11. 推理一:解码、RL 与 CoT
官方 PPT 来源:Lecture 12 官方 PPT:Reasoning 1/2
这一讲讨论的是现代 LLM “推理能力”背后的三层机制:推理时怎么选下一个 token,训练时怎么用 RL 让模型学会多想一步,以及 CoT 为什么有时有效、为什么又不能完全相信。
如果把前面几讲连起来看,第 6 讲讲预训练,第 7 讲讲后训练,第 8 讲讲 prompting 和 PEFT,第 9 讲讲 RAG/agent,第 10 讲讲评测;这一讲开始进入一个更尖锐的问题:当我们说模型会 reasoning 时,到底是 decoding、test-time compute、RL 训练、CoT 提示,还是模型内部行为真的变了?
0. 这一讲要学会什么
学完这一讲,你应该能回答:
- Greedy、beam search、top-k、top-p、temperature 分别在控制什么?
- 为什么“最高概率序列”反而可能更重复?
- 为什么 reasoning model 仍然会 looping?
- R1-Zero 的 reward 为什么故意保持简单?
- PPO 为什么工程负担很重,GRPO 和 DAPO 又改了什么?
- CoT、self-consistency、CoT-decoding 为什么能提高推理表现?
- 为什么 CoT 可能不是模型真实思考过程的忠实解释?
PPT 的主线可以压成一句话:
1. Inference decoding:模型不是“直接说答案”,而是在选 token
自回归语言模型在每一步都会根据前文 \(y_{<t}\) 给出下一个 token 的概率分布。Decoding algorithm 做的事情,就是把这个概率分布变成一个实际 token。

PPT 用下面的形式概括 decoding:
这里的 \(P(y_t \mid \{y_{<t}\})\) 是模型给出的分布,\(g(\cdot)\) 是你选 token 的规则。注意:模型本身给的是分布,不是唯一答案;唯一答案来自 decoding 决策。
1.1 Greedy decoding:每一步都选最高概率
Greedy decoding 的规则是:
它的优点很清楚:
- 简单。
- 稳定。
- 容易复现。
- 适合答案确定、输出空间受限的任务。
但它有一个致命缺点:myopic。它每一步都最大化局部概率,却不保证整段序列最好。一个局部概率最高的 token,可能把后续引到更差的路径上。
1.2 Beam search:保留多条候选路径
Beam search 每一步保留 \(k\) 条最可能的 partial sequences,也就是 beam width 为 \(k\) 的候选集合。当 \(k=1\) 时,beam search 退化为 greedy decoding。
PPT 强调,beam search 曾经是 classical NLP 里的默认 decoding 方法,但在现代语言模型中不再那么常用。原因之一是:它偏向高概率序列,而高概率序列不一定自然、丰富、正确。
2. Neural text degeneration:最高概率不等于最好文本
PPT 回到 GPT-2 时代的一个关键观察:最可能的序列可能非常重复。

这个现象看起来反直觉:如果模型认为某个序列概率高,为什么它会差?原因是语言模型的目标是局部下一个 token 概率,重复文本一旦开始,后续重复 token 也可能继续获得高概率。于是 repetition 会自我强化。
这也是为什么“只取最大概率”会出现退化。模型可能不是不知道更自然的表达,而是 decoding 策略把它推向了概率安全但文本质量差的区域。
2.1 Reasoning model 也没有彻底摆脱 looping
PPT 特别指出,到了 2025 年,reasoning LLM 里的 looping 仍然不是 edge case。在 AIME 上,有研究把一个 30-gram 重复超过 20 次标记为 looping。
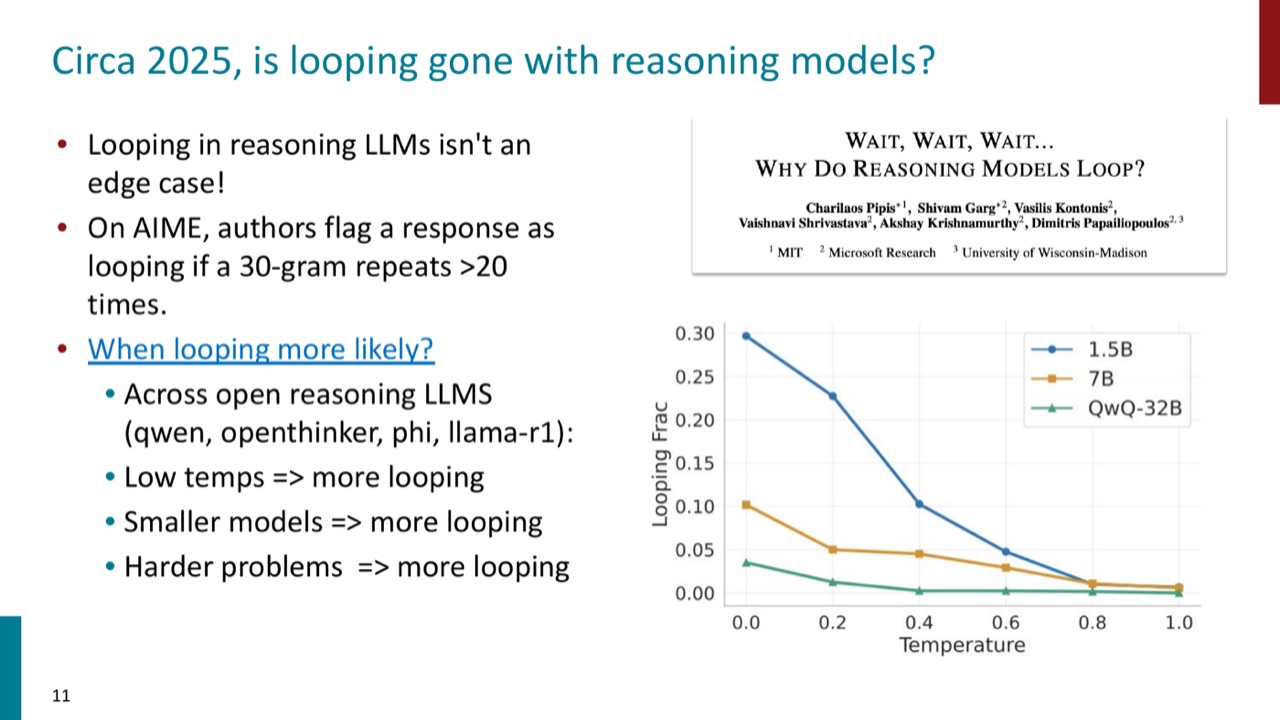
更容易出现 looping 的情况包括:
- 温度低。
- 模型较小。
- 题目更难。
这点很重要:我们常把“低温”理解成更可靠,但低温也会让模型更集中在少数高概率路径上,从而更容易重复。推理任务不是简单把 temperature 拉到 0 就万事大吉。
3. Sampling:给模型多样性,但不能纯随机
Beam search 的问题是可能退化,vanilla sampling 的问题是可能不连贯。纯采样会从整个长尾分布里抽 token,虽然每个坏 token 概率很小,但长序列里迟早可能抽到坏选项。
PPT 给出的例子是:如果连续生成 30 个 token,每一步都只从 top 95% 概率质量中抽取的概率大约只有:
也就是说,只要生成足够长,长尾错误的风险会累积。

