10. 基准测试与评测
官方 PPT 来源:Lecture 11 官方 PPT:Evaluation
这一页对应站点第 10 个正式课堂主题,来源是 CS224n Winter 2026 的官方 Lecture 11。不要把“评测”理解成课后算一个分数,它实际上决定了模型研究会朝哪里走:谁上榜、谁被认为更强、谁拿到更多关注,往往都由 benchmark 和 metric 塑造。
0. 这一讲要学会什么
学完这一讲,你应该能回答五个问题:
- 为什么 benchmark 和 leaderboard 能推动 NLP 进步,也会很快失效?
- 一个好的 benchmark 需要满足哪些条件,为什么“题多”不等于“题好”?
- 为什么很多模型会在 benchmark 上“答对但理由错”?
- BLEU、ROUGE、BERTScore、人类评测、LLM-as-a-judge 分别适合什么,不适合什么?
- 为什么数据污染、Goodhart's law 和 prompt formatting 会让 LLM 评测变得不可靠?
PPT 的整体脉络可以压缩成一句话:

1. Benchmark、Metric、Leaderboard 不是一回事
先把三个词分清:
- Benchmark:一组任务和数据,用来测某类能力。比如阅读理解、自然语言推理、多学科问答、数学推理、开放生成。
- Metric:把模型输出变成分数的规则。比如 accuracy、F1、BLEU、BERTScore、人类偏好胜率。
- Leaderboard:把很多模型在同一个 benchmark 和 metric 下的结果排序。
这三者会互相影响。一个 leaderboard 一旦有影响力,研究者就会优化它;优化久了,benchmark 会被模型“吃透”,分数会饱和,甚至可能被训练数据污染。PPT 用“benchmark 爆炸式增长、保质期变短、人类不再是性能天花板”来概括最近 LLM 评测的变化。
对初学者最重要的判断是:一个分数只说明模型在某个数据、某个提示格式、某个评分脚本下表现如何,不自动等于模型真正理解了任务。
2. 从 GLUE 到 HLE:benchmark 越来越难,也越来越脆弱
PPT 先回顾了一批常见 benchmark。它们不是同一种东西,而是在不同阶段被用来回答不同问题。
2.1 GLUE 和 SuperGLUE:标准化语言理解
GLUE 和 SuperGLUE 把多个已有语言理解任务重新整理成统一评测。SuperGLUE 包含 BoolQ、MultiRC、CB、RTE、COPA、ReCoRD、WiC、WSC 等任务,覆盖常识推理、词义消歧、指代消解、文本蕴含等能力。

这类 benchmark 的贡献是“标准化”:大家终于能在同一组任务上比较模型。但它的局限也很明显:任务本身仍然是有限的,模型刷高分后,不代表它拥有开放世界的可靠推理能力。
2.2 MMLU:从语言理解到多学科知识
MMLU 把评测扩展到 57 个学科任务,难度覆盖高中到大学水平。它不再只是问模型能不能理解一句话,而是问模型是否掌握大量学科知识。
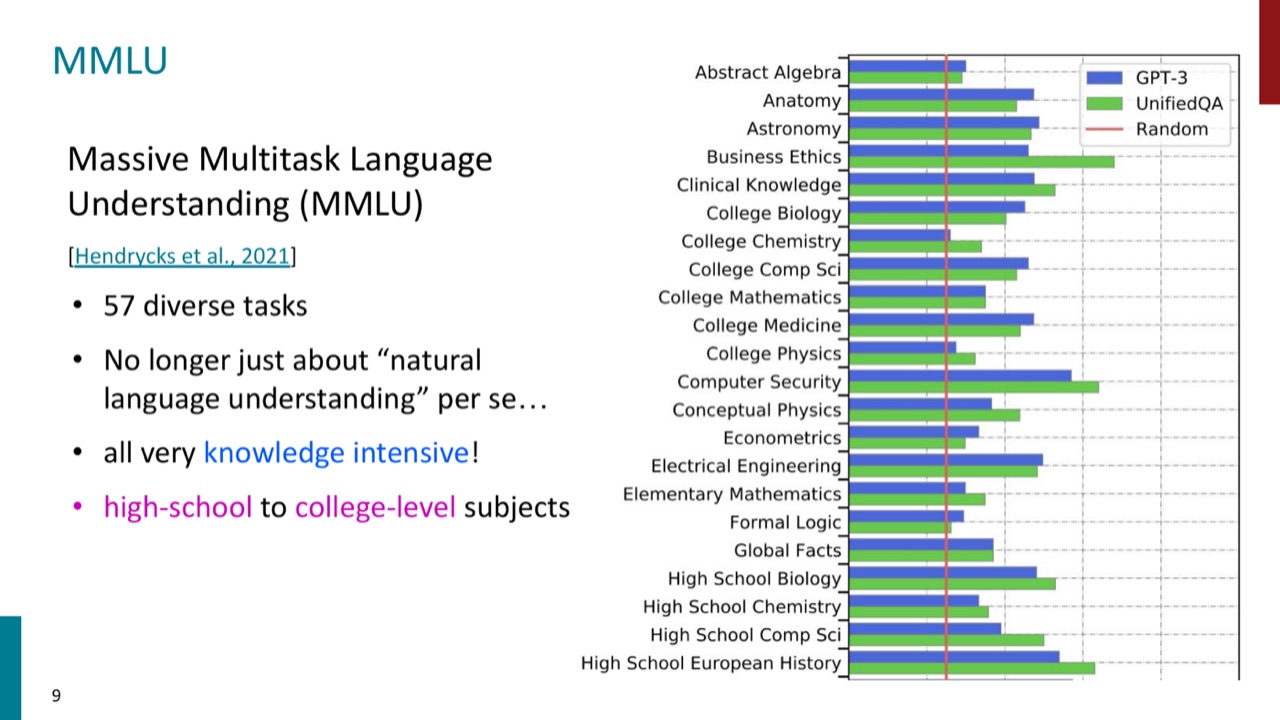
这也是为什么 MMLU 常被用于观察预训练和后训练阶段的模型能力变化。不过,知识类 benchmark 的风险是:题目公开后,训练语料可能包含测试题,模型高分可能来自记忆,而不是泛化。
2.3 GPQA 与 HLE:把题目推向专家难度
GPQA 强调 graduate-level 和 Google-proof,也就是研究生级别、不能靠简单搜索直接回答的问答。PPT 提到,GPQA 在 2023 年发布时看起来很难,但到 2024 年已有模型达到很高表现。
HLE,Humanity's Last Exam,则进一步把评测推向更高难度的知识和推理题。这个趋势说明:当模型越来越强,benchmark 必须持续更新,否则很快失去区分度。

