08. 提示工程与参数高效微调
官方 PPT 来源:Lecture 9 官方 PPT:Efficient Adaptation
本页是网站中的第 8 个 CS224n 专题,内容对应官方 PPT Lecture 9: Efficient Adaptation。PPT 开头先承接上一讲的 DPO、RLHF、人类偏好数据,然后进入本页主体:prompting、chain-of-thought、parameter-efficient fine-tuning、pruning、LoRA、QLoRA、prefix tuning、prompt tuning、adapter,以及这些方法的统一视角。
本讲学习目标
学完这一讲,你应该能从零回答下面这些问题:
- GPT、GPT-2、GPT-3 的规模变化带来了哪些 emergent abilities?
- Zero-shot prompting、one-shot prompting、few-shot prompting 分别是什么?
- In-context learning 为什么不等于 gradient-based fine-tuning?
- GPT-2 的 zero-shot learning 怎样通过“把任务写成 sequence prediction problem”实现?
- Few-shot learning 为什么被 PPT 称为 model scale 的 emergent property?
- 为什么困难推理任务不能只靠普通 prompting?
- Chain-of-thought prompting 为什么能帮助多步推理?
- Zero-shot CoT 中 “Let’s think step by step” 起什么作用?
- Prompt-based learning 有哪些缺点?
- 为什么 prompt engineering 被 PPT 称为 dark art?
- Full fine-tuning 为什么在大模型时代变得不现实?
- PEFT 想解决什么问题?
- 从 parameter、input、function 三个视角怎样理解 PEFT?
- Pruning 为什么可以看成寻找 sparse subnetwork?
- Binary mask 在 pruning 中怎样作用到参数上?
- Lottery Ticket Hypothesis 的核心说法是什么?
- Full fine-tuning 的条件语言模型目标是什么?
- LoRA 为什么把更新矩阵写成低秩分解?
- LoRA 中 \(A\)、\(B\)、rank \(r\)、scale \(\alpha\) 分别是什么意思?
- LoRA 为什么可以没有额外 inference latency?
- QLoRA 相比 LoRA 多做了什么?
- Prefix tuning 和 prompt tuning 都训练什么,不训练什么?
- 为什么 prompt tuning 只在大模型规模下表现好?
- Adapter 插入在 Transformer 的哪里?它的 bottleneck 结构是什么?
- 为什么 adapter 适合任务、语言、方言适配?
- LoRA、prefix tuning、adapter 的统一视角是什么?
- Prompt tuning、adapter、LoRA 在性能和参数量之间有什么权衡?
PPT 脉络
| 部分 | PPT 内容 | 本讲义对应章节 |
|---|---|---|
| DPO/RLHF 收尾 | PPO 复杂、DPO、GRPO、偏好数据来源、preference tuning unintended impact | 1 |
| GPT 系列 emergent abilities | GPT、GPT-2、GPT-3、zero-shot、few-shot、in-context learning | 2-5 |
| Prompting 与 CoT | prompting vs fine-tuning、困难任务、chain-of-thought、zero-shot CoT、prompting sensitivity | 6-10 |
| Prompting 的缺点 | inefficiency、poor performance、prompt wording/order sensitivity、random labels | 11 |
| PEFT 动机 | full fine-tuning vs parameter-efficient fine-tuning、效率与环境成本 | 12-13 |
| 三种 PEFT 视角 | parameter、input、function | 14 |
| Sparse subnetworks | pruning、binary mask、diff pruning、lottery ticket hypothesis | 15-17 |
| LoRA / QLoRA | full fine-tuning objective、低秩更新、LoRA 实践、QLoRA、rank | 18-23 |
| Prefix / Prompt tuning | learnable prefix、virtual tokens、soft prompts、scale | 24-25 |
| Adapter | bottleneck adapter、插入位置、任务/语言/方言适配 | 26-28 |
| 统一视角与比较 | hidden representation modification、performance comparison、distillation 等其他方法 | 29-31 |
1. PPT 开头:承接 DPO、GRPO 与偏好数据
这份官方 PPT 的前 13 页延续上一讲内容,快速回顾了:
PPO 很复杂
DPO 去掉复杂 RL loop
开源 RLHF 实践很多已经转向 DPO
GRPO 是继续改进 RL 路线的方法
RLHF 标签常来自低薪海外标注劳动
标注者偏差可能进入语言模型
preference tuning 可能产生 unintended impact
这些内容已经在 07. 后训练 中详细展开。本页只记住一件事:后训练和高效适配是连接在一起的。
为什么?因为当模型很大时,我们不只是想让它“更符合偏好”,还要让它“适配得起”:
这就是 Efficient Adaptation 的背景。
2. 从 GPT 到 GPT-3:规模带来的新行为
PPT 回顾 OpenAI 的 GPT 系列,目的是引出 prompting 和 in-context learning。
2.1 GPT
GPT 是 2018 年的 Generative Pretrained Transformer。
PPT 给出的要点:
117M parameters
Transformer decoder with 12 layers
trained on BooksCorpus: over 7000 unique books, 4.6GB text
它展示了:在一定规模上做 language modeling pretraining,可以有效迁移到 downstream tasks,例如自然语言推理。
2.2 GPT-2
GPT-2 是 2019 年模型。
PPT 给出的变化:
训练数据 WebText 来自 Reddit 上至少 3 upvotes 的链接,PPT 称这是 rough proxy of human quality。
GPT-2 的一个关键 emergent ability 是 zero-shot learning。
2.3 GPT-3
GPT-3 是 2020 年模型。
PPT 给出的变化:
随着规模继续扩大,GPT-3 展示了更强的 few-shot learning,也就是在上下文里给任务示例,不更新参数也能适配任务。
3. Zero-shot Learning:把任务写成预测问题
PPT 对 GPT-2 的 zero-shot learning 给出定义:
关键做法是:
3.1 问答例子
把 question answering 写成:
语言模型接下来生成的就是答案。
没有任务特定训练,没有参数更新,只是把任务格式写进 prompt。
3.2 Winograd Schema Challenge 例子
PPT 的例子:
可以比较两个序列的概率:
如果某个序列概率更高,就把它当作模型判断。
这说明:很多任务可以被重新表述为语言模型最熟悉的形式:
4. Few-shot Learning 与 In-context Learning
GPT-3 部分讲 few-shot learning。
PPT 定义:
例如翻译任务可以写成:
模型根据前面的示例,在同一个上下文中推断任务规律,然后完成最后一个例子。
PPT 也说它叫 in-context learning,强调:
4.1 Zero-shot / one-shot / few-shot 的区别
| 方式 | Prompt 中是否给示例 | 参数是否更新 |
|---|---|---|
| Zero-shot | 不给任务示例,只给任务描述或格式 | 不更新 |
| One-shot | 给 1 个示例 | 不更新 |
| Few-shot | 给少量示例 | 不更新 |
| Fine-tuning | 用训练数据更新参数 | 更新 |
4.2 为什么它很神奇?