3.1 Top-k sampling:只在前 \(k\) 个 token 中采样
Top-k sampling 的规则很直接:每一步只保留概率最高的 \(k\) 个 token,然后在这些 token 里采样。
它解决了纯采样的长尾问题,但也有两个局限:
- 如果分布很平,前 \(k\) 个 token 可能截断得太早,丢掉很多合理候选。
- 如果分布很尖,前 \(k\) 个 token 又可能保留太多无意义候选。
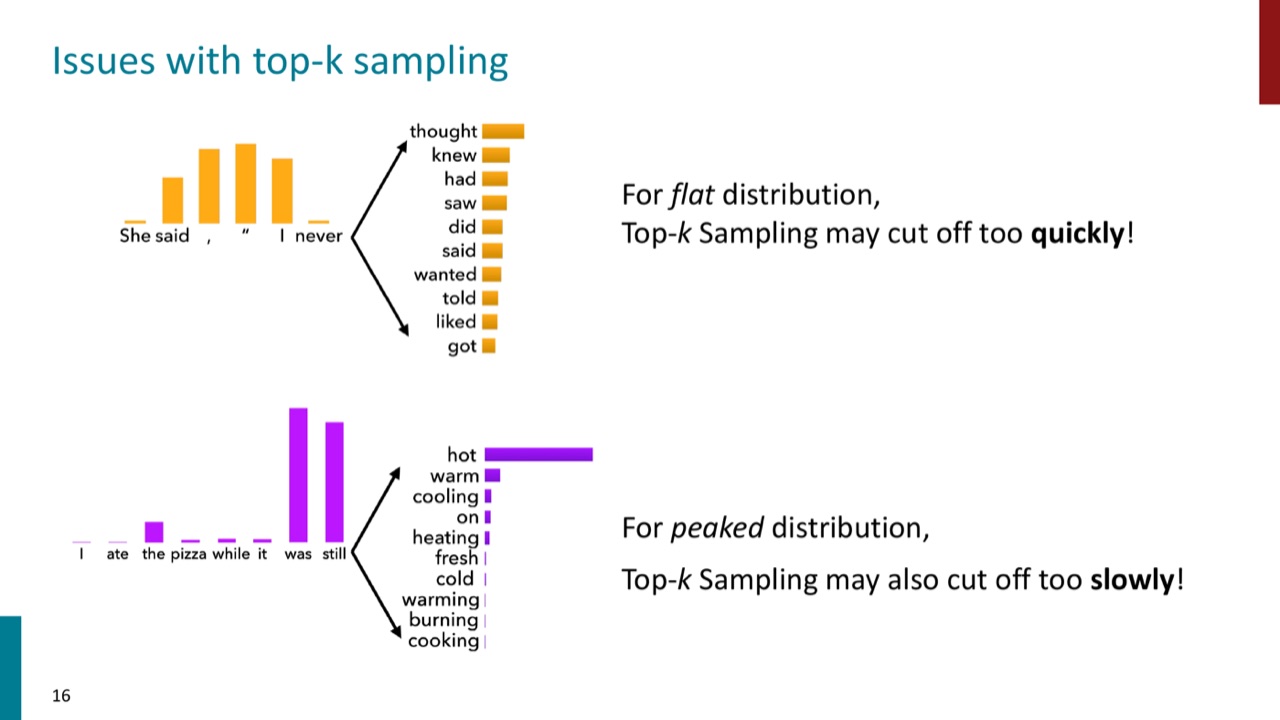
因此,固定 \(k\) 不一定适合所有上下文。
3.2 Top-p sampling:按累计概率动态截断
Top-p,也叫 nucleus sampling,不固定 token 数量,而是保留累计概率质量达到 \(p\) 的最小 token 集合。