3. 好 benchmark 的三个核心要求
PPT 对高影响力 benchmark 的要求可以整理为三类:覆盖、难度、质量。
3.1 Scale and diversity:要覆盖你声称要测的现象
如果 benchmark 声称评测“阅读理解”,就不能只测短句里的词面匹配;如果声称评测“数学推理”,就不能只测模板化加减乘除。复杂能力通常由很多子能力组成,所以样本需要足够多、类型需要足够多样。
规模不是越大越好。规模大的坏数据只会让分数更稳定地误导我们。真正有价值的是:样本覆盖了关键现象,并且每类样本足够多,能让模型不能靠一个捷径过关。
3.2 Difficulty:对人类足够清楚,对模型足够困难
一个题目如果人类专家也无法判断正确答案,它不适合做可靠 benchmark。一个题目如果最弱的模型都能轻松答对,它也没有区分度。
所以好 benchmark 需要一个平衡:对人或专家来说答案明确,对当前强模型来说仍有挑战。
3.3 Quality:答案必须真的对,不能靠伪相关取胜
质量问题包括:
- 标准答案是否真的正确。
- 题目是否存在多种合理答案却只接受一种。
- 数据是否包含标注者习惯造成的表面线索。
- 模型是否可以不理解任务,仅靠词面重叠、位置、否定词、实体替换等捷径得分。
PPT 的提醒很尖锐:AI 可能“考试做对了,但原因完全错了”。评测设计如果不检查这种情况,就会把虚假的能力当成真实进步。
4. SQuAD 的例子:大数据集也会有捷径
SQuAD 1.0 是经典阅读理解 benchmark,包含十万级人工问题,答案是文章中的文本 span。SQuAD 2.0 加入了不可回答问题,让模型不仅要找答案,还要判断“文章里没有答案”。
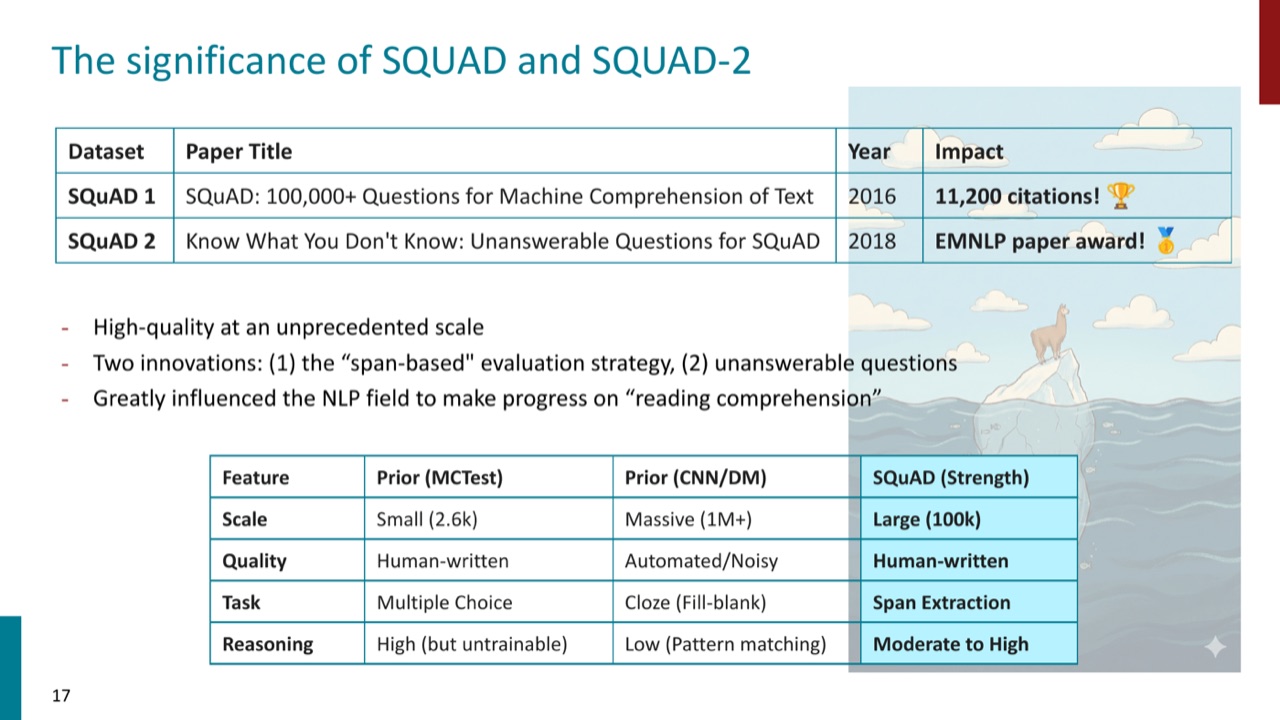
SQuAD 的创新很重要:它让阅读理解评测更大规模、更标准化,也让 span-based 评测成为主流。但 PPT 随后说明,即使 SQuAD 这样成功的 benchmark,也会出现 spurious bias。
5. Spurious Bias:模型会学会“题目里的小抄”
Spurious bias 可以翻译为伪相关偏差。它指数据里存在一些与答案相关但不是任务本质的线索。模型可能利用这些线索得高分,却没有学到真正能力。
5.1 Lexical overlap bias:词面重叠捷径
在阅读理解中,众包标注者看到段落后写问题,往往会复用答案句里的词。结果是:包含答案的句子和问题之间词面重叠很高。模型于是可以学到一个捷径:找与问题重叠词最多的句子。
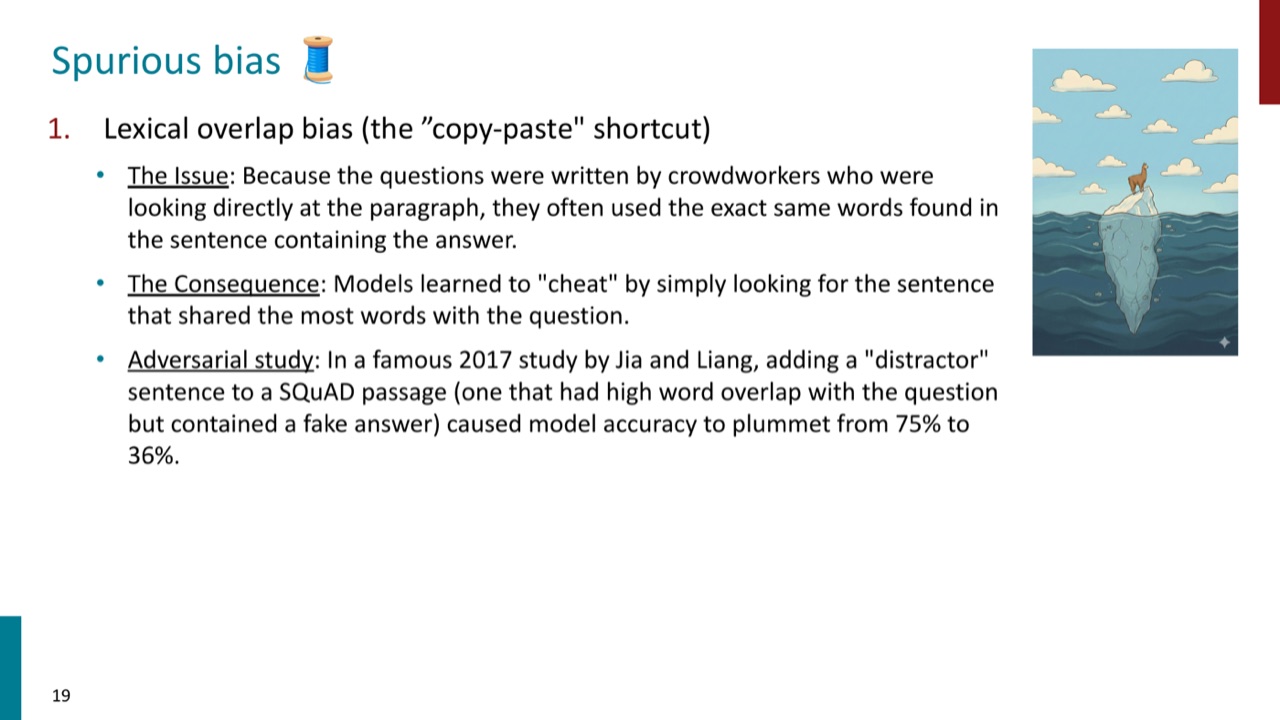
Jia and Liang 的 adversarial distractor 研究展示了这个问题:只要给文章加一句很像问题但答案错误的干扰句,模型准确率就会大幅下降。这说明模型原本可能不是在读懂文章,而是在做匹配。
5.2 Position bias:答案常在开头
Wikipedia 风格段落常把关键信息放在前几句。模型如果发现“答案经常在开头”,就可能过度依赖位置,而不是理解问题和上下文。
这类偏差很隐蔽。因为在正常测试集上,模型看起来分数很高;只有当我们构造打破这种规律的新样本时,模型才暴露问题。
5.3 Annotation artifacts:标注方式本身留下线索
PPT 还提到不可回答问题中的 artifacts。例如标注者为了把问题改成不可回答,可能插入否定词,或者替换实体。模型可能学到“看到某类否定或实体替换,就猜不可回答”,而不是判断文章是否真的支持答案。
这就是为什么评测不能只看最终 accuracy,还要问:模型是凭什么答对的?
6. HANS:专门诊断 NLI 的句法捷径
HANS 是一个 diagnostic test set,用来检查自然语言推理模型是否依赖简单句法启发式。
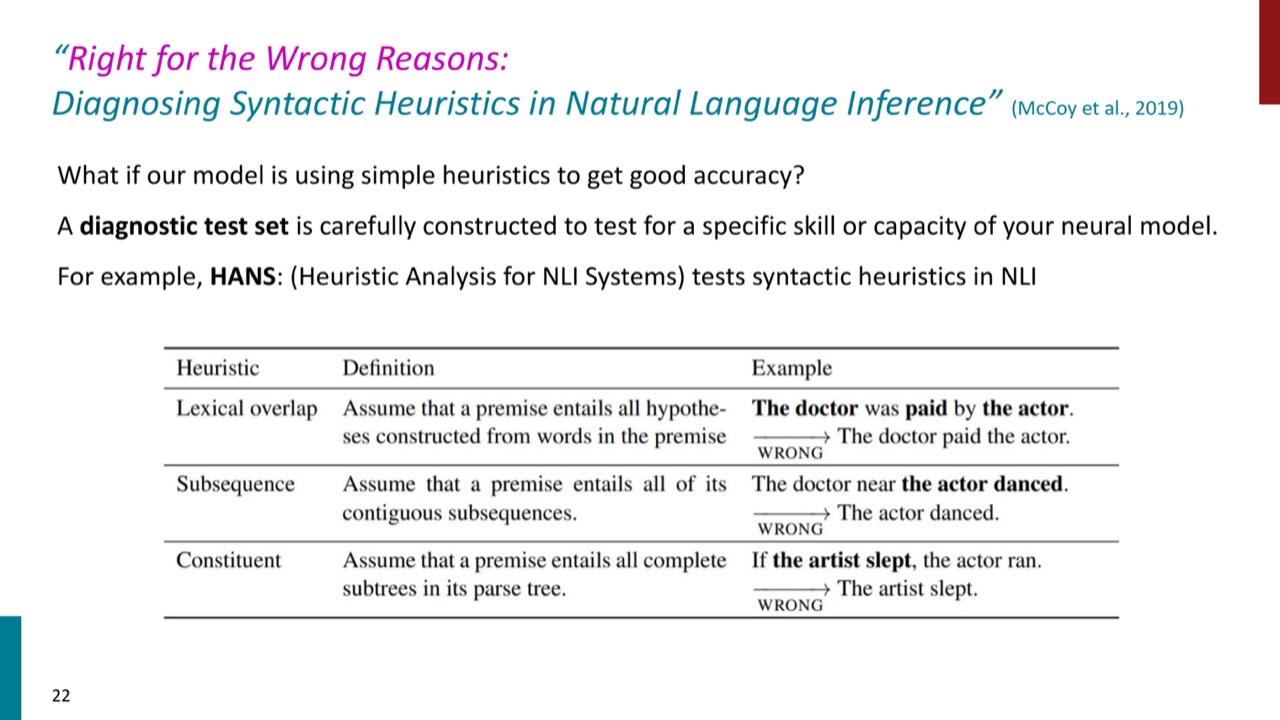
它测试三类常见捷径:
- Lexical overlap heuristic:如果 hypothesis 的词都出现在 premise 里,就猜 entailment。
- Subsequence heuristic:如果 hypothesis 是 premise 的连续子序列,就猜 entailment。
- Constituent heuristic:如果 hypothesis 是 premise 的一个成分,就猜 entailment。
这些启发式在部分样本上有效,但不是逻辑蕴含的定义。HANS 的价值在于,它不是只给一个总分,而是问模型是否真的掌握了某类能力。
7. Adversarial 与 Dynamic Benchmark:让数据跟着模型变
如果 benchmark 是固定的,模型和研究者迟早会过拟合它。PPT 因此介绍了 adversarial 和 dynamic benchmark。
7.1 ANLI:model-in-the-loop 数据收集
ANLI 的思路是把模型放进数据收集流程:人类写样本,模型尝试回答,人类专门构造能骗过模型的例子,再验证并进入下一轮训练与评测。
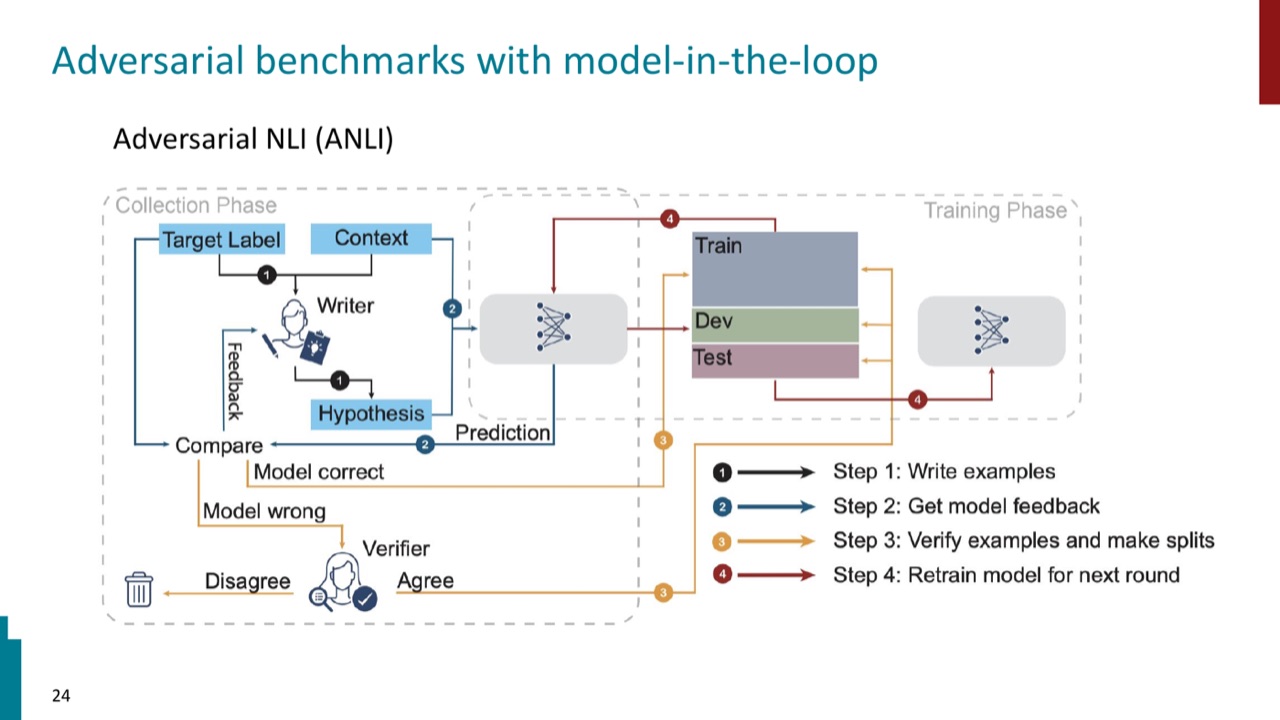
这样做的重点不是“为难模型”,而是暴露模型当前不会的能力。静态 benchmark 更像一次考试,adversarial benchmark 更像不断更新的训练场。
7.2 Dynabench:benchmark 可以动态演化
Dynabench 进一步把 model-in-the-loop 扩展成动态平台。人类不断发现模型失败样本,模型不断更新,benchmark 也随之更新。
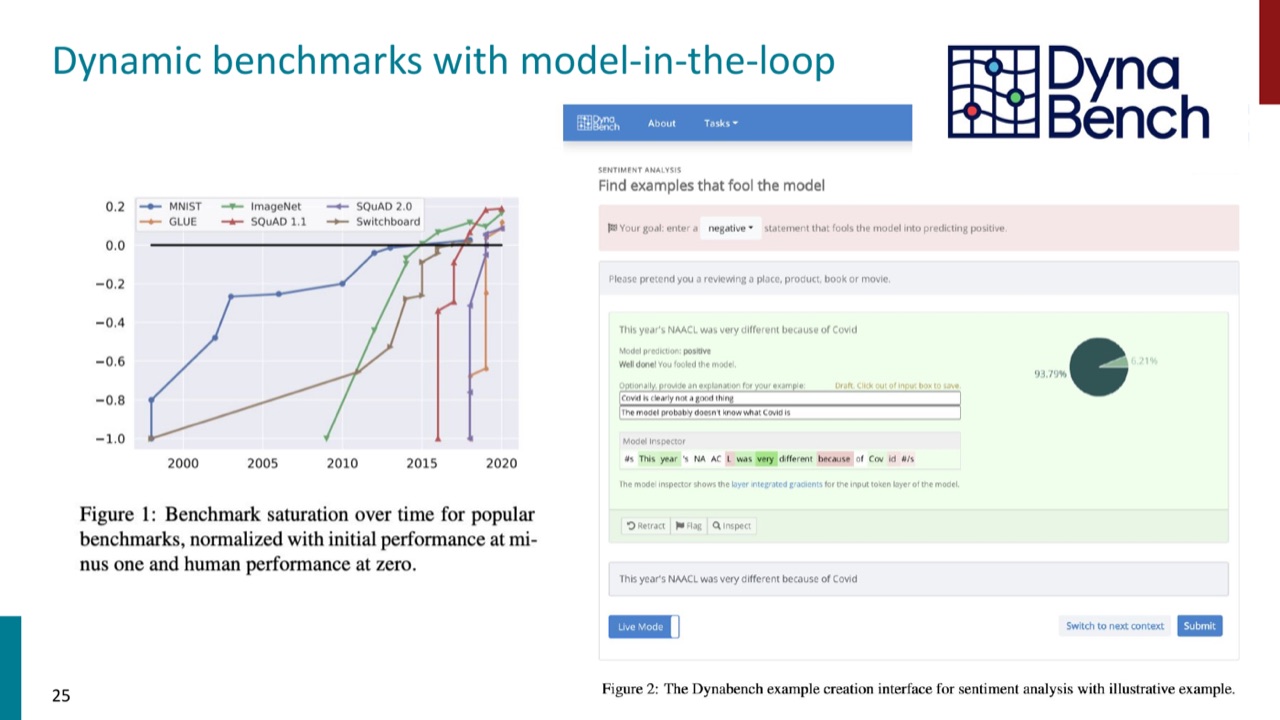
这类方法能延长 benchmark 的寿命,但也带来新的复杂度:数据收集更贵,版本更多,跨版本分数比较更难。
7.3 Behavioral benchmarks:评测模型行为倾向
LLM 不只是答题机器,它还会表现出某些行为倾向。PPT 提到 sycophancy、honesty、people-pleasers、opinions 等 behavioral benchmarks。