因为从传统机器学习角度看,“学习新任务”通常意味着更新参数。
但 in-context learning 中,模型参数不变,变化的是输入上下文。
所以它更像:
5. Few-shot Learning 是规模涌现能力
PPT 用 synthetic word unscrambling tasks 展示 few-shot learning 和模型规模的关系。
任务包括:
图中横轴是模型参数量,从 0.1B 到 175B,纵轴是 accuracy。
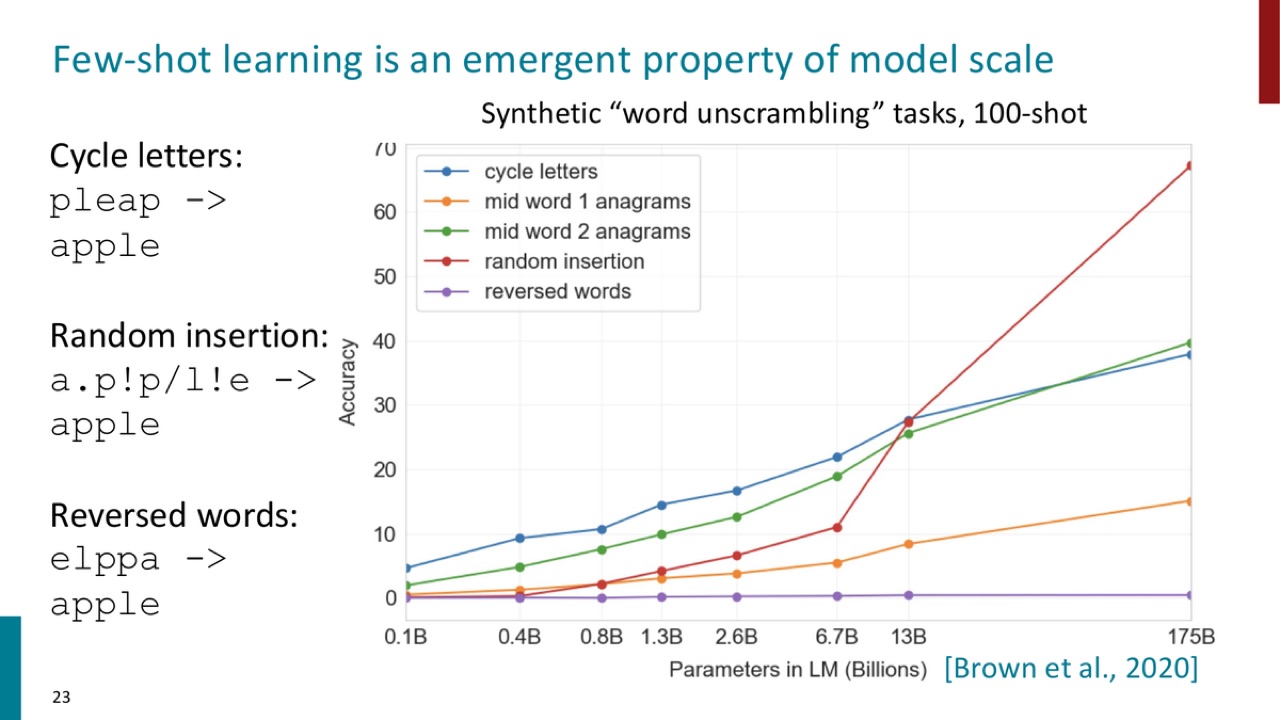
官方 PPT 截图:在 synthetic word unscrambling 任务中,few-shot learning 表现随模型参数规模变化而出现明显提升,因此 PPT 将其称为 model scale 的 emergent property。
这张图想表达的是:不是所有模型都自然有强 in-context learning。模型规模增大之后,一些任务上的 few-shot 能力才明显出现。
6. Prompting 与 Fine-tuning 的边界
PPT 用一页图对比:
Prompting 的特点:
Fine-tuning 的特点:
二者不是谁完全替代谁,而是不同成本和效果的选择。
6.1 Prompting 适合什么?
Prompting 适合:
6.2 Fine-tuning 适合什么?
Fine-tuning 更适合:
7. 为什么困难任务不能只靠普通 Prompting?
PPT 提出:
尤其是 richer, multi-step reasoning。
PPT 给了多位数加法例子:
这种任务需要中间计算步骤。
如果 prompt 只给输入输出对,模型可能学到表面模式,但没有稳定展开多步计算。
PPT 给出的方向是:
这引出 chain-of-thought prompting。
8. Chain-of-Thought Prompting
Chain-of-thought prompting 的基本想法是:
这给模型提供了更长的“计算轨迹”。
PPT 展示了 middle school math word problems,并指出 CoT prompting 也是 model scale 的 emergent property。
8.1 CoT 的直觉
普通回答:
CoT 回答:
后者把多步推理显式写入输出序列。
对于自回归语言模型来说,中间步骤一旦生成出来,就会成为后续 token 的上下文,帮助后续答案更一致。
9. Zero-shot Chain-of-Thought
PPT 接着问:
Zero-shot CoT 的典型提示是:

官方 PPT 截图:zero-shot CoT 不提供人工推理示例,只在回答前加入 “Let’s think step by step”,诱导模型生成中间步骤。
PPT 的例子:
9.1 Zero-shot CoT 的效果
PPT 还展示结果表:zero-shot CoT 明显优于普通 zero-shot,但 manual CoT 仍然更好。

官方 PPT 截图:zero-shot CoT 在 MultiArith 和 GSM8K 上显著超过普通 zero-shot;不过人工设计的 few-shot CoT 仍然更强。
学习重点:
10. Prompt Engineering 为什么像 Dark Art?
PPT 展示 prompting 的 sensitivity and inconsistency:
随后用 “dark art of prompt engineering” 形容实践中的混乱性。
例子包括:
PPT 的重点不是教具体 prompt 技巧,而是提醒:
这会让 prompting 难以稳定控制。
11. Prompt-based Learning 的缺点
PPT 列出四个 downside。

官方 PPT 截图:prompt-based learning 的缺点包括每次都要处理 prompt、通常不如 fine-tuning、对措辞和示例顺序敏感,以及模型到底从 prompt 中学到了什么并不清楚。
11.1 Inefficiency
Prompt 每次预测都要被处理。
如果 prompt 很长,few-shot 示例很多,那么每次推理都要重复计算这些上下文。
11.2 Poor Performance
PPT 说,prompting generally performs worse than fine-tuning。
这不是说 prompting 没用,而是说如果有任务数据和训练资源,fine-tuning 往往能更深地适配任务。
11.3 Sensitivity
Prompt 的措辞、示例顺序等都会影响结果。
这也是 prompt engineering 难以系统化的原因。
11.4 Lack of Clarity
PPT 说,就连 random labels 有时也能 work。
这说明模型从 prompt 中利用了什么信号,并不总是清楚。
12. 从 Fine-tuning 到 PEFT
Prompting 有局限,而 full fine-tuning 又太贵。
PPT 因此进入:
Full fine-tuning:
Parameter-efficient fine-tuning:
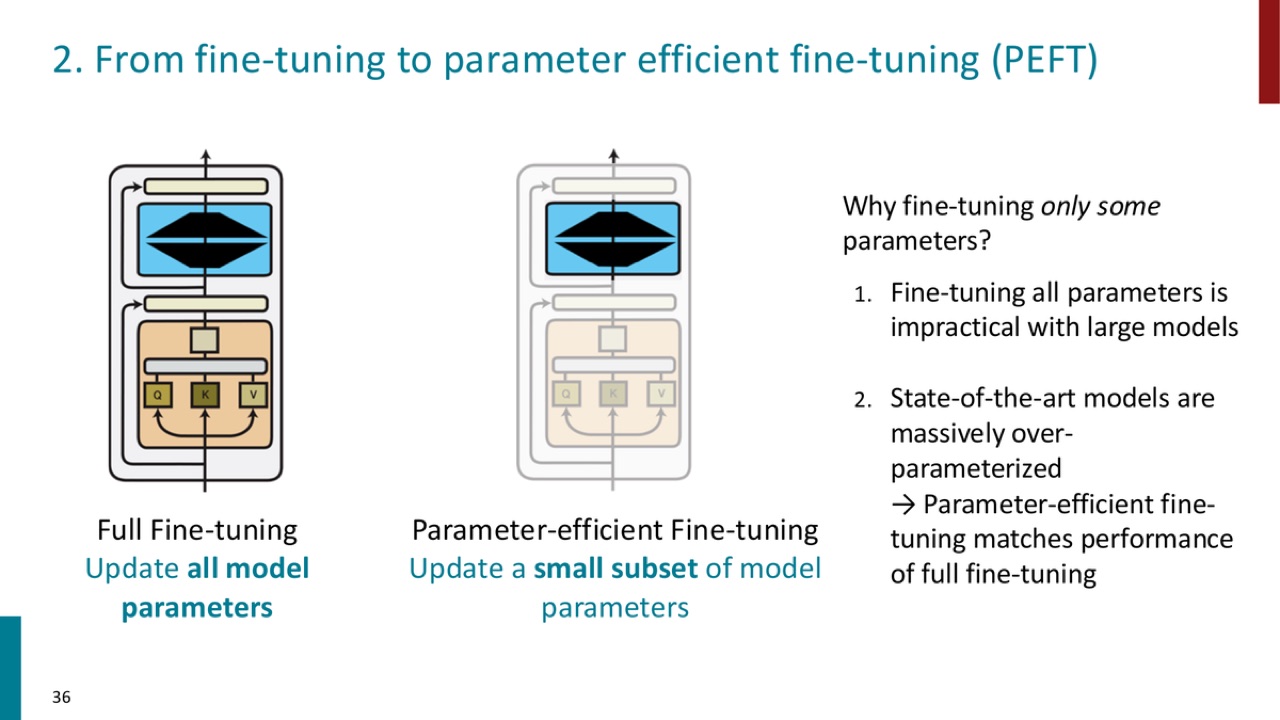
官方 PPT 截图:full fine-tuning 更新全部模型参数;PEFT 只更新一小部分参数,并希望匹配 full fine-tuning 的性能。
12.1 为什么不直接 full fine-tuning?
PPT 给出两个理由。
第一:
大模型参数量巨大,训练所有参数需要大量显存、计算和存储。
第二:
如果模型有大量冗余参数,也许不必更新全部参数就能适配新任务。
13. 为什么要 Efficient Adaptation?
PPT 还从更广的角度解释 efficient adaptation。
当前 AI 范式更重视 accuracy,而不够重视 efficiency。
PPT 提到:
以及:
这说明 PEFT 不只是工程省钱技巧,也是降低进入门槛和资源成本的方向。
PPT 还举了 CS234 作业能耗的例子:如果 200 多名学生都使用更高效算法,总耗电量可以减少 880 kilowatt-hours,约等于典型美国家庭一个月用电量。
学习重点:
14. 理解 PEFT 的三种视角
PPT 给出三个视角:
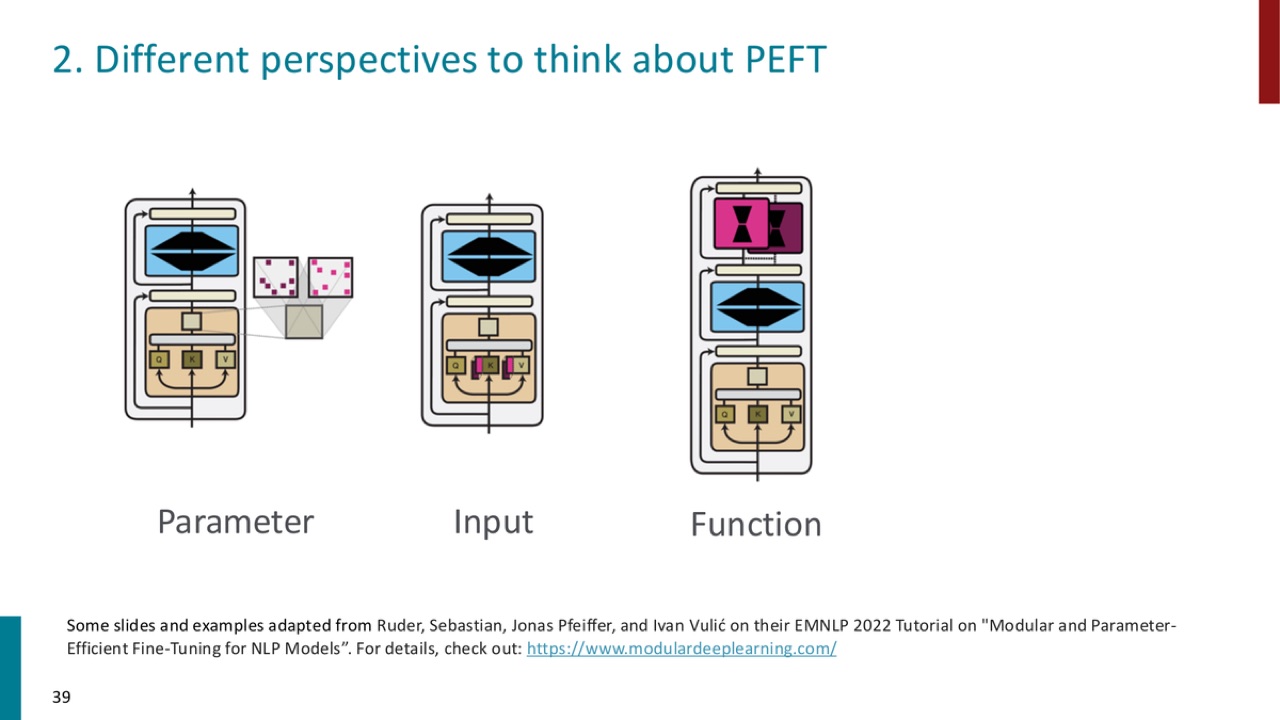
官方 PPT 截图:PEFT 可以从 parameter、input、function 三个视角理解。LoRA 属于低秩参数更新,prefix/prompt tuning 属于输入侧适配,adapter 属于函数/模块适配。
14.1 Parameter Perspective
从参数角度看:
PPT 下面讲 pruning 和 LoRA。
14.2 Input Perspective
从输入角度看:
PPT 下面讲 prefix tuning 和 prompt tuning。
14.3 Function Perspective
从函数角度看:
PPT 下面讲 adapters。
15. Sparse Subnetworks 与 Pruning
Parameter perspective 的第一类是 sparse subnetworks。
PPT 说,常见 inductive bias 是 sparsity,也就是认为任务适配只需要模型的一部分连接。
最常见 sparsity method 是 pruning。
15.1 Pruning 的基本步骤
PPT 说:
During pruning, a fraction of the lowest-magnitude weights are removed.
