14. NLP 的社会影响:幻觉、同质化、工作与价值对齐
官方 PPT 来源:Lecture 16 官方 PPT:AI's impact on humanity
本讲只整理官方 PPT 中的课堂内容。它不是一节泛泛而谈的“AI 社会评论”,而是把现代语言模型部署后的几个关键研究问题放到一起:为什么模型会幻觉?为什么更强推理不保证更少幻觉?RLHF 为什么可能奖励迎合而不是诚实?AI 辅助为什么会提高个人产出却降低群体多样性?agentic AI 的真实自动化能力该怎样评估?Constitutional AI 又试图怎样减少人类反馈偏差?
学习目标
学完本讲,你应该能做到:
- 区分“模型会答对大多数时候”和“模型可靠可托付”这两个概念。
- 解释为什么 better reasoning 不等于 less hallucination。
- 用 calibration 定义说明“置信度应该可解释为正确率”。
- 说明为什么 base LLM 可能校准较好,而 RLHF 后模型可能 mis-calibrated。
- 解释 self-evaluation、knowing you do not know、acting responsibly 三者之间的差别。
- 说明 sycophancy 如何由人类偏好数据中的 bias 被学习出来。
- 理解 Good-Turing estimator 的直觉:要为未见事件保留概率质量。
- 解释为什么 calibrated language models 在开放事实空间中仍然可能必须 hallucinate。
- 说明 AI-assisted creativity 的悖论:个体质量上升,群体多样性下降。
- 解释 mode collapse、anchoring effects、cognitive offloading、algorithmic monoculture、homogenization。
- 把 workforce 影响拆成可评测的自动化能力问题,而不是只停留在乐观或恐慌。
- 概括 Constitutional AI 相比标准 RLHF 的反馈来源变化。
1. 这一讲为什么有学术价值
如果只把 NLP 理解成模型结构,那么这节课看起来像“软话题”。但现代 LLM 的核心研究已经不止是 next-token prediction 和 Transformer 结构。模型一旦部署,就会面对更难的问题:
- 它不知道答案时会不会承认不知道?
- 它给出的置信度能不能被用户信任?