这些 benchmark 关心的是模型是否迎合用户、是否诚实、是否在没有根据时表达观点。这类能力很难用单一正确答案评测,因此后面会引出 reference-free、人类评测和 LLM-as-a-judge。
8. 先看答案类型,再选 metric
PPT 很强调一点:不是所有任务都能用同一个 metric。答案形式越开放,评测越难。
8.1 Multiple-choice QA:最容易自动评分
多选题只需要判断选项是否正确,accuracy 就很直接。GLUE、MMLU、TruthfulQA、GPQA Diamond、HLE 的选择题部分都可以这样评。
它的缺点是:模型可能靠选项模式、排除法、格式偏差取胜;而且多选题不能完全代表真实生成能力。
8.2 Short-answer QA:需要处理等价表达
短答案可能是文本 span、数字、公式或表达式。SQuAD、AIME、FrontierMath、HLE 的短答案部分属于这一类。
如果答案是数字,exact match 比较可靠;如果答案是自然语言 span,就要考虑大小写、标点、同义表达、别名和实体格式。
8.3 Sentence 或 Long-form answer:没有唯一标准答案
翻译、摘要、改写、图像描述、长文写作、开放对话都没有唯一正确答案。一个输出可能和参考答案词面不同,却更准确、更自然;另一个输出可能词面很像,却事实错误。
因此,生成任务评测的核心困难是:我们真正关心的是语义、事实性、有用性和风格,但很多自动指标只能看表面。
9. 经典 model-free metrics:快、可复现,但容易看不懂语义
PPT 把 BLEU、ROUGE、METEOR、CIDEr、TER、WER 放在一起讲。它们的共同点是:不依赖一个大型 judge 模型,通常用字符串、n-gram、编辑距离或统计权重来算分。