The non-pruned weights are re-trained.
Pruning for multiple iterations is more common.
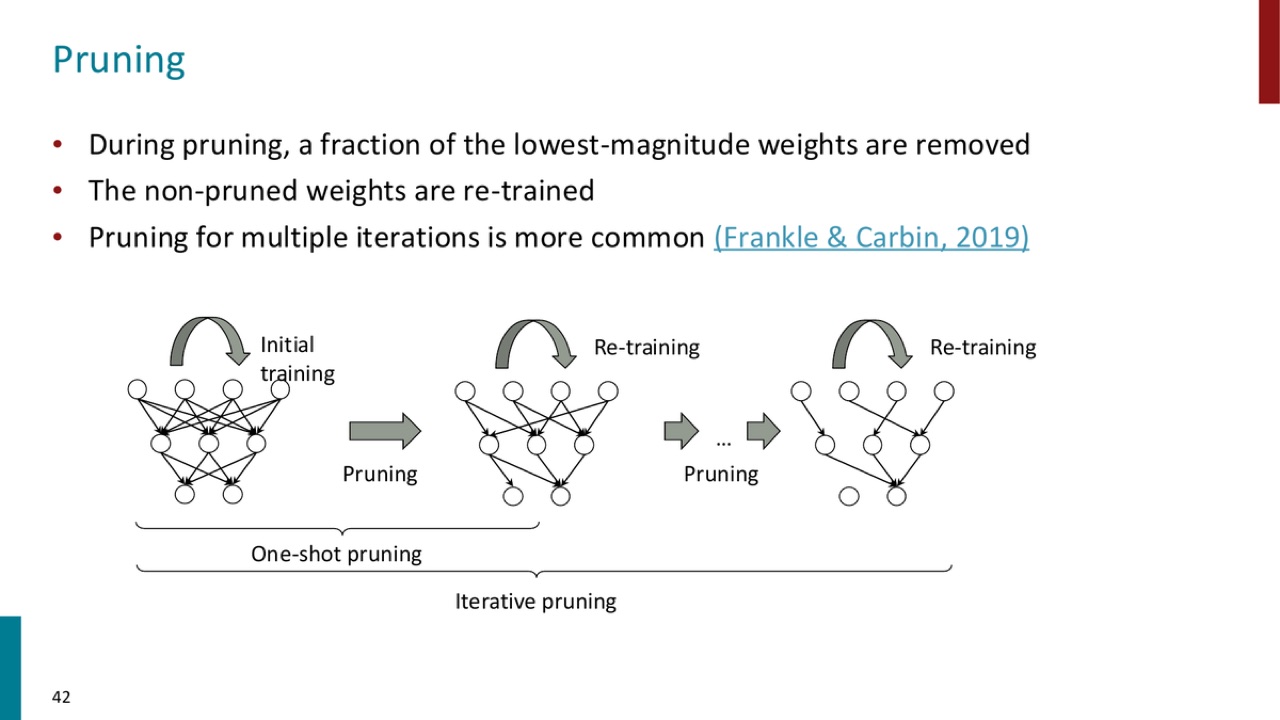
官方 PPT 截图:pruning 会删除低幅值权重,再训练未剪枝权重;多轮 iterative pruning 比 one-shot pruning 更常见。
15.2 为什么用 magnitude?
PPT 说最常见 pruning criterion 是 weight magnitude。
直觉:
这只是常见准则,不代表所有小权重都一定没用。
16. Binary Mask 视角
PPT 说 pruning 可以看成对参数应用 binary mask:
如果 \(b_i=1\),保留第 \(i\) 个连接。
如果 \(b_i=0\),移除第 \(i\) 个连接。
PPT 还说,可以把 task-specific vector \(\phi\) 加到已有模型参数上:
其中如果 \(b_i=0\),则:
如果最终模型应当稀疏,则可以写成:
这里 \(\circ\) 是 element-wise product,也就是 Hadamard product。
16.1 Diff Pruning
PPT 提到 diff pruning:
perform pruning only based on the magnitude of module parameters phi
rather than the updated theta + phi parameters
直觉是:只看任务特定增量 \(\phi\) 的重要性,而不是看原始参数加增量后的总参数。
17. Lottery Ticket Hypothesis
PPT 介绍 Lottery Ticket Hypothesis:
dense, randomly-initialized models contain subnetworks
that, when trained in isolation,
reach test accuracy comparable to the original network
in a similar number of iterations
这些子网络被称为 winning tickets。
PPT 还说:
并给出 sparsity ratios:
学习重点:
18. Full Fine-tuning 的目标函数
进入 LoRA 前,PPT 先回顾 full fine-tuning。
设有一个 pretrained autoregressive language model:
例如 GPT based on Transformer。
下游任务数据是 context-target pairs:
Full fine-tuning 会把原参数:
更新为:
通过最大化 conditional language modeling objective:
18.1 Full fine-tuning 的问题
PPT 用 GPT-3 作为例子:
如果每个下游任务都学习一整套 \(\Delta \phi\),那么:
LoRA 的问题就是:
19. LoRA:Low-Rank Adaptation
LoRA 的关键想法:
PPT 写:
并且:
于是优化目标变成:
19.1 低秩更新矩阵
PPT 设一个 pretrained weight matrix:
LoRA 限制更新为低秩分解:
其中:
只有 \(A\) 和 \(B\) 包含可训练参数。
![]()
官方 PPT 截图:LoRA 冻结原始权重 \(W_0\),只训练低秩矩阵 \(A\) 和 \(B\),用 \(\alpha BA\) 表示任务特定更新。
19.2 为什么参数会少?