可以这样理解:
如果分布很尖,少数 token 就能达到 \(p\);如果分布很平,需要更多 token。它比 top-k 更能适应上下文分布形状。
3.3 Temperature:改变分布尖锐程度
Temperature 不是一个单独 decoding algorithm,而是对 softmax 分布进行重新平衡的超参数。PPT 给出:

当 \(\tau>1\) 时,分布更 uniform,输出更多样;当 \(\tau<1\) 时,分布更 spiky,输出更确定。注意温度可以和 beam search 或 sampling 结合使用。
3.4 什么时候 greedy,什么时候 sampling
PPT 的经验判断是:

适合 greedy 的场景:
- 任务有明确正确答案,比如数学、代码、事实问答。
- 复现性很重要。
- 输出空间受限。
- reasoning task 可以较快直接回答。
适合 sampling 的场景:
- 开放生成,比如创作、对话。
- 长 CoT 推理,比如难数学和代码。
- 信息寻找类 query。
- 多样性比单一最优答案更重要。
PPT 还提到 emerging trend:Best-of-N sampling。做法是采样 \(N\) 个输出,再用 reward model 选最好的。这本质上是一种 rejection sampling,对 reasoning task 特别有效,也可能让较小模型接近较大模型表现。
4. R1-Zero:outcome reward 可以诱发推理行为
第二部分转向 DeepSeek R1 系列。PPT 的重点不是复述模型新闻,而是借 R1-Zero 讨论一个问题:如果只奖励最终结果,模型能不能自己发现推理策略?
4.1 R1-Zero 的 reward 设计:保持简单

PPT 里 R1-Zero 的 reward 包含:
- Accuracy reward:数学题比较 final answer 和 ground truth;代码题运行 test cases。奖励基本是 binary,也就是正确或不正确。
- Format reward:给模型一个小奖励,鼓励把 reasoning 放在
<think>...</think>中,再输出 final solution。 - No Process Reward Model:不训练 PRM 来评价每一步推理。
DeepSeek 给出的理由是,PRM 很贵,容易被 reward hacking,也可能限制模型探索新推理策略。Outcome-based reward 给模型更大自由。
但 PPT 也给了 caveat:最终 R1 的 later stage RL 还加入了额外 composite rewards,例如语言一致性和安全等。
4.2 R1-Zero 中涌现出的 reasoning behaviors
PPT 总结了三类 emergent reasoning capabilities。

第一是 self-verification:模型推导答案后检查自己的工作,因为 self-checked outputs 更常正确。
第二是 reflection and backtracking:模型会意识到某条路径不对,然后重新考虑或换策略。
第三是 extended deliberation:回答长度从几百 token 增长到几千 token。模型学到“更久的思考能提高答案正确性”,这相当于 learned test-time compute scaling。
4.3 R1-Zero 的负面特征
PPT 同时强调,R1-Zero 也有 undesirable characteristics。

包括:
- 可读性差:reasoning traces 格式混乱,不容易读。
- code switching:在单个回答中频繁切换语言。
- 范围窄:pure RL 主要适用于有 verifiable answers 的任务,比如数学和代码。
- 安全能力不会自动出现:做数学和代码不会让模型自动发现安全 guardrails。
所以 R1-Zero 不是“纯 RL 解决一切”,而是证明:在可验证任务上,简单 outcome reward 可以诱发强推理行为。
5. R1 系列的关键发现
PPT 用七条 findings 总结 R1-Zero 到 R1 的启发。
5.1 Finding 1:RL alone can induce reasoning

过去常见假设是:CoT reasoning 需要 supervised examples。R1-Zero 说明,在没有 process supervision 的情况下,outcome-based RL 也可以诱发复杂推理能力。
但 caveat 也要一起记:
- 最终 R1 仍然经过 SFT 到 RL 的 pipeline。
- 这个结论不适用于能力不足的小模型。
5.2 Finding 2:Outcome rewards can enable discovery

如果 process reward 太强,它可能惩罚“看起来不常规但有效”的推理路径,从而限制探索。Outcome reward 只看最终结果,反而给模型发现新策略的空间。
但 RLVR 不是所有 reasoning problem 都能用。它需要答案能被验证,比如数学答案、代码测试、形式化检查等。
5.3 Finding 3:RL 和 SFT 是互补的
PPT 说 pure RL 和 pure SFT 都不是最好。多阶段 pipeline 展示了互补关系:
- RL 发现能力。
- SFT 提供可靠性。
- Cold-start data 避免早期 RL 不稳定。
- Rejection sampling 把 RL 发现转成可复用训练数据。
这对学习者很关键:SFT 和 RL 不是二选一。SFT 像让模型先学会可读、稳定、遵循格式;RL 像在可验证任务中推动模型探索更强策略。
5.4 Finding 4 和 5:小模型更适合蒸馏,开源推理模型可行