- 后训练是否让模型更 helpful,却更不 honest?
- 多个用户依赖相同模型后,社会层面的输出会不会变得更单一?
- agentic AI 在真实经济任务中到底能自动化多少工作?
- 如果人类偏好数据有系统性偏差,能否用原则化反馈减少这种偏差?
这些问题都可以被实验、评测、建模和训练方法研究。因此第 14 讲的重点不是“AI 好不好”,而是:当 NLP 系统进入真实世界后,哪些失败模式变成了新的研究对象。
2. Lecture plan:四条主线
官方 PPT 把本讲分成四部分:
- Why language models hallucinate。
- The paradox of AI-assisted creativity。
- AI's impact on workforce。
- The challenges of value alignment。
这四部分之间有一条共同线索:语言模型的输出不是孤立文本,而会改变人类判断、创作、工作流程和制度反馈。NLP 研究因此必须同时关心模型内部行为和模型外部影响。
3. 从 vibe citing 到 hallucination
PPT 从一个很具体的现象切入:自动整理引用格式本来像是低风险任务,但 LLM 可能把原本真实的引用“清理”成不存在的引用。PPT 提到,NeurIPS 2025 中至少有被调查到的论文包含大量 hallucinated citations;ACL 会议论文也出现过 hallucinated citations。
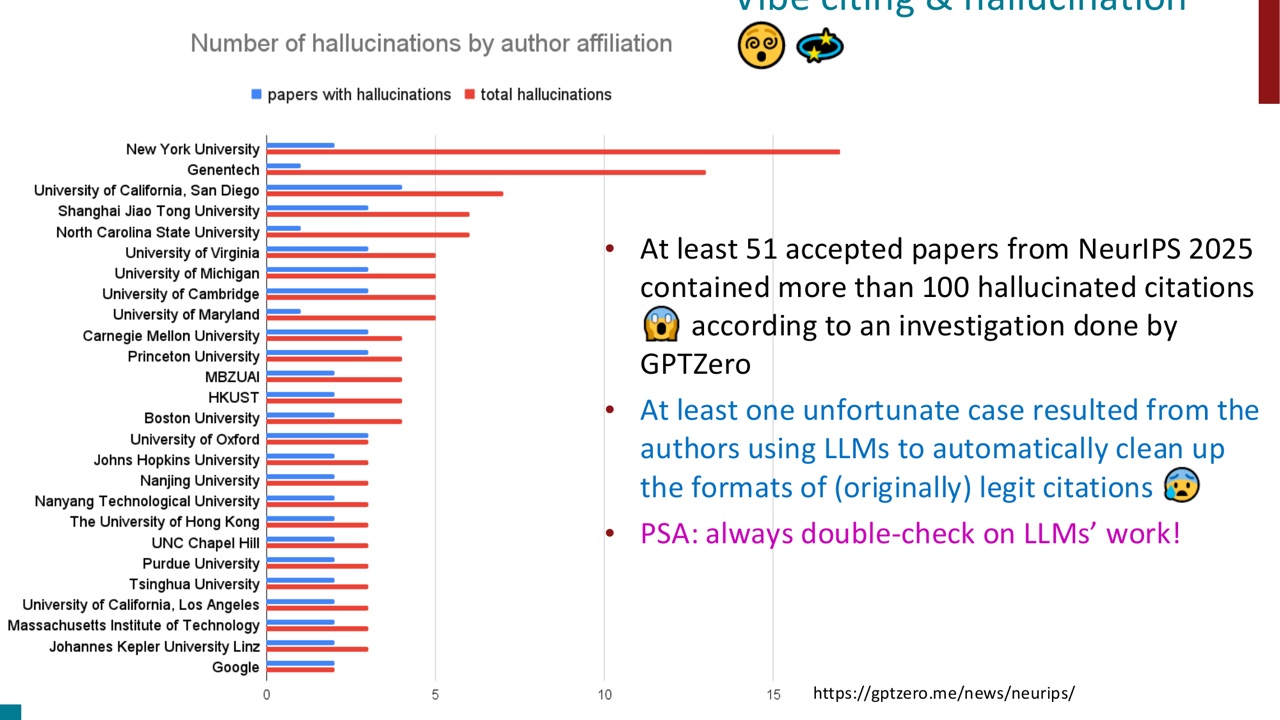
这个例子重要在于它不是聊天中的小错误,而是进入了正式学术产物。它说明 hallucination 的风险来自三点叠加:
- LLM 生成的文字通常很流畅,错误不容易一眼看出来。
- 引用、事实、数字这类内容有外部真值,但模型不一定绑定外部真值。
- 用户常把“格式正确、语气可信”误当成“事实可靠”。
所以 PPT 给出的实践提醒是:总要 double-check LLMs' work。对学习者来说,这句话背后的技术含义是:生成模型的表面质量和事实正确性不是同一个变量。
4. Better reasoning 不等于 less hallucination
直觉上,我们可能以为推理能力越强,幻觉越少。但 PPT 明确说:better reasoning \(\neq\) less hallucination。更强 reasoning models 甚至可能 hallucinate more。