9.1 BLEU:以 precision 为核心的 n-gram overlap
BLEU 最初主要用于机器翻译。它问的是:生成文本里的 n-gram,有多少也出现在参考答案里?
PPT 给出的形式是:
其中 \(p_n\) 是 clipped n-gram precision:
\(BP\) 是 brevity penalty,用来惩罚过短输出:
通常 \(N=4\),且 \(w_n=1/N\)。
BLEU 的直觉是:好的翻译应该和参考翻译有很多短语重合,同时不能通过输出很短的常见词来骗高分。
9.2 ROUGE、METEOR、CIDEr、TER、WER
- ROUGE 更偏 recall,常用于摘要,问参考答案里的内容有多少被生成文本覆盖。
- METEOR 引入 stemming 和 synonymy,比纯 BLEU 更接近人类语义判断。
- CIDEr 用 TF-IDF 权重衡量多个参考描述之间的共识,常用于图像描述。
- TER 衡量把模型输出改成参考答案需要多少编辑操作。
- WER 是 ASR 中常见的 word error rate。
这些指标的优点是快、稳定、可复现。缺点也很清楚:它们主要看表面形式,很难理解事实、逻辑和语义等价。
9.3 n-gram overlap 的根本问题
PPT 用例子说明,n-gram 指标没有真正的 semantic relatedness。两个语义等价的回答可能词面完全不同,分数很低;两个语义相反的回答可能词面相似,分数反而高。

