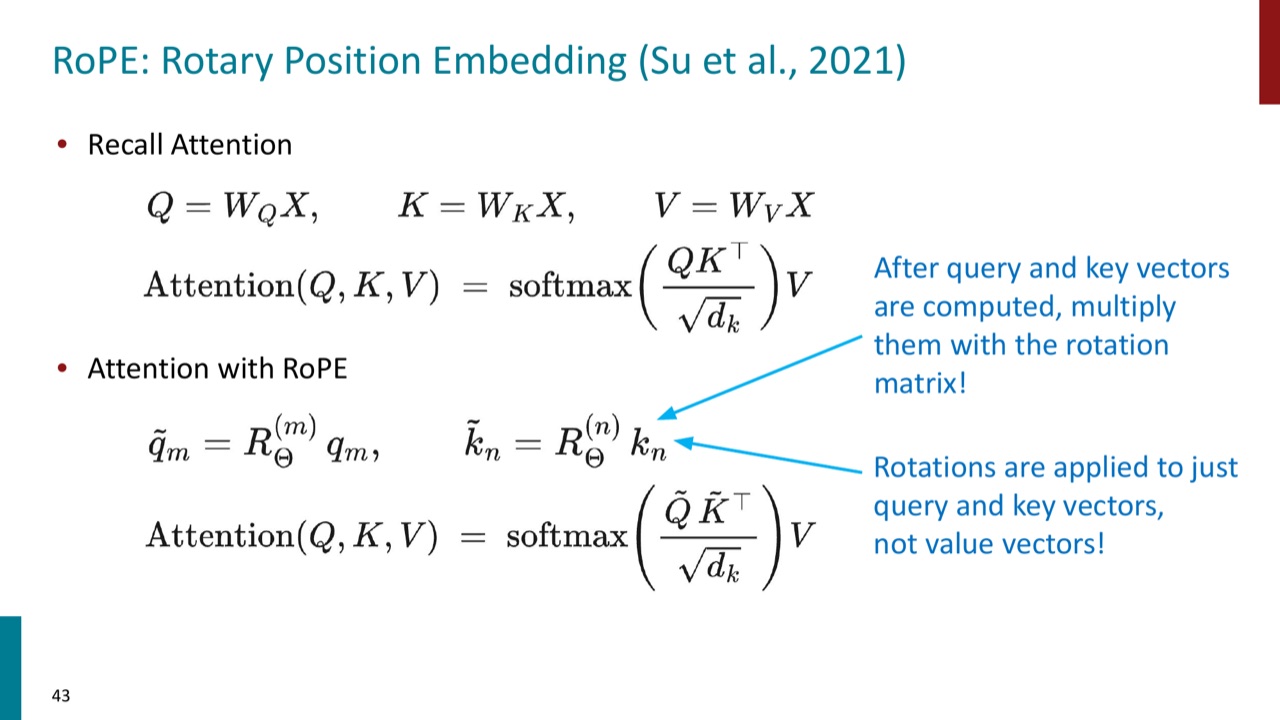
先回忆 attention:
RoPE 的做法是在 query 和 key 计算出来之后,乘以旋转矩阵:
然后 attention 变成:
PPT 特别强调:旋转只作用于 query 和 key,不作用于 value。
7.3 RoPE 的旋转矩阵
RoPE 会把向量维度按 pair 分组,在每一对维度上做二维旋转。
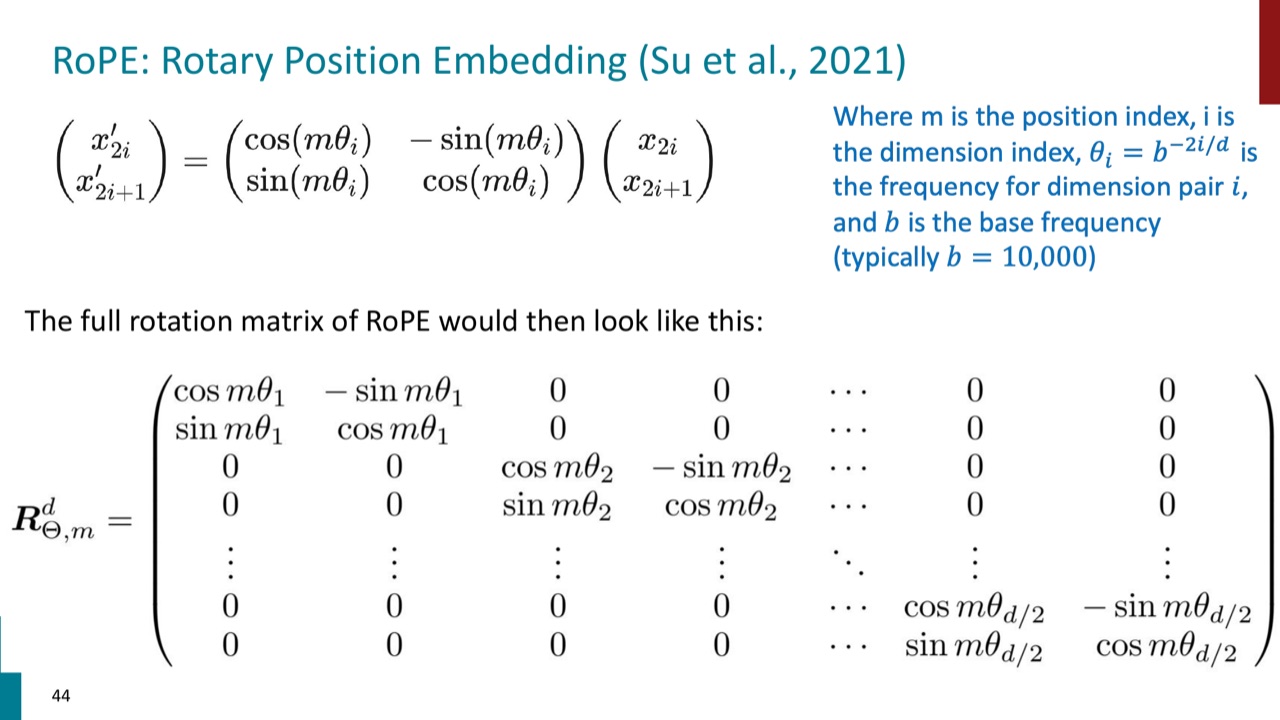
单个维度对的旋转可以写成:
其中 \(m\) 是 position index,\(i\) 是 dimension index,\(\theta_i=b^{-2i/d}\) 是维度对 \(i\) 的频率,\(b\) 是 base frequency,通常取 \(10000\)。
你可以把 RoPE 想成:位置越靠后,query/key 在每个二维子空间里旋转的角度越大;不同维度对有不同旋转频率。
7.4 RoPE 为什么能表达相对距离
RoPE 适合长上下文的关键在相对位置。PPT 用 “Taylor” 和 “Swift” 的例子解释:如果两个词分别在位置 10 和 11,它们与在位置 100 和 101 时会得到相同的相对关系。