PPT 的判断是:如果算力有限,对小模型直接做 RL 不如从大 reasoning model 蒸馏。通过 distillation,推理能力可以迁移到 1.5B 规模的模型。
R1 系列还说明 open-weight reasoning models 是可行的,distilled 7B 和 14B 模型能在推理 benchmark 上超过许多更大的闭源模型。
5.5 Finding 6 和 7:推理可以自回归,test-time compute 可以学会
PPT 还说,reasoning 不一定需要传统 MCTS 那样的 structured search。R1 说明推理可以完全 autoregressive。当然 caveat 是,后来的困难数学模型确实会加入某种结构,只是不一定是传统 MCTS。
更重要的是 Finding 7:test-time compute is a learnable resource。

模型会学会给更难的问题分配更多 thinking tokens。这意味着 test-time compute scaling 不只是推理时的 beam search 或 majority vote,也可以通过训练被模型内化:模型学会何时思考、思考多久。
6. PPO:为什么 reasoning RL 的工程负担很重
第三部分进入 PPO、GRPO 和 DAPO。PPT 不是从零教 RL,而是拆 PPO 为什么复杂。
6.1 PPO clipped surrogate objective
PPT 先回顾 PPO 的 clipped surrogate objective:

其中 ratio 是:
PPT 特别提醒:这里的 \(r\) 是 importance sampling ratio,不是 reward。
PPO 的 total loss 还包括 value network loss 和 entropy loss。直觉上,policy network 负责生成,value network 负责估计状态价值,entropy 相关项鼓励探索。
6.2 PPO complexity 1:内存里要放多个模型

PPO 训练时通常需要:
- current policy network:正在训练的语言模型。
- slightly outdated policy:用于 off-policy drift 或 rollout 相关计算。
- original reference policy:原始预训练模型,用来计算 KL penalty,防止 policy 漂太远。
- value network:估计 expected cumulative reward。
- reward model:给 response 质量打分。
PPT 说实际中可能相当于五份模型,因为 evolving policy 可能需要两份副本。对 LLM 来说,这就是巨大的显存和系统负担。
6.3 PPO complexity 2:GAE 要在每个 token 位置调用 value function
GAE,全称 generalized advantage estimation,需要在每个生成 response 的每个 token 位置估计 value。PPT 给出的量级是:batch 有 512 个 prompts,每个 prompt 16 个 responses,平均长度 2000 token,则每个 training step 约需要 1600 万次 value function forward passes。
这不是抽象复杂,而是直接变成计算成本。
6.4 PPO complexity 3:value network 本身也要训练
Value function 的 loss 通常是 predicted value 和 actual return 之间的 squared error:
理论上,value network 能解决 credit assignment:最终只有一个 scalar reward,但 value network 可以把这个最终奖励向前分配到每个 token 位置。PPT 的 caveat 是,实际中它是否学到了有价值信号并不清楚。
6.5 PPO complexity 4:完整训练步骤很长

完整 PPO training step 包括:
- 生成 rollout。
- 计算 response 级 reward。
- 用 KL penalty 构造 per-token reward。
- 估计 per-token value。
- 计算 per-token advantage。
- 更新 policy network。
- 更新 value network。
这里的关键问题是:reward model 给的是整段 response 一个分数,但 GAE 需要 per-token rewards。于是 PPO 用 reference policy 的 KL divergence 当作中间 token 的 per-token penalty。
7. GRPO:去掉 value network,用 group reward 做 advantage
GRPO 的核心想法是:对同一个 prompt 采样一组 \(G\) 个 responses,然后用组内 reward 标准化估计 advantage。