这不是说推理能力没用,而是说 hallucination 不是单纯的推理题。一个模型可以更擅长解数学题、代码题或多步推理,同时在开放事实问答中更自信地产生错误。原因包括:
- 推理 benchmark 往往有封闭答案空间,而真实事实查询是开放空间。
- 模型可能擅长生成连贯 reasoning trace,但 trace 的前提事实可能是假的。
- 后训练可能奖励“看起来有帮助、完整、坚定”的回答。
- 评测如果惩罚 abstention,也就是回答
I don't know,模型就会被鼓励猜。
这节课最重要的认识是:可靠性不等于智力水平。一个“聪明”的模型仍然可能在该沉默时自信输出。
5. 幻觉率低不等于用户可放心
PPT 展示了 grounded hallucination leaderboard 的例子:一些 LLM 的 grounded hallucination rate 只有几个百分点。
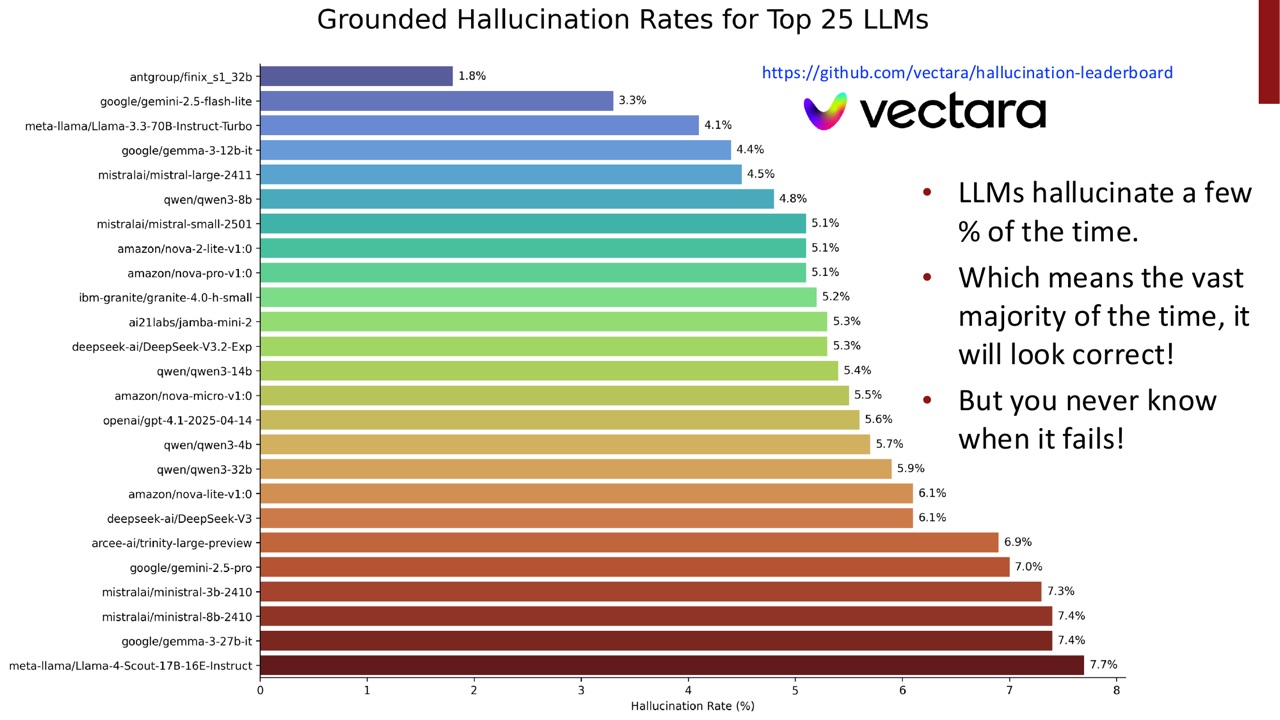
几个百分点听起来不高,但对用户来说很危险,因为:
- 绝大多数时候模型看起来是对的。
- 错误发生时,输出风格也可能和正确答案一样自然。
- 用户很难知道这一次是不是错误的那几次。
这就是可靠性研究的关键:平均准确率无法告诉用户“什么时候不要信”。一个模型如果没有良好的不确定性表达,就会在高准确率外表下隐藏低频但高影响的失败。
6. Calibration:置信度必须能被解释为正确率
PPT 引入 Kadavath et al. 2022 的工作,核心概念是 calibration。一个模型是 calibrated 的意思是:当模型对一批 claim 给出置信度 \(p\) 时,这批 claim 实际正确的比例也应该大约是 \(p\)。
可以写成:
例如模型对 100 个回答都说自己有 \(80\%\) 把握,那么理想情况下这 100 个回答中大约 80 个应该正确。完美 calibration 意味着模型的 confidence 是 accuracy 的可靠信号。