如果直接训练完整 \(\Delta W\),参数量是:
LoRA 只训练:
因为 \(r\) 很小,所以参数量大幅减少。
例如如果 \(d=k=4096\),完整矩阵约有 16.8 million 参数。
如果 \(r=8\),LoRA 参数约为:
也就是约 65 thousand 参数。
这就是低秩适配的核心收益。
19.3 \(\alpha\) 的含义
PPT 说:
也就是 \(\alpha\) 控制低秩更新对原模型的影响强度。
20. LoRA 的实践细节
PPT 补充:
As one increase the number of trainable parameters,
training LoRA converges to training the original model.
也就是说,rank 越大,可训练自由度越多,LoRA 越接近 full fine-tuning。
但 LoRA 的目标不是无限增大 rank,而是在很小 rank 下获得接近 full fine-tuning 的效果。
20.1 没有额外 inference latency
PPT 说 LoRA 没有额外 inference latency。
原因是推理时可以把:
合并成一个权重矩阵使用。
切换任务时,可以恢复 \(W_0\),再加上另一个任务的 \(B'A'\)。
20.2 通常加在哪里?
PPT 说:
例如 attention 中的 \(W_q\)、\(W_k\)、\(W_v\)、\(W_o\)。
![]()
官方 PPT 截图:LoRA 可以应用到 Transformer 中不同权重矩阵;PPT 展示了 target matrices 和 rank \(r\) 的选择会影响表现,小 rank 也可以有竞争力。
21. LoRA 的效果与规模
PPT 展示:
并总结:
LoRA matches or exceeds the fine-tuning baseline on all three datasets.
LoRA exhibits better scalability and task performance.
PPT 后面还展示了 LoRA 在 RL 中 rank 很低时也能接近 full fine-tuning:
学习重点:
22. QLoRA:量化后的 LoRA
PPT 接着讲 QLoRA。
QLoRA 在 LoRA 基础上进一步降低显存需求。
PPT 说:
QLORA improves over LoRA by quantizing the transformer model to 4-bit precision
and using paged optimizer to handle memory.
还提到:
这是为 normally distributed weights 设计的数据类型。
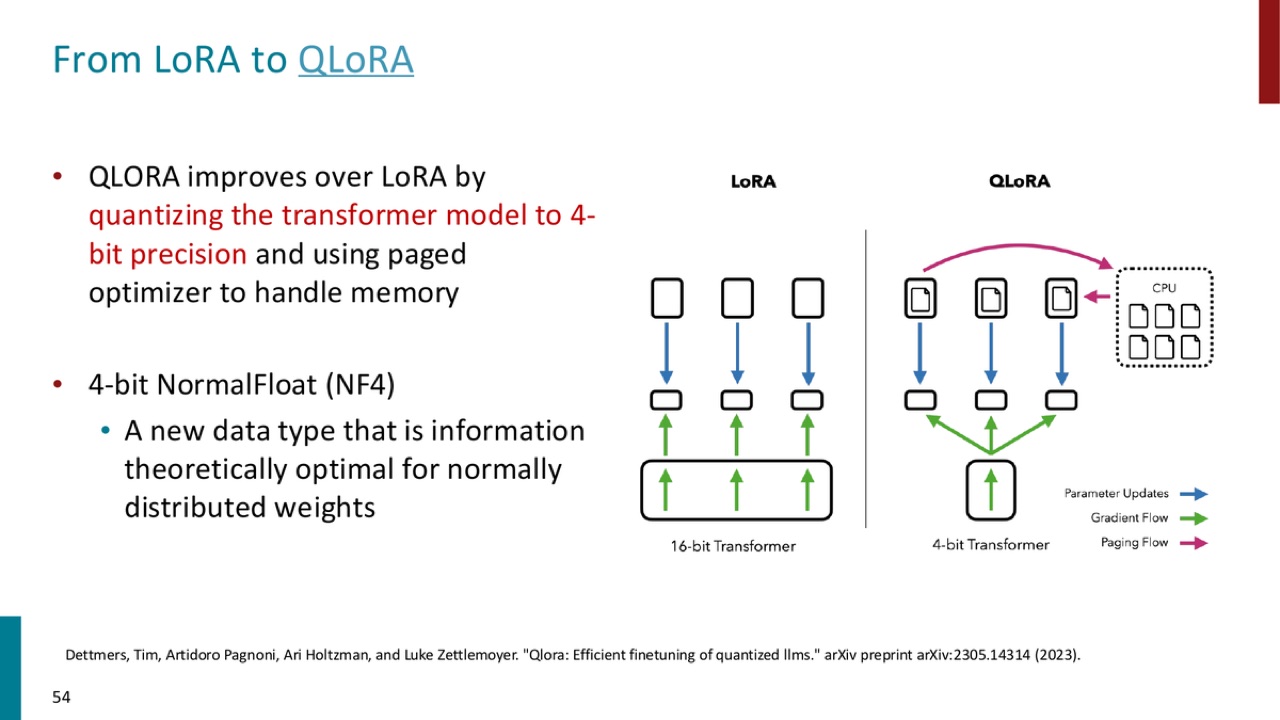
官方 PPT 截图:QLoRA 把 Transformer 主体量化到 4-bit,并用 paged optimizer 处理内存,从而在 LoRA 基础上进一步降低适配大模型的成本。
22.1 LoRA 与 QLoRA 的关系
LoRA 解决:
QLoRA 进一步解决:
它们不是互斥方法,而是叠加关系。