原因是:
所以 query 和 key 相乘时,位置项会变成只依赖 \(n-m\) 的相对距离:
这就是 RoPE 的美妙之处:每个绝对位置的旋转矩阵不同,但在 attention score 里,相关的是相对位移。
7.5 RoPE 和原始 sinusoidal embedding 的区别

PPT 对比了 original sinusoidal embedding 和 RoPE:
| 维度 | Original Sinusoidal | RoPE |
|---|---|---|
| Integration | additive,加到 input embedding 上 | multiplicative,作用在每层 attention 的 \(Q\) 和 \(K\) 上 |
| Norm preservation | 会增加 token embedding 的 norm | 保持 token embedding 的 norm |
| Relative distance | 数学上可捕捉,但经过 additive integration 后信息会变混 | 通过 rotation angle 清晰进入 QKV attention |
| Extrapolation | 显著困难 | 支持 position interpolation、NTK scaling、YaRN 等 long-context extension |
所以 RoPE 不是“另一个位置编码公式”而已。它的位置结构直接进入 attention 计算,使相对距离信息更干净,也更容易做长上下文扩展。
8. Long-context extension 的实践路线
PPT 最后把 long-context extension 的实践分成四类。
8.1 Position encoding modifications
RoPE scaling 是 2026 年前后最常见的方法家族。