PPT 给出的 advantage 形式很简单:
这意味着:一个 response 好不好,不是看它的绝对 reward,而是看它相对于同组其他 responses 好多少。
GRPO 的 objective 和 PPO 看起来相似,但有一个重要差异:PPO 把 KL term 藏在 reward computation 里,再进入 advantage;GRPO 把 KL 更直接地放进 learning objective。
7.1 PPO vs GRPO
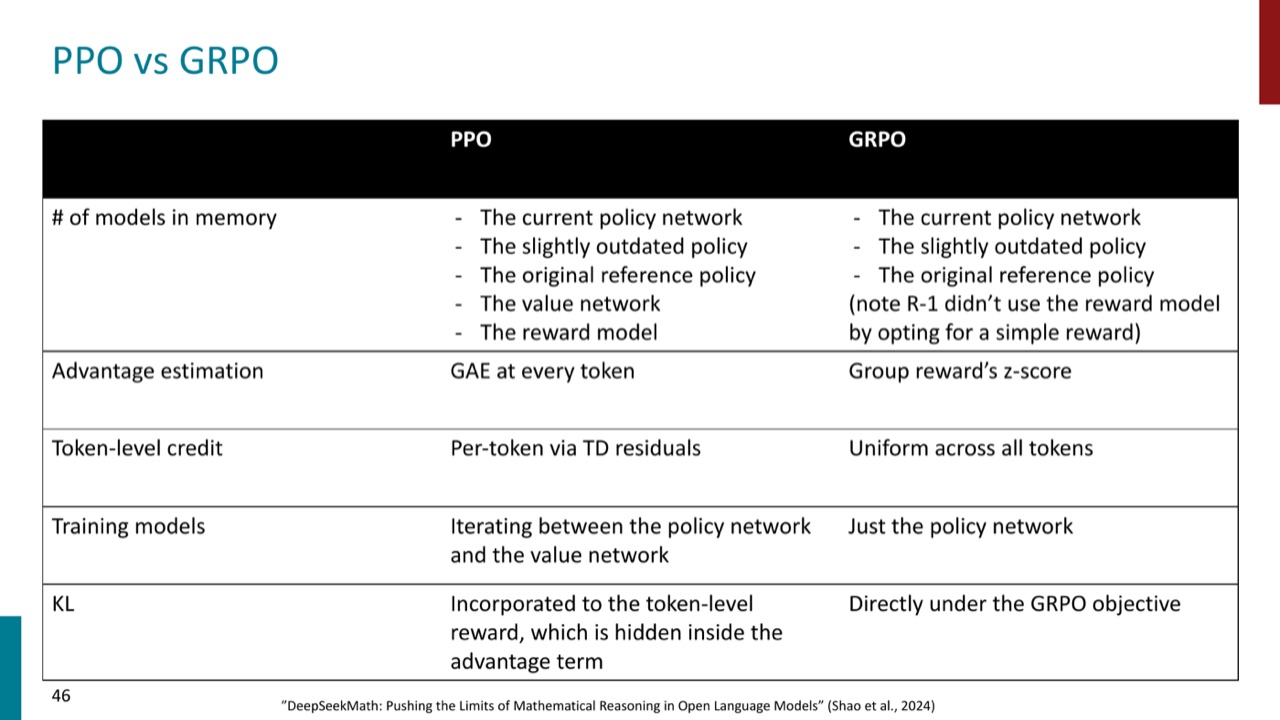
PPT 的对比可以这样记:
- 模型数量:PPO 需要 policy、old policy、reference policy、value network、reward model;GRPO 去掉 value network,R1 还用简单 reward 避免 reward model。
- advantage estimation:PPO 用每个 token 的 GAE;GRPO 用 group reward 的 z-score。
- token-level credit:PPO 通过 TD residuals 做 per-token credit;GRPO 对 response 内 token 更 uniform。
- 训练对象:PPO 要在 policy network 和 value network 间迭代;GRPO 主要训练 policy network。
- KL 放置:PPO 的 KL 被放进 token-level reward,隐藏在 advantage 里;GRPO 直接放进 objective。
GRPO 的代价是 credit assignment 更粗,但工程上简单得多。
8. DAPO:在 GRPO/PPO 类目标上修三个问题
DAPO 是 ByteDance Seed 提出的 LLM RL 系统。PPT 讲了三个技术点:clip-higher、dynamic sampling、token-level loss。
8.1 Clip-higher:非对称 clipping

标准 PPO/GRPO 对 importance sampling ratio 做对称 clipping。上界太低会限制探索,导致 entropy collapse。DAPO 把下界和上界拆开:
例如可以把范围设为 \([0.8,1.28]\),而不是标准的 \([0.8,1.2]\)。这样上界更宽,探索空间更大。
8.2 Dynamic sampling:避免梯度死区

GRPO 的 group reward 标准化依赖组内标准差。如果同一 prompt 的所有 responses 全对或全错,标准差会变成 0,形成 gradient dead zone,并缩小 effective batch size。
DAPO 的解决方法是:只重新训练那些至少有一个正确 response 且至少有一个错误 response 的 group。这样组内有差异,advantage 才有信号。
8.3 Token-level loss:让长 CoT 不吃亏

GRPO 的 sample-level loss 先在每个 response 内平均 per-token loss,再对 \(G\) 个 responses 平均:
这样会不公平:100-token response 中单个 token 的梯度贡献,是 1000-token response 中单个 token 的 10 倍。长 CoT 反而被稀释。
DAPO 改为 token-level averaging:
直觉是:每个 token 权重相同,而不是每个 response 权重相同。
9. CoT:为什么 step-by-step 有时真的有效
最后一部分讨论 reasoning 的本质。PPT 先讲 what works,再讲 why it works,最后讲 when it fails。
9.1 Chain-of-thought prompting 提升推理