23. Input Perspective:Prefix / Prompt Tuning
PEFT 的第二个视角是 input perspective。
核心思想:
PPT 图中称它们为 learnable prefix parameters。
24. Prefix Tuning
Prefix tuning 的做法:
PPT 说,prefix 是一串连续的 task-specific vectors,模型像处理真实词一样处理它们,因此它们也叫 virtual tokens。
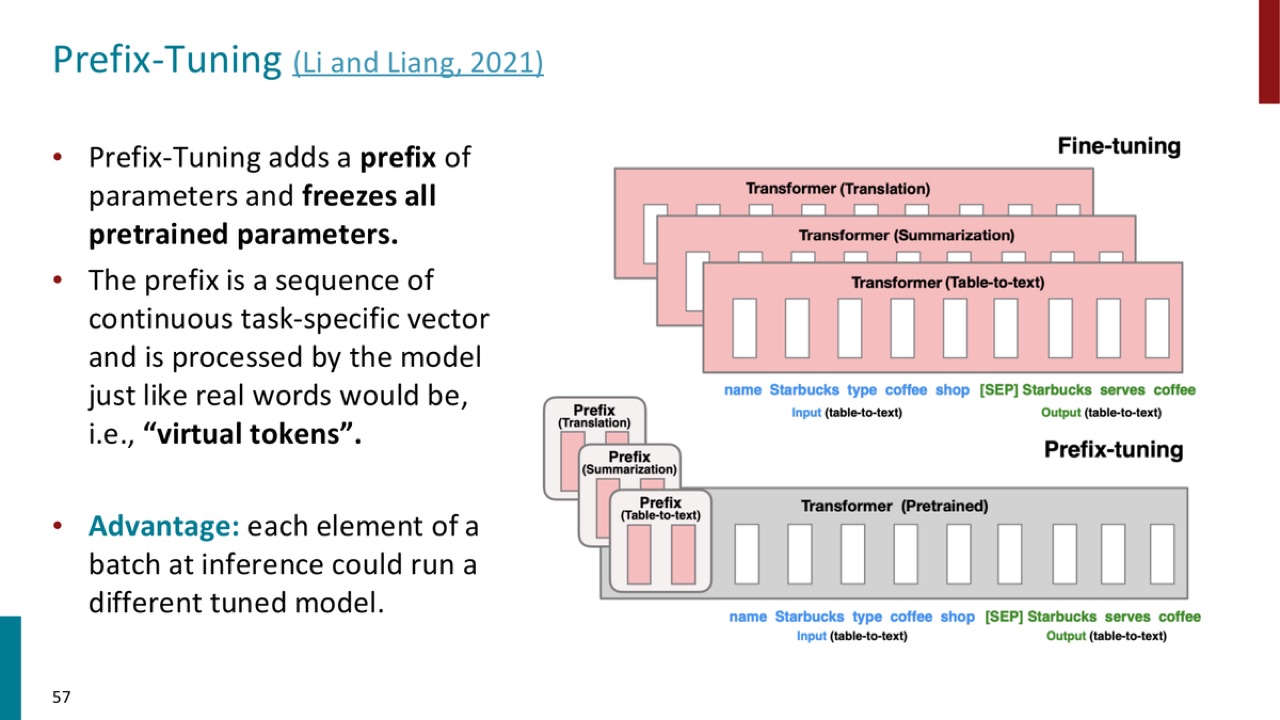
官方 PPT 截图:prefix tuning 冻结预训练 Transformer,只为不同任务学习不同 prefix;这些 prefix 是连续向量,被模型当作 virtual tokens 处理。
24.1 Prefix tuning 的优势
PPT 给出的 advantage:
因为主体模型相同,只是 prefix 不同,所以可以在同一个 batch 中让不同样本使用不同任务的 prefix。
25. Prompt Tuning
Prompt tuning 和 prefix tuning 类似,也属于 input perspective。
PPT 定义:
做法:
也就是说,prompt tuning 学的是连续向量,不是人工写的离散文字 prompt。
25.1 Prompt tuning 只在大模型规模下效果好
PPT 明确说:
它还说:
直觉是:小模型表达能力有限,仅靠几个 soft prompt 很难改变行为;大模型已有强能力,soft prompt 更像是在激活和引导已有能力。
26. Function Perspective:Adapter
第三个视角是 function perspective。
PPT 说:
Adapter 就是在预训练模型层之间插入新的小函数:
只训练这些新增模块,主体模型可以冻结。
27. Adapter 的结构
PPT 说,Transformer layer 中的 adapter 包含:
- feed-forward down-projection:
- nonlinearity:
- feed-forward up-projection:
Adapter 函数:
这里通常 \(k\) 比 \(d\) 小,所以是 bottleneck design。
27.1 Adapter 插在哪里?
PPT 说 adapter 通常放在:
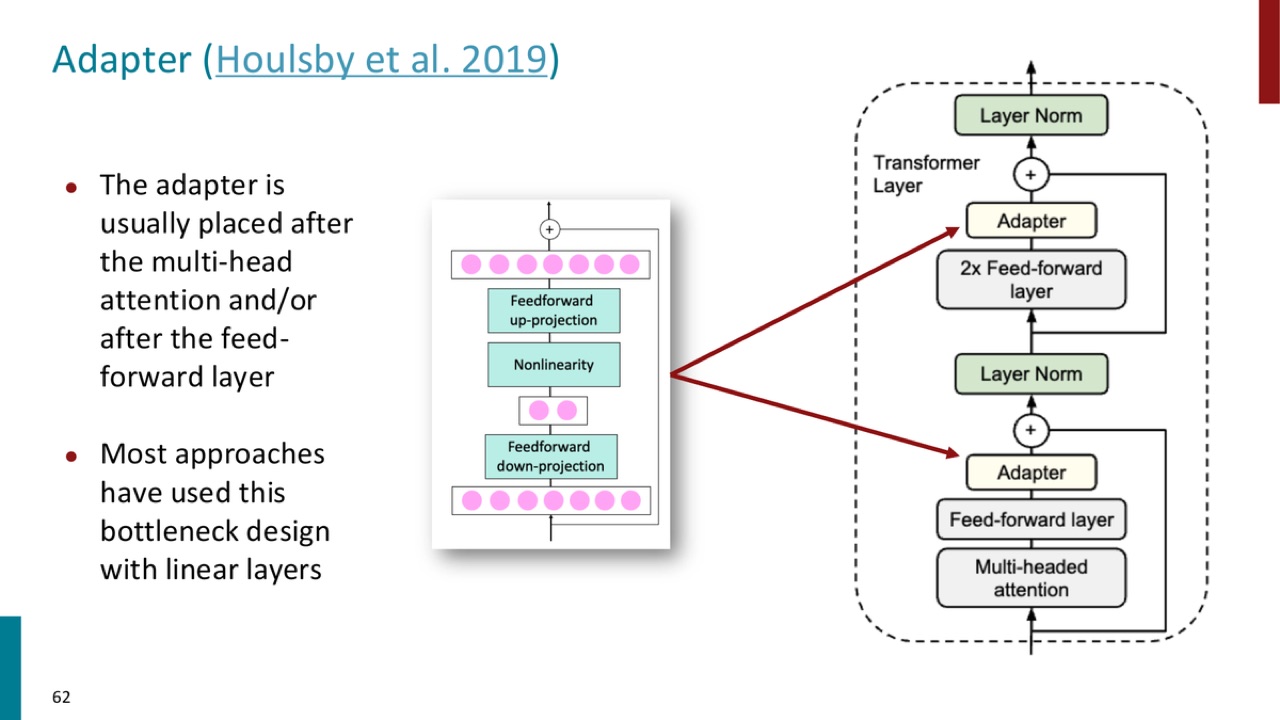
官方 PPT 截图:adapter 通常插在 Transformer 层中的 multi-head attention 后或 feed-forward 后,使用 down-projection、nonlinearity、up-projection 的 bottleneck 结构。
28. Adapter 的效果与用途
PPT 展示 GLUE benchmark 上的 trade-off:
Adapter based tuning attains a similar performance to full finetuning
with two orders of magnitude fewer trained parameters.