PPT 提到三种:
- Linear interpolation / Position Interpolation:把 position indices 按比例缩小,让模型看到熟悉的相对位置。Meta 用它把 LLaMA 从 2K 扩到 32K+,需要轻量 fine-tuning。
- NTK-aware interpolation:不直接线性压缩位置,而是调整 rotary base frequency,更好保留 high-frequency components。还有 dynamic NTK 变体,会根据 inference sequence length 自适应。
- YaRN:结合 NTK scaling、attention temperature correction 和 ramp function,对不同 frequency bands 采取不同处理:低频 interpolation,高频 extrapolation。
核心思想是:不要让模型突然面对完全没见过的位置尺度,而是调整 RoPE 的位置频率,让更长序列在模型熟悉的相对位置空间里可解释。
8.2 Progressive / staged training

PPT 给了一个常见 recipe:
- 从 base model 开始,例如 4K 到 8K context。
- 应用 position encoding modification。
- 在长文档上继续预训练,并逐步增加 sequence length,例如 8K 到 32K 到 64K 到 128K。
- 再在 long-context instruction data 上 fine-tune。
关键 insight 是:不需要重做完整预训练。PPT 说通常原始 pretraining tokens 的 0.1% 到 1% 就足够 adaptation。
这很像“让模型补课”:主能力已经在 base model 里,long-context continuation 主要教它如何在更长窗口里稳定使用这些能力。
8.3 Data engineering
PPT 提到三类数据工程:
- Upsampling long documents,例如 books、code repos、long-form articles、concatenated related documents。
- Synthetic long-context tasks,例如 needle-in-a-haystack retrieval、long-range QA、multi-document summarization。
- LongAlign-style instruction tuning,让任务真的要求模型使用散布在完整上下文里的信息。
- Self-instruct for long contexts,用强模型生成 long-context instruction-response pairs。
这里的重点是:长上下文训练不能只把短文拼长。任务必须迫使模型使用远处的信息,否则模型会学会忽略长尾上下文。
8.4 Attention architecture modifications

PPT 列了几种结构或实现改造:
- Sparse / sliding window attention,加 global attention tokens,类似 Longformer。
- Flash Attention / FlashAttention-2/3,在训练中把 memory 从 \(O(n^2)\) 降到 \(O(n)\)。
- Grouped Query Attention / Multi-Query Attention,减少 KV cache memory,让 inference 支持更长上下文。
注意这里有两类瓶颈:
- 训练时:attention matrix 和激活存储压力很大。
- 推理时:KV cache 会随上下文长度增长而变大。
GQA/MQA 主要帮助推理时 KV cache,Flash Attention 主要帮助训练时 memory。
9. Test-time compute scaling:不只训练更多,也可以推理时多想
最后一部分回到 reasoning。PPT 说 test-time compute scaling 在 OpenAI o1 发布后变得非常热门,但相关思想已经出现在更早的工作里。
它问的问题很直接:
9.1 为什么它挑战传统 scaling 观念

传统 scaling 更关注训练时 compute:更大模型、更多数据、更多 pretraining FLOPs。Test-time compute scaling 关注的是 inference budget:
- 生成更多候选解。
- 让模型做更多 revision。
- 用 verifier 或 reward model 选择更好的答案。
- 用搜索保留多个解题路径。
PPT 引用的结论是:智能地 scaling test-time compute,有时比单纯 scaling model parameters 带来更大的性能收益。固定 inference budget 下,小模型加上聪明的 test-time compute strategy,可能超过使用标准 decoding 的大模型。
9.2 推理时扩展有哪些策略