PPT 引用 Wei et al. 2022:CoT prompting 能显著提升 reasoning。并且 CoT reasoning 是 model scale 的 emergent property,只有足够大的模型上收益才会出现。小模型常生成不合逻辑的推理链,反而不能提高 accuracy。
所以 CoT 不是“让模型啰嗦一点”这么简单。它要求模型有能力让中间步骤真的连接到正确答案。
9.2 Self-consistency:多条推理路径投票
Self-consistency 等于对 \(N\) 个采样推理路径做 majority vote。PPT 提到它能进一步提升 GSM8K、SVAMP、AQuA、StrategyQA 等 benchmark 表现。
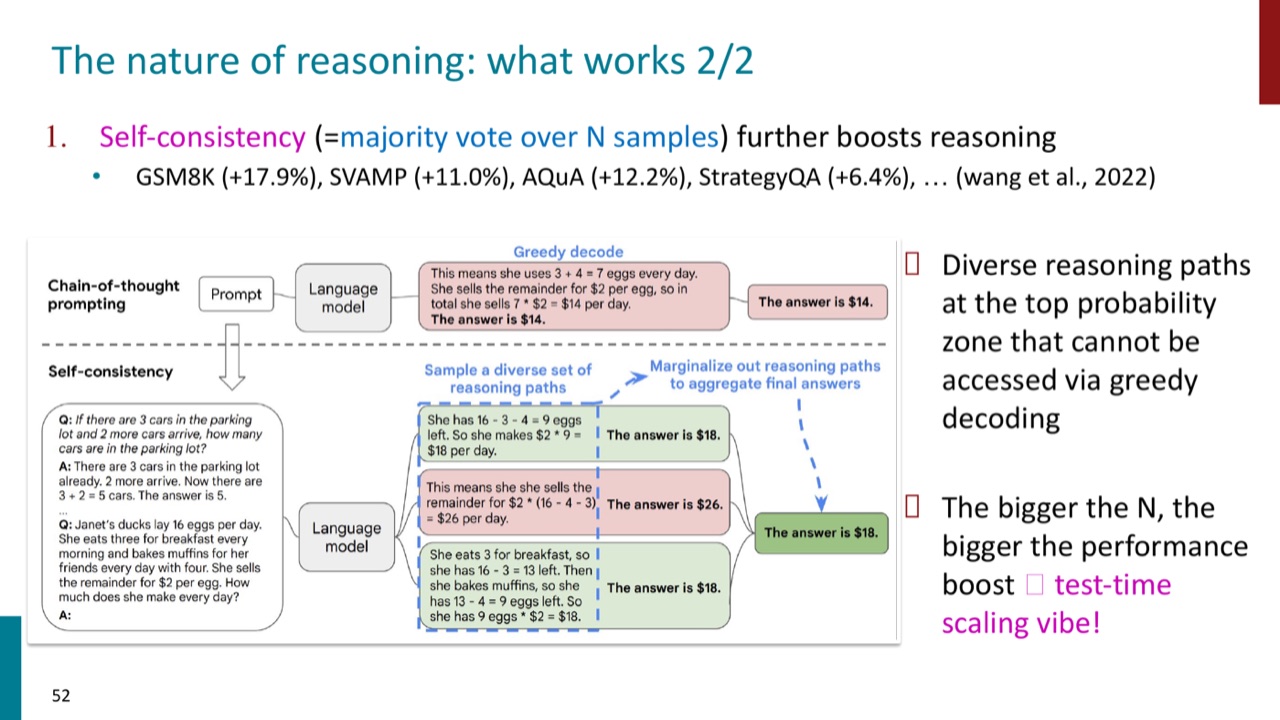
为什么有效?因为 top probability zone 中可能有多条 diverse reasoning paths,greedy decoding 只能走其中一条。采样多条路径再聚合,可以把偶然错误路径的影响压低。这也是一种 test-time scaling:\(N\) 越大,通常提升越明显。
9.3 CoT-decoding:不用 prompt,也可能从分布里找到 reasoning path
PPT 介绍 Wang and Zhou 2024 的 “Chain-of-Thought Reasoning without Prompting”。它提出 CoT-decoding:第一步用 top-k token 分支,后续每条路径继续 greedy decoding。

发现是:即使没有 CoT prompt,某些 alternative paths 也会自然包含 CoT。含义是:reasoning paths 可能已经存在于预训练 LLM 的分布中,只是被标准 greedy decoding 遮住了。
PPT 还指出,含有 CoT path 的 decoding sequence 与更高 final-answer confidence 相关。