这不是 BLEU “写得不好”,而是它的设计目标决定的:它只知道 token overlap,不知道世界知识、否定、事实一致性和语用含义。
10. Model-based metrics:让模型帮我们比较语义
为了超越词面匹配,PPT 转向 model-based metrics。核心思路是用模型表示句子或 token 的语义,再比较相似度。
10.1 BERTScore:BLEU/ROUGE 的软匹配版本
BERTScore 用 contextual embeddings 表示 reference 和 candidate,然后用 cosine similarity 做软匹配。

它的 precision 形式是:
recall 形式是:
再组合成:
直觉上,BLEU 要求词面完全匹配,BERTScore 允许语义相近的词或短语匹配。因此它更适合处理同义表达。
10.2 其他 model-based metrics
PPT 还提到:
- Word Mover's Distance:把词嵌入之间的移动成本看成距离,类似 Earth Mover's Distance。
- BLEURT:训练一个模型去模仿人类评测。
- Vector similarity:直接比较句向量或文本向量。
这些方法比 n-gram 更懂语义,但它们不是免费午餐。

主要风险包括:
- metric 模型自身有偏差和能力上限。
- 对 factual error 或 hallucination 可能不敏感。
- 跨领域不一定校准。
- 计算成本更高,可复现性更差。
- 可能偏爱更长、更流畅的输出。
- 与人类判断不一定稳定一致。
所以 model-based metric 的正确用法不是“模型说好就好”,而是把它当成比词面匹配更强但仍需验证的工具。
11. 信息论指标:用 entropy、divergence 看多样性和分布差异
PPT 还介绍了 information-theoretic metrics。它们不是直接问单个答案是否正确,而是看一批样本的分布性质。
11.1 Shannon entropy:平均惊讶程度
Shannon entropy 衡量一个离散分布的不确定性:
如果一个模型总是生成同一种回答,entropy 低;如果它能生成很多不同回答,entropy 高。理论上可以用 entropy 衡量 diversity,但实际中生成文本是高维连续对象,不容易直接定义概率分布。
11.2 Von Neumann entropy 与 Vendi Score
PPT 用 Von Neumann entropy 处理样本间相似度矩阵。先把相似度矩阵 \(K\) 归一化:
再看其特征值的 entropy:
Vendi Score 定义为:
直觉是:如果样本彼此很像,有效多样性低;如果样本覆盖很多方向,有效多样性高。


11.3 KL divergence 与 MAUVE
KL divergence 衡量两个分布的差异:
理论上,我们可以用它比较 LLM 生成语言和人类语言的分布差异。但实际问题是:文本分布高维、连续、复杂,直接计算不可行。如果两个分布的 support 不重合,还会出现除零或不稳定问题。
MAUVE 的思路是先把文本样本嵌入到神经向量空间,再用 k-means 离散化成 cluster,最后在 cluster 分布上估计 divergence frontier。
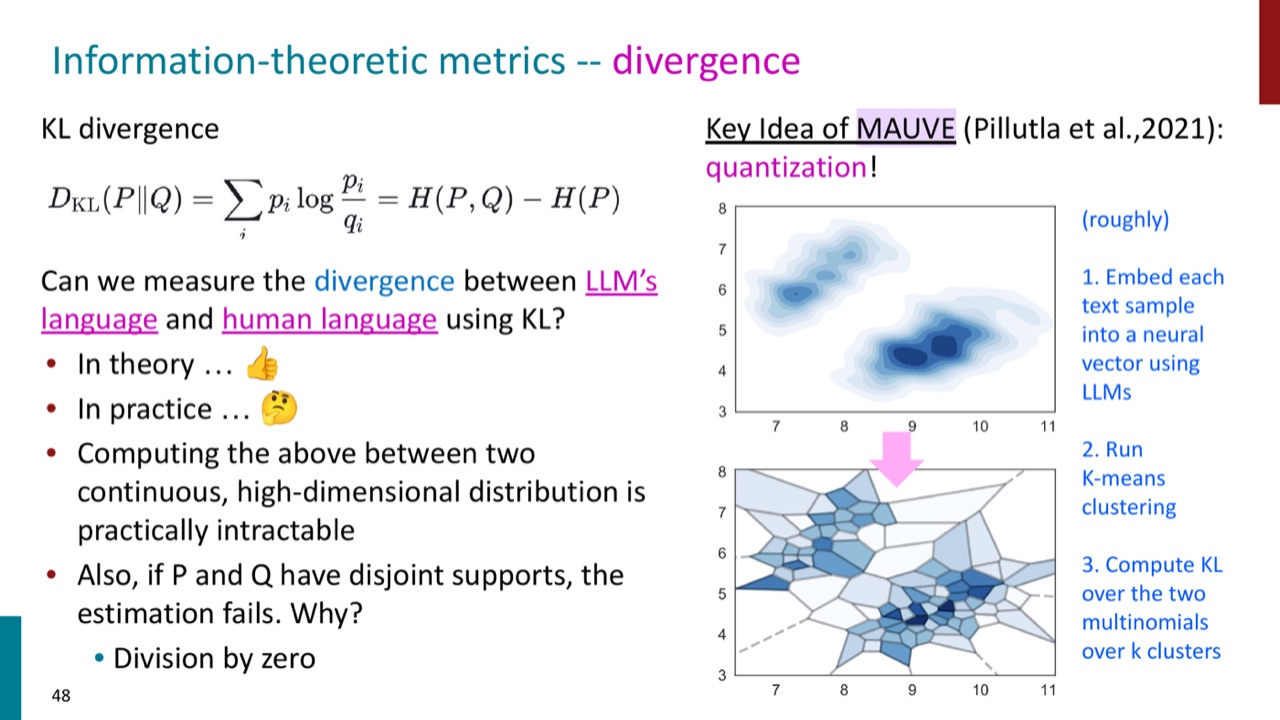
这类指标适合比较整体生成分布,比如一个解码算法是否比另一个更接近人类文本,但不适合单独判断某个回答是否正确。
12. Reference-based 与 Reference-free:有没有标准答案
很多传统指标都是 reference-based:给定一个或多个 gold answers,模型输出越接近参考答案,分数越高。
PPT 指出,reference-based evaluation 长期是标准做法,但它会失败:
- 参考答案质量不高,模型被迫贴近低质量答案。
- 参考答案没有覆盖所有合理答案,模型的好回答被误判。
- 模型过拟合参考答案的表面风格,实际质量没有提高。
因此,reference-free evaluation 变得越来越重要。它不依赖 gold answer,而是直接评估输出和输入、事实源、视觉内容或任务要求之间是否一致。