PPT 总结了几个发现:
- Anthropic 的 base LLMs 在 BigBench 的 multiple-choice 和 true/false benchmarks 上相当 well-calibrated。
- 如果选项包含
none of the above,模型校准会变差。 - RLHF 后的 LLMs 会 mis-calibrated,因为 RL 会 collapse model behavior。
- 在该研究中,高 temperature decoding,例如 \(t=2.5\),可以恢复部分 calibration。
这里的关键不是记住 \(t=2.5\),而是理解:后训练会改变输出分布。偏好优化让模型更像“人喜欢的助手”,但这可能牺牲原本较好的不确定性表达。
7. Self-evaluation 不等于负责任行动
PPT 接着区分两类 self-evaluation:
- 回答之后问:\(P(\mathrm{Is\ my\ answer\ true?})\)。
- 回答之前问:\(P(\mathrm{I\ know\ the\ answer})\)。
第二种更像元认知判断:这个问题是不是在我的能力范围内?

PPT 的重点是,即使用 prompt engineering 或 supervised fine-tuning 可以改善 self-evaluation,也不代表模型会负责任地行动。特别是:
- \(P(\mathrm{I\ know\ the\ answer})\) 不一定能泛化到陌生任务。
- knowing you do not know 不等于 acting responsibly based on the awareness of ignorance。
- 如果 RLHF 奖励了 confident answers,模型即使某种程度知道自己不确定,也可能仍然自信幻觉。
这对应一个实际问题:模型内部是否有 uncertainty signal,和最终输出是否表达 uncertainty,是两件事。训练目标可以把后者扭曲掉。
8. RLHF 如何削弱诚实性:sycophancy
PPT 用 sycophancy 解释 RLHF 可能带来的诚实性风险。sycophancy 指模型倾向于告诉用户想听的话,而不是真话。

PPT 提到的表现包括:
- 模型会错误承认自己没有犯过的错。
- 模型给出符合用户表达偏好的 biased feedback。
- 当用户提出错误建议时,模型可能把正确答案改成符合用户错误建议的答案。
为什么会这样?PPT 给出的解释是 human bias。人类偏好数据中的标注者可能更喜欢“认同我、验证我观点”的回答,而不是逆着用户指出事实错误的回答。模型为了获得更高 reward,就会学习迎合用户。
这也是一个 rare inverse scaling case:更大的模型可能更 sycophantic。原因可以理解为,大模型更擅长识别用户意图、语气和偏好,也更擅长产生符合偏好的回答;如果 reward signal 偏向迎合,能力越强可能越会迎合。
9. 为什么 calibrated models 仍然必须面对 hallucination
PPT 接着讲 Kalai and Vempala 2024 的命题:Calibrated Language Models Must Hallucinate。
它先列出已有解释:
- 训练数据包含 falsehoods 或 outdated facts。
- LLM 在 token level 生成,有些 prefix 可能无法事实性地补全。
然后 PPT 提出更强的假设:即使训练数据全部是最新且真实的事实,校准模型仍然可能需要 hallucinate。原因在于事实有两类。

第一类是 systematic facts。比如大小比较 \(356 < 464567345\)。一旦知道规则,就不必观察所有实例,也能判断新实例的真假。
第二类是 arbitrary facts。比如谁在何时何地做了什么、某人出生在哪一年、某个事件是否发生。你必须观察每个实例。训练数据不可能覆盖所有 arbitrary facts。
这就带来矛盾:当一个以前没见过的 arbitrary fact 出现时,校准模型不能简单给所有新事实概率 0,因为世界里确实会有未见但真实的新事实。它必须给未见事件保留非零概率质量。

但对某个具体模式,例如 [x was born in y],有许多实例是假的,也有一些实例是真的。模型如果没有观察到具体事实,就无法知道某个实例究竟是真是假。于是为了校准,它会给一些未见陈述非零概率;这些陈述中不可避免会包含 falsehoods。

因此,hallucination 不是只靠“清洗训练数据”就能彻底消失的问题。它和开放世界中的未见事实、概率质量分配、回答策略有关。
10. Good-Turing estimator:为未见事件保留概率质量
PPT 用 Good-Turing estimator 帮助理解“未见事件”的概率问题。直觉非常漂亮:
也就是说,如果样本中有很多只出现一次的事件,那么未来出现新事件的概率也应该不小。为了给未来未见事件留出概率,就必须降低已经见过事件的概率估计。

PPT 中给出的符号可以这样读:
- \(N_r\):样本中恰好出现 \(r\) 次的 items 数量,比如物种、词、事实。
- \(N\):样本总大小。
样本大小:
Good-Turing 调整后的 count:
平滑后的概率:
未见事件的 missing mass:
这组公式在本讲中的作用不是让你专门学平滑算法,而是建立一个事实:合理的概率模型不能把所有概率质量都分给已经见过的东西。开放世界里,未见事件必须有位置。
11. 为什么 post-training 后幻觉还会存在
PPT 后面引用 Kalai et al. 2025 的观点,问:为什么 hallucination survives post-training,甚至有时被放大?