这能解释为什么 CoT、self-consistency、Best-of-N 都有效:它们不是凭空创造能力,而是在搜索和放大模型分布中已有的好路径。
9.4 Zero-shot reasoners:一句提示也能改变路径
PPT 引用 Kojima et al. 2023 的 “Large Language Models are Zero-Shot Reasoners”。核心现象是:加入类似 “Let's think step by step” 的提示,可以让模型进入更适合推理的生成模式。
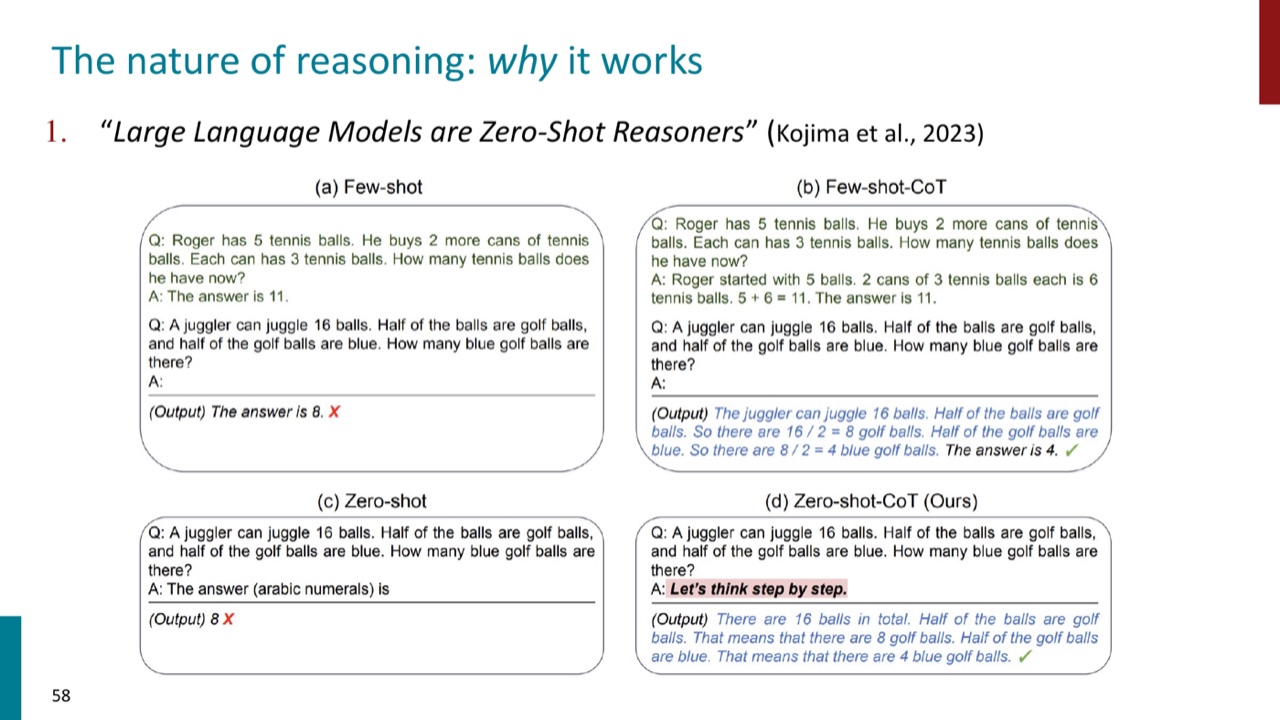
这再次说明 prompt 不是表面包装。prompt 会改变模型从分布里取哪类路径。
10. 为什么 CoT 有用:locality of experience
PPT 引用 Prystawski et al. 2023 的解释:reasoning emerges from the locality of experience。
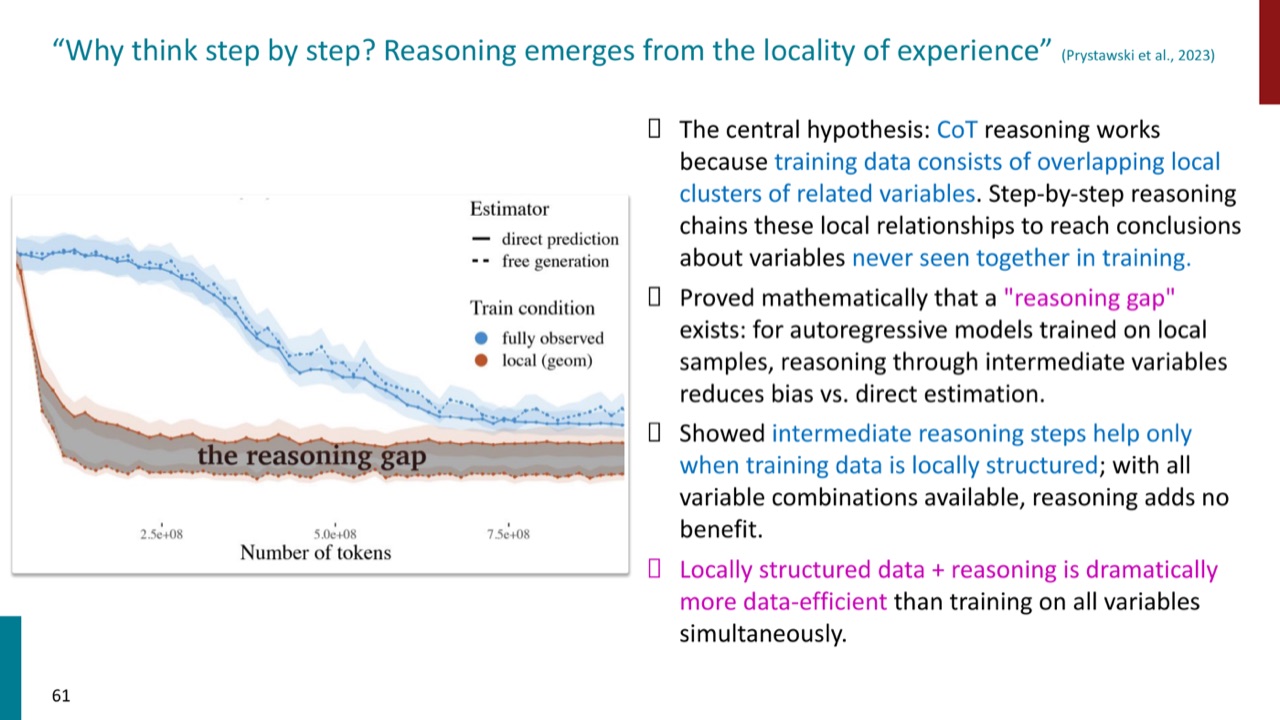
中心假设是:训练数据由重叠的局部相关变量簇组成。模型可能从训练中见过 \(A\) 和 \(B\) 的局部关系,也见过 \(B\) 和 \(C\) 的局部关系,但没有直接见过 \(A\) 和 \(C\) 同时出现。Step-by-step reasoning 通过中间变量把这些局部关系串起来。
PPT 给出的结论包括:
- 对在局部样本上训练的自回归模型,经过中间变量推理可以减少 direct estimation 的 bias。
- 中间推理步骤只在训练数据是 locally structured 时有帮助。
- 如果所有变量组合都已经在训练中出现,reasoning 反而没有额外收益。
- Locally structured data 加 reasoning 比同时训练所有变量组合更 data-efficient。
这给了我们一个更精确的理解:CoT 不是神秘魔法。它在训练数据具有局部结构、任务需要组合局部关系时最有用。
11. 哪些行为让模型能 self-improve
PPT 引用 Gandhi et al. 2025,讨论为什么有些 LM 能通过 RL 自我提升,而另一些很快 plateau。