PPT 中的例子包括:
- COMETKiwi / QE:不用参考译文,直接评估翻译质量。
- FActScore:把长文本拆成 atomic claims,再用知识源验证。
- CLIPScore:评估图像和 caption 的视觉文本一致性。
- SelfCheckGPT:通过同一模型多次采样的一致性检测幻觉。
- G-Eval:用 LLM-as-a-judge 和 CoT 来评估 coherence、helpfulness 等维度。
reference-free 的优势是能处理开放任务;风险是评分器本身更复杂,也更可能引入不可见偏差。
13. Human Evaluation:理想标准也会出问题
PPT 说,所有 automatic metrics 都有不足,因此 human evaluation 长期被看作 ultimate ideal。新的自动指标如果要证明自己有效,通常需要展示它与人类评测高度相关。

但人类评测也有明显问题:
- 成本高,扩展性差。
- 主观性强,不同标注者一致性有限。
- 不同研究的 human evaluation 不能随便横向比较。
- 人类会被表面流畅性、看似合理的解释、输出长度等因素影响。
PPT 给出的正确做法是:
- 明确定义 rubric,比如 correctness、fluency、originality。
- 和标注者一起过很多例子。
- 讨论并校准边界情况。
- 计算 inter-rater agreement。

因此,人类评测不是“找几个人看一看”这么简单。它本身也是一个实验设计问题。
14. Chatbot Arena:更接近真实用户,但也不是万能榜单
Chatbot Arena 的思路是让用户对两个匿名模型输出做偏好比较,再用大量 pairwise preferences 估计模型排名。

它的优点是比很多固定测试集更接近真实使用场景。用户会问各种开放、奇怪、具体的问题,这能暴露模型在真实交互中的表现。
它的缺点也来自这里:
- 用户问题分布不受控,可能包含大量奇怪或低质量 query。
- 新模型进入榜单需要时间和大量评价。
- 只有知名模型更容易被充分评测。
- 随机网站用户的偏好不一定代表专业任务需求。
- 用户可能偏爱更长、更自信、更会聊天的回答,而不是更正确的回答。
所以 Arena 排名有参考价值,但不能等同于“模型在所有任务上更强”。
15. LLM-as-a-Judge:把模型变成评卷人
随着开放生成任务越来越多,LLM-as-a-judge 成为常见评测方式。它用一个强模型读取任务、模型输出和评分标准,然后给出分数或偏好。