这就是 adapter 的价值:
28.1 Language adapters
PPT 还提出:
Adapters 学到的是让底层模型更适合某个任务或语言的 transformation。
例如可以用 masked language modeling 学 English 和 Quechua 的 language-specific transformations。
28.2 English dialect adaptation
PPT 展示:
意思是:对于在 Standard American English 上训练的 LLM,可以用 adapters 适配不同 English dialects。
这说明 adapter 不只用于任务,也可用于语言和方言适配。
29. 统一视角:都在修改 hidden representation
PPT 引用 He et al. 2022:
它们都可以看成修改模型 hidden representation:
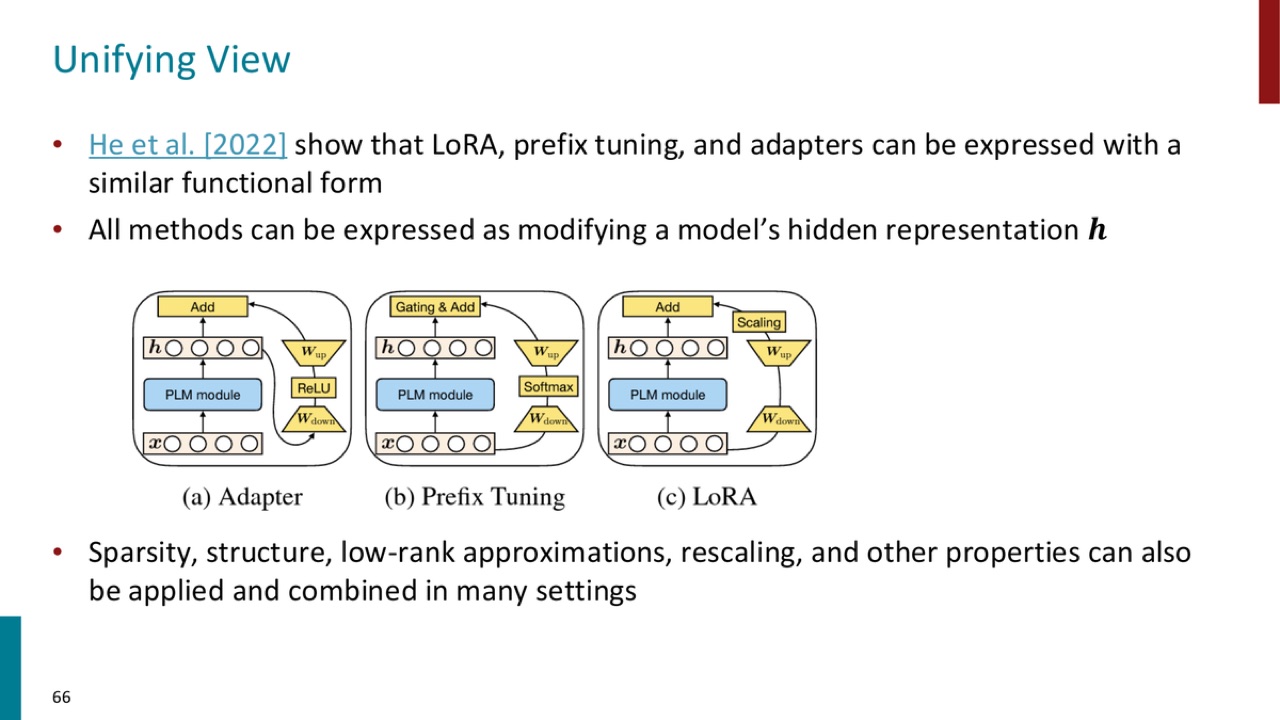
官方 PPT 截图:adapter、prefix tuning、LoRA 都可以表达为对模型 hidden representation \(h\) 的修改,只是修改方式不同。
29.1 统一视角如何帮助记忆?
不要把每个 PEFT 方法看成完全无关的技巧。
它们都在做同一件事:
区别在于在哪里加这个结构:
30. Performance Comparison:参数量与性能权衡
PPT 的最后比较指出:
Prompt tuning underperforms the other methods due to limited capacity.
Adapter achieves better performance but add more parameters.