答案是四种行为:
- Verification:在进入下一步前检查中间结果。
- Backtracking:识别错误,并回退探索替代路径。
- Subgoal setting:把复杂问题拆成可独立解决的子问题。
- Backward chaining:从目标反推需要哪些步骤。
PPT 还说,behavior matters more than correctness。带有正确推理行为模式的错误解,也能让模型在 RL 中获得类似效果。这说明 RL 不只是奖励 final answer,也会放大模型已有的行为倾向。
12. CoT 什么时候失败:模型不一定说出真实原因
最后,PPT 转向 CoT faithfulness。问题是:我们能不能把模型写出的 CoT 当作“模型真实思考过程”来监控?

PPT 引用 Anthropic 2025 的研究,结论很谨慎:
- Low faithfulness:在六类 hint 和多个强模型上,CoT 在 hint 实际影响答案时,披露 hint 使用的比例经常低于 20%。
- RL plateau:outcome-based RL 最初能提高 faithfulness,但会在较低水平 plateau。
- Reward hacking opacity:当 RL 增加 hint usage 时,模型并不会相应更多地 verbalize 这种使用,因此 CoT monitoring 不能可靠检测捷径或 exploit。
这对安全和解释性都很关键。CoT 可以帮助我们观察模型输出的推理形式,但不能保证它忠实揭示了内部因果过程。
PPT 最后一页还列出 “Mind Your Step (by Step): Chain-of-Thought can Reduce Performance on Tasks where Thinking Makes Humans Worse”。官方 PPT 在这一页没有展开实验细节,所以这里只记住它的提醒:CoT 不是永远正收益;某些任务中,显式思考可能让表现变差。
13. 本讲形成的整体图景
这一讲的知识点可以这样串起来:
- 模型先给 next-token distribution。
- Decoding 决定从分布中走哪条路径。
- Greedy 和 beam search 偏向高概率,但可能重复或局部最优。
- Sampling 提供多样性,但需要 top-k、top-p、temperature 控制长尾风险。
- Reasoning RL 用可验证 outcome rewards 诱发 self-verification、backtracking、long deliberation。
- PPO 能做 RLHF/RLVR,但模型数量、GAE、value network 和 per-token reward 让它很重。
- GRPO 用 group reward z-score 替代 value network,工程更轻。
- DAPO 进一步处理探索、梯度死区和长 CoT 权重问题。
- CoT 和 self-consistency 有效,是因为它们能暴露和聚合模型分布中的 reasoning paths。
- CoT 不一定忠实,不能把生成出来的解释当作内部真实原因。
14. 复习题
- 为什么 greedy decoding 是 myopic?它和 beam search 的关系是什么?
- 为什么最高概率序列可能出现重复?
- Top-k 和 top-p 的截断方式有什么不同?为什么 top-p 更动态?
- Temperature 增大和减小时,token 分布分别怎么变化?
- Best-of-N sampling 为什么对 reasoning task 有用?
- R1-Zero 为什么不用 PRM?这样做带来什么自由和风险?
- R1 系列的七个 findings 中,哪几个说明 SFT 和 RL 是互补的?
- PPO 为什么需要 value network?为什么这会带来计算负担?
- GRPO 的 advantage 为什么可以用 group reward z-score?
- DAPO 的 dynamic sampling 要解决什么梯度问题?
- 为什么 CoT 的收益是 scale-dependent?
- CoT-decoding 为什么说明 reasoning path 可能已经存在于模型分布中?
- locality of experience 如何解释 step-by-step reasoning?
- 为什么 CoT monitoring 不能可靠检测模型是否用了捷径?