优点很直接:
- 成本远低于大规模人类评测。
- 可扩展到大量开放回答。
- LLM 通常能按 rubric 给出结构化评价。
但 PPT 也列出关键缺陷:
- Self-preference / nepotism bias:judge 可能偏爱自己或相似模型的输出。
- Verbosity bias:更长、更像解释的回答可能被高估。
- Vibe checking 强,细微逻辑错误弱:judge 可能擅长判断“感觉好不好”,但漏掉严谨推理问题。
- 强 judge 模型成本仍然高。
15.1 怎么把 LLM judge 做得更可靠
PPT 给出的方向是:
- 给清晰 instructions、examples、rubrics。
- 让多个 judge 讨论或互相校准。
- 使用 LLMs as juries,也就是一组多样 judge 组成 panel。
- 聚合多模型判断,提高 robustness,同时可能用较小模型降低成本。
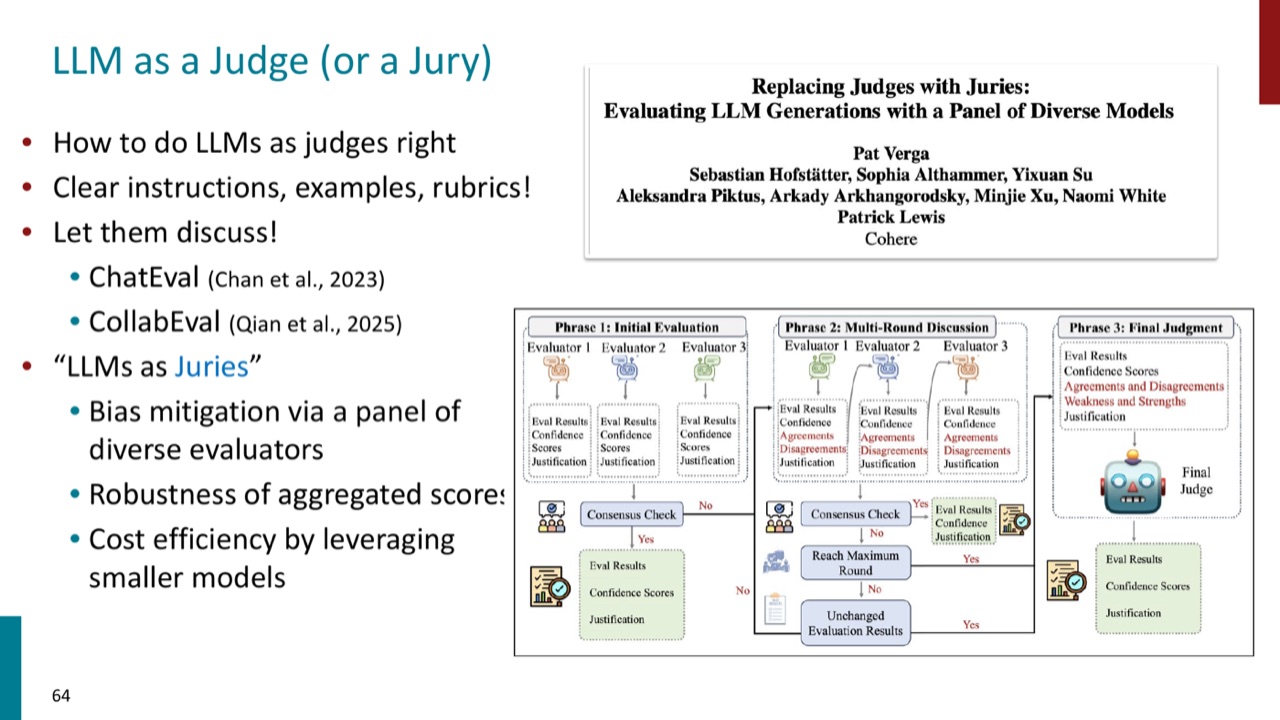
这里的核心思想和人类评测类似:不要相信单个评卷人的直觉,要设计评分协议。
16. Goodhart's Law:当指标变成目标,指标会失真
PPT 引用 Goodhart's law:
意思是:一个指标原本只是能力的代理变量;一旦所有人都直接优化这个指标,它就可能不再代表真实能力。
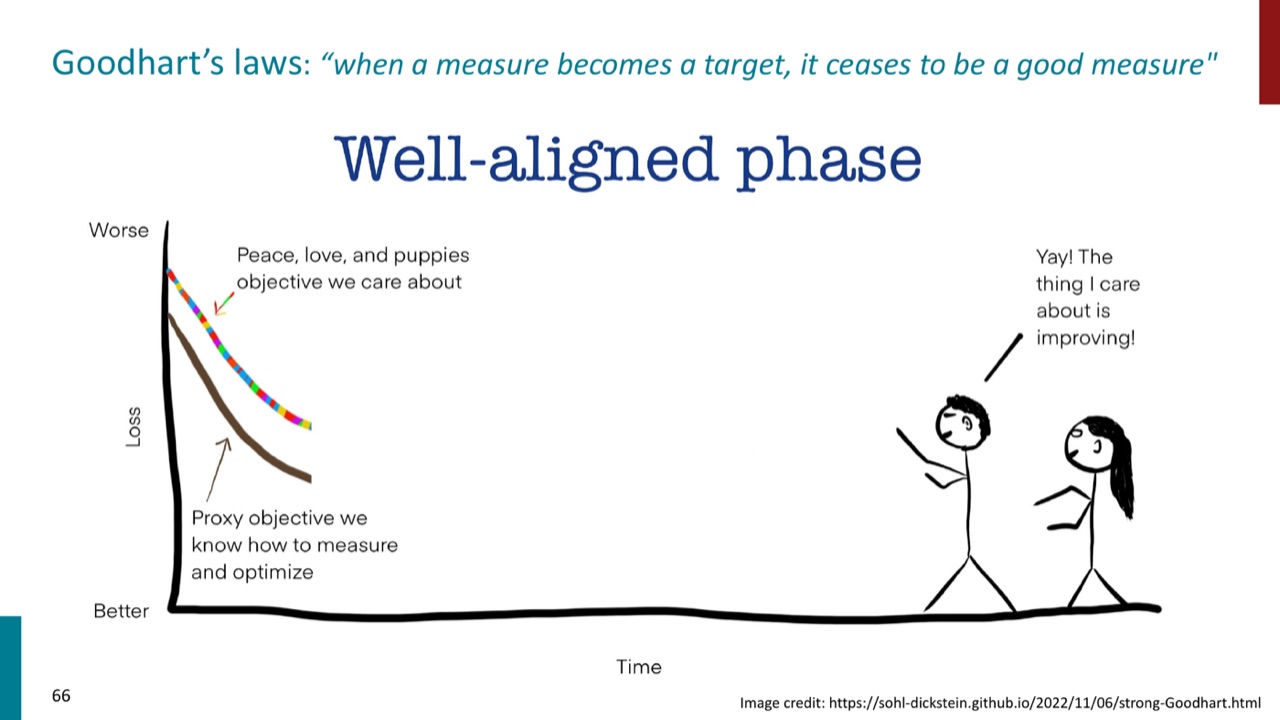
在 LLM 评测里,这会表现为:
- 模型专门优化 benchmark 格式,而不是通用能力。
- 训练数据里混入测试题,导致分数虚高。
- 输出迎合 judge 偏好,而不是更真实、更可靠。
- 研究目标从“解决真实问题”变成“刷某个榜”。
所以评测体系需要不断更新,也需要多个互补指标,而不是把一个分数当作全部真相。
17. Data Contamination:测试题可能已经进了训练集
大语言模型通常用互联网数据预训练,而 benchmark 题目、解答、讨论、复现代码也可能公开在互联网上。PPT 的问题是:我们怎么知道模型没见过测试集?
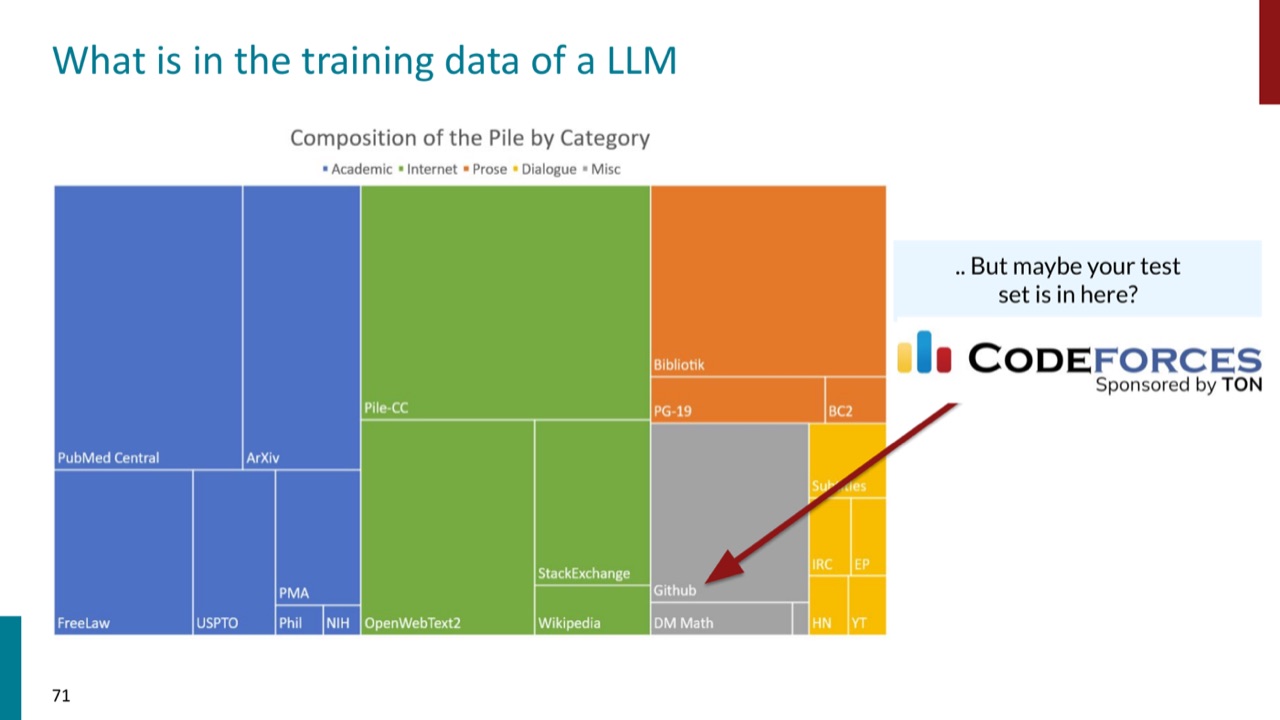
这个问题对闭源模型尤其严重:外部研究者很难知道训练数据里有什么,也很难确认数据清洗是否排除了 benchmark。
17.1 Data de-contamination 怎么做
PPT 提到的实践包括:
- 用 n-gram overlap 检查训练数据和 benchmark 样本之间的 exact 或 near-exact 重叠。
- 常见做法会检查 8 到 13 gram 级别的匹配。
- 有时结合 embedding-based 或 paraphrase-based near-duplicate detection。