这给出一个实用选择逻辑:
| 方法 | 参数量 | 表达能力 | 常见直觉 |
|---|---|---|---|
| Prompt tuning | 很少 | 较有限 | 轻量,但能力受限 |
| Prefix tuning | 少量 prefix 参数 | 比纯 prompt 更强 | 输入侧控制 |
| LoRA | 少量低秩参数 | 强,常用 | 适配权重更新 |
| Adapter | 增加模块参数 | 强 | 模块化、多任务/语言适配 |
31. 其他高效适配方法
PPT 最后一页提到 other variants of efficient adaptation。
其中包括:
也就是 teacher-student framework。
还提到:
PPT 没有展开这些方法,所以本页只记录它们属于 efficient adaptation 的扩展方向,不额外补充非官方细节。
32. 方法总表
| 方法 | 改哪里 | 冻结基础模型吗 | 可训练参数 | 适合记忆方式 |
|---|---|---|---|---|
| Prompting | 输入文字 | 是 | 0 | 用自然语言上下文调用模型 |
| CoT Prompting | 输出推理路径 | 是 | 0 | 让模型先写中间步骤 |
| Full Fine-tuning | 全部参数 | 否 | 全部模型参数 | 性能强但成本高 |
| Pruning | 稀疏子网络 | 可与微调结合 | mask 或剩余权重 | 找有效连接 |
| LoRA | 权重低秩增量 | 通常冻结 \(W_0\) | \(A,B\) | 低秩更新 |
| QLoRA | 量化基础模型 + LoRA | 冻结量化模型 | LoRA 参数 | 降显存 |
| Prefix Tuning | prefix vectors | 是 | prefix 参数 | virtual tokens |
| Prompt Tuning | soft prompt embeddings | 是 | prompt embeddings | 学连续 prompt |
| Adapter | 层间小模块 | 通常冻结主体 | adapter 参数 | 插入 bottleneck function |
33. 公式小抄
33.1 Full Fine-tuning
更新全部模型参数 \(\phi\)。
33.2 LoRA
只训练 \(A\) 和 \(B\)。
33.3 Pruning Mask
\(\circ\) 是 element-wise product。
33.4 Adapter
先降维,再非线性,再升维。
34. 常见误区
34.1 误区:Prompting 就等于模型学会了任务
不完全对。
Prompting 中没有参数更新。模型是在上下文中识别和延续任务格式,而不是通过梯度把任务写进参数。
34.2 误区:Few-shot 一定比 zero-shot 好
不一定。
PPT 讲 prompting sensitivity:示例选择、顺序、措辞都可能影响结果。Few-shot 示例如果误导模型,也可能效果不好。
34.3 误区:CoT 只是让回答更长
不是。
CoT 的重点是生成中间推理步骤,让后续答案依赖这些中间状态。它改变的是生成路径,而不是单纯加字数。
34.4 误区:PEFT 一定比 full fine-tuning 强
不是。
PEFT 的目标是在少量参数下接近 full fine-tuning,降低成本。它不是理论上总是更强。
34.5 误区:LoRA 改的是输入 prompt
不是。
LoRA 是 parameter perspective,改的是权重更新形式。Prompt tuning 和 prefix tuning 才是 input perspective。
34.6 误区:Adapter 和 LoRA 是完全无关的技巧
PPT 的统一视角说明,adapter、prefix tuning、LoRA 都可以看成修改 hidden representation \(h\),只是插入位置和参数化形式不同。
35. 自学路线
第一次学本讲,可以按下面路线:
- 先理解 zero-shot / few-shot / in-context learning:不更新参数,只改上下文。
- 再理解 CoT:让模型显式生成推理步骤。
- 接着看 prompting 的缺点:成本、性能、敏感性、不透明。
- 转到 PEFT:为什么 full fine-tuning 大模型太贵。
- 用三视角组织 PEFT:parameter、input、function。
- 学 pruning:通过 mask 找 sparse subnetwork。
- 重点学 LoRA:低秩更新公式和参数量优势。
- 学 QLoRA:量化基础模型,继续降低显存。
- 学 prefix/prompt tuning:训练 virtual tokens。
- 学 adapter:插入小 bottleneck 模块。
- 最后用统一视角把 LoRA、prefix tuning、adapter 放回 hidden representation modification。
36. 自测题
- GPT-2 的 zero-shot learning 为什么不需要任务特定参数更新?
- Few-shot prompting 和 gradient-based few-shot learning 的区别是什么?
- In-context learning 中“学习”发生在什么地方?
- 为什么 few-shot learning 被 PPT 称为 emergent property of model scale?
- Chain-of-thought prompting 解决普通 prompting 的什么问题?
- Zero-shot CoT 的关键提示是什么?
- PPT 列出的 prompt-based learning 四个缺点是什么?
- Full fine-tuning 为什么在大模型时代成本高?
- PEFT 的核心目标是什么?
- PEFT 的 parameter、input、function 三个视角分别对应哪些方法?
- Pruning 为什么可以用 binary mask 表示?
- Lottery Ticket Hypothesis 说 dense model 中可能存在什么?
- Full fine-tuning 的条件语言模型目标是什么?
- LoRA 中 \(W_0+\Delta W=W_0+\alpha BA\) 各部分含义是什么?
- 为什么 LoRA 的参数量比完整 \(\Delta W\) 少?
- LoRA 为什么可以没有额外 inference latency?
- QLoRA 相比 LoRA 多了什么?
- Prefix tuning 中 virtual tokens 是什么?
- Prompt tuning 为什么只训练 soft prompt embeddings?
- Adapter 的 down-projection 和 up-projection 各起什么作用?
- Adapter 通常插在 Transformer 的哪些位置?
- Language adapters 和 dialect adapters 说明 adapter 可以适配什么?
- LoRA、prefix tuning、adapter 的统一视角是什么?
- 为什么 prompt tuning 可能因 limited capacity 表现不如其他方法?
- Knowledge distillation 在本讲最后属于哪类方向?
37. 自测题答案
- 因为它把任务写成 sequence prediction problem,让语言模型用已有分布继续生成或比较序列概率,不做梯度更新。
- Few-shot prompting 只在上下文里给示例,不更新参数;gradient-based few-shot learning 会用少量样本更新模型参数。
- 发生在上下文条件化中:模型根据 prompt 中的示例识别任务模式,并按该模式继续生成。
- PPT 的 synthetic word unscrambling 图显示,随着模型参数规模增大,few-shot 表现明显提升。
- 普通 prompting 对多步推理任务困难;CoT 让模型生成中间步骤,给后续答案提供计算轨迹。
- “Let’s think step by step.”
- Inefficiency、poor performance、sensitivity to wording/order、lack of clarity regarding what the model learns from the prompt。
- 因为大模型参数量巨大,更新所有参数需要大量显存、计算和存储;每个任务保存完整模型副本也很昂贵。
- 只训练少量任务特定参数,同时尽量接近 full fine-tuning 的性能。
- Parameter:pruning、LoRA;input:prefix tuning、prompt tuning;function:adapter。
- Binary mask \(b_i\) 为 1 表示保留权重,为 0 表示剪掉权重,因此可以把剪枝写成 element-wise product。
- 存在 winning tickets,也就是单独训练也能达到接近原模型性能的稀疏子网络。
- 最大化 \(\sum_{(x,y)}\sum_t \log P_{\phi}(y_t\mid x,y_{<t})\)。
- \(W_0\) 是冻结的预训练权重,\(\Delta W\) 是任务更新,\(B\) 和 \(A\) 是低秩可训练矩阵,\(\alpha\) 控制任务更新强度。
- 完整更新需要 \(d\times k\) 参数;LoRA 只需要 \(d\times r+r\times k\),而 \(r\ll \min(d,k)\)。
- 推理时可以把 \(\alpha BA\) 合并进 \(W_0\),形成单个有效权重矩阵。
- QLoRA 把 Transformer 主体量化到 4-bit,并使用 paged optimizer 处理内存。
- 它们是一串连续 task-specific vectors,被模型像真实词一样处理,但不是离散自然语言 token。
- 因为基础 LM 冻结,任务信息被压进可学习的 soft prompt embeddings。
- Down-projection 把高维表示压到低维瓶颈,up-projection 再映射回原维度;中间加非线性。
- 通常放在 multi-head attention 后,和/或 feed-forward layer 后。
- 可以适配任务、语言,也可以适配不同 English dialects。
- 它们都可以表示为对模型 hidden representation \(h\) 的修改。
- 因为 prompt tuning 只训练少量 soft prompt,表达能力有限,PPT 比较中因此 underperforms。
- 属于 other variants of efficient adaptation,用 teacher-student framework 获得更小模型。