PPT 列出的策略包括:
- Best-of-N sampling:生成 \(N\) 个独立解,用 verifier 选最好。
- Weighted Best-of-N:从 compute-optimal temperature distributions 采样。
- Sequential revisions:模型自我批评并迭代改进单个解。
- Beam search with PRMs:保留多个候选解,并用 step-level rewards 剪枝。
- Diverse beam search:鼓励探索不同 solution approaches。
对应的 verification methods 包括:
- ORMs / outcome-supervised reward models:预测最终 solution 是否正确。
- PRMs / process-supervised reward models:评估每个 reasoning step 是否正确。
- Domain-specific verifiers:对可检查问题使用特定验证器,例如代码执行。
这里要把第 10 讲 evaluation 和第 11 讲 reasoning 连起来:没有 verifier,生成更多样本可能只是更贵;有 verifier,更多 test-time samples 才能变成性能提升。
9.3 关键发现和实用结论

PPT 列出的 key findings:
- 在 MATH-500 上,一个使用优化 test-time compute 的 14B 模型,可以匹配或超过 4 倍参数量模型的表现。
- 在其实验设置里,compute-optimal strategy 大致把 FLOPs 平均分配给 pretraining 和 inference。
- Sequential revision 在需要 refinement 和 error correction 的任务上 scaling 特别强。
- 和 ORM + beam search 相比,PRM 可以带来 4 到 8 倍更高的 compute efficiency。
实用 takeaways 是:
- 不要默认选择最大模型。
- 要投资 verification。
- 高质量 reward models,尤其 PRMs,会显著改善 test-time scaling。
这也解释了为什么现代 reasoning 系统越来越像“模型 + 搜索 + verifier”的组合,而不是单个模型一次性吐答案。
10. 把四块内容串起来
这一讲的四块内容可以这样连:
- Speculative decoding 解决“生成太慢”:让快机制提出候选,让大模型验证。
- Off-policy drift 与 on-policy distillation 解决“训练分布不稳”:让数据尽量贴近当前 learner,或在系统层面减小 stale rollout。
- Long context extension 解决“推理需要更多证据和更长工作区”:扩数据、改位置编码、改 attention、做 staged training。
- Test-time compute scaling 解决“单次解码不够”:多采样、多 revision、搜索、验证。
如果第 11 讲告诉你“推理能力可以通过 RL 和 CoT 被诱发”,第 12 讲就在告诉你:要把这种能力变成可用系统,还需要速度、分布一致性、上下文长度和验证器。
11. 复习题
- Speculative decoding 为什么能加速大模型生成?它的加速依赖 draft model 的什么性质?
- 在 speculative sampling 中,为什么当 \(q_i < p_i\) 时接受概率是 \(\frac{q_i}{p_i}\)?
- Dynamic speculative decoding 的 lookahead size 为什么不应该固定?
- Universal speculative decoding 要解决什么 tokenizer 问题?
- EAGLE-3 和 suffix decoding 的最大区别是什么?
- Online RL 和 on-policy RL 是同一个概念吗?请用一句话分别定义。
- 为什么真实 RLHF/RLVR 系统会出现 off-policy drift?
- PPO clipping 和 KL penalty 分别如何缓解 off-policy 带来的不稳定?
- 为什么 on-policy distillation 使用 student-generated context 可以减轻 exposure bias?
- Forward KL 为什么是 mass-covering?Reverse KL 为什么是 mode-seeking?
- Learned positional embeddings 为什么不适合直接外推到很长上下文?
- RoPE 为什么只旋转 query/key,而不旋转 value?
- 如何从 \((R^{(m)})^\top R^{(n)} = R^{(n-m)}\) 理解 RoPE 的相对距离性质?
- Long-context extension 的四类实践分别是什么?
- Test-time compute scaling 为什么依赖 verifier?PRM 相比 ORM 多提供了什么信息?