但这只能降低风险,不能彻底证明没有污染。特别是 synthetic data 也可能把公开 benchmark 内容重新改写后带入训练。
18. Generator-validator gap:会生成不等于会验证
PPT 还提醒,模型能生成答案,不代表它能稳定验证答案。所谓 generator-validator gap,是指模型在生成任务和判断任务上的能力不一致。
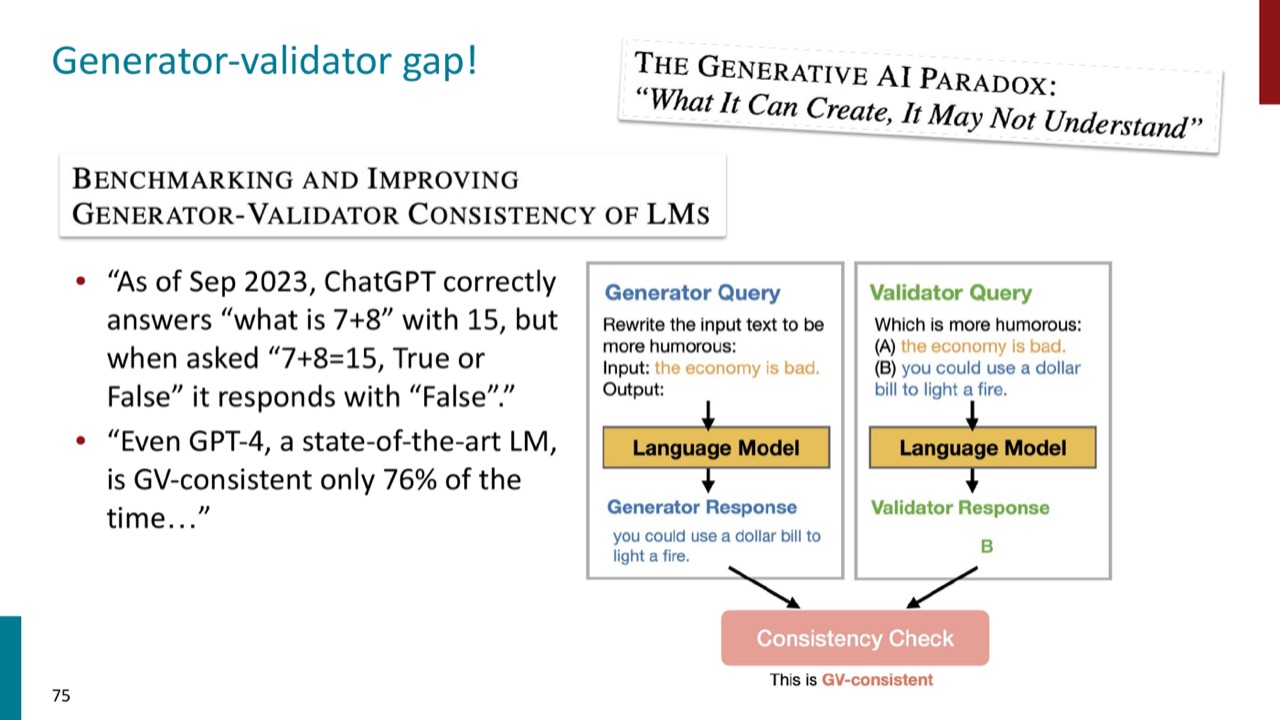
这会影响评测设计。比如用一个模型做 judge 时,它可能能写出看似合理的解释,却不一定能发现候选答案中的细微错误。对于需要严格验证的任务,不能只靠流畅解释。
19. Prompt Formatting:评测协议本身也会改变结果
最后,PPT 强调 prompt formatting matters。模型表现可能因为评测提示的细节发生巨大变化。

会影响结果的因素包括:
- zero-shot 还是 few-shot。
- few-shot 给几个例子。
- 是否使用 CoT。
- 分隔符、大小写、空格等微小格式。
- 答案抽取脚本如何从输出中解析最终答案。
这意味着评测论文或报告必须写清楚 prompt、采样参数、答案解析方式和 scoring script。否则别人很难复现,也很难判断分数差异来自模型能力还是评测格式。
20. 从这一讲形成的评测工作流
以后你看到一个 LLM benchmark 结果,可以按这条清单检查:
- 任务是什么:它到底测的是知识、推理、指令遵循、对话偏好、事实性,还是安全行为?
- 答案类型是什么:多选、短答案、长文本、开放对话,对应的评分难度完全不同。
- metric 是什么:accuracy、BLEU、BERTScore、人类偏好、LLM judge 各自意味着什么?
- 有没有伪相关:模型能不能靠词面重叠、位置、格式、选项模式得分?
- 有没有数据污染:测试题是否公开,训练数据是否可能包含它?
- prompt 是否固定且公开:不同 prompt 会不会让排名改变?
- 结果是否过度泛化:某个榜单高分是否被错误解释成“模型全面更强”?
21. 本讲复习题
- Benchmark、metric、leaderboard 三者有什么区别?
- 为什么 GLUE / SuperGLUE 高分不等于模型具备开放世界推理能力?
- SQuAD 中的 lexical overlap bias 如何让模型答对但理由错?
- HANS 为什么不是普通测试集,而是 diagnostic test set?
- BLEU 的 \(BP\) 和 \(p_n\) 分别在惩罚什么?
- 为什么 BERTScore 比 BLEU 更懂语义,但仍可能漏掉事实错误?
- Reference-based evaluation 在开放生成任务中会遇到什么问题?
- Human evaluation 为什么不能直接跨论文比较分数?
- LLM-as-a-judge 有哪些偏见?为什么可以考虑 LLMs as juries?
- Goodhart's law 和 data contamination 分别怎样破坏 benchmark 的可信度?
- 为什么 prompt formatting 是评测协议的一部分,而不是无关细节?