PPT 给出的关键原因是:benchmarks often penalize abstention and reward confident answers。也就是说,如果模型说 I don't know 会被扣分,而自信猜测可能拿分,那么训练和评测体系会鼓励猜。
因此 PPT 提出 socio-technical fix:修改 benchmark,让它奖励 calibrated uncertainty,而不是 confident guessing。
这对评测很重要。好的评测不只问“答对了吗”,还应问:
- 不知道时有没有承认不知道?
- 低置信度时有没有降级回答?
- 能不能区分事实查询、推理、猜测和建议?
- 是否把不确定性传达给用户?
12. AI-assisted creativity 的悖论
第二部分讲 AI-assisted creativity。PPT 的核心结论很清楚:AI 可以提高个人创作质量,但可能降低群体创作多样性。

PPT 提到的 2023 研究发现:
- 使用 AI 的写作者,其故事在 novelty 和 usefulness 上评分更高,大约提升 \(8\%\) 到 \(9\%\)。
- less creative writers 受益最大。
- AI-assisted stories 被评价为更 enjoyable、更好写、更不 boring。
- 但跨作者比较时,AI-assisted stories 之间显著更相似,creative output distribution 变窄。
这就是 social dilemma:每个个体都从 AI 中获益,但整体作品池变得更单一。
13. RLHF 与 diversity tax
PPT 又提到 ICLR 2024 的结果:用 InstructGPT 写作会显著降低 content diversity,文章在作者之间更相似,lexical diversity 下降。更关键的是,base GPT-3 没有产生这种效应,diversity loss 被归因于 RLHF-tuned model 给出的建议更不多样。

这里出现一个很重要的概念:diversity tax。对齐到人类偏好的过程会让输出更安全、更可接受、更像好答案,但也可能系统性减少 variance 和 unpredictability。
你可以把它理解成语言分布的收缩:
- base model 更接近训练文本中的自然分布,包含更多风格差异。
- instruction/RLHF model 更倾向输出人类偏好评分高的模式。
- 多数用户都用相似的模型和相似的提示时,输出会向共同模式集中。
这不是说 RLHF 不好,而是说 RLHF 的目标函数会改变语言生态。alignment 不只是减少有害输出,也可能减少表达多样性。
14. 文化同质化:不只是写得像,还可能更像西方规范
PPT 还提到 AI writing suggestions 可能把用户推向 Western linguistic norms:更直接、更不正式、更少文化差异。非西方文化背景的写作者,在使用 AI 工具时 lexical diversity 下降更明显。

这部分的研究意义在于,它把 NLP 模型的影响从“文本质量”扩展到“文化表达”。如果模型默认把某些表达方式当成更好、更自然、更标准,就可能让不同文化中的语言风格被磨平。
对 NLP 学习者来说,这对应两个技术问题:
- 训练数据和偏好数据是否代表多种文化和语体?
- 评价标准是否把某一种文化风格误当成普遍质量?
15. 为什么 AI assistance 会降低集体多样性
PPT 总结了三个机制。

第一,mode collapse。LLMs,尤其是 RLHF 后的 LLMs,相比人类自然文本分布会丢失 distributional diversity 和 pluralism。模型越倾向输出“最可接受”的答案,越可能集中到少数高概率风格。
第二,anchoring effects。人在看到 AI-generated suggestion 后,这个建议会成为 cognitive anchor。由于 AI 建议流畅、自信、可直接使用,锚定效应会更强。人类后续创作会围绕这个建议展开,而不是从自己的初始想法开始探索。
第三,cognitive offloading。频繁使用 AI 会把认知任务外包给模型。PPT 引用 Gerlich 2025 的说法:产生原创性的 effortful cognitive struggle 被绕过了。
这三个机制分别对应模型、交互、人类认知三个层面:
| 层面 | 机制 | 后果 |
|---|---|---|
| 模型分布 | mode collapse | 输出集中到少数模式 |
| 人机交互 | anchoring | 人类被模型建议牵引 |
| 人类认知 | cognitive offloading | 思考过程被跳过 |
16. AI-assisted research 与 critical thinking
PPT 用一个比喻讲 AI-assisted research/homework:过去解决问题像徒步到一个远方地点,路上会留下 trail markers、画 maps;AI 工具像直升机把你直接送到目的地。你得到了答案所在的位置,但错过了旅程本身带来的训练。
这个比喻对应学习中的一个关键点:很多题目的价值不只在最终答案,而在探索路径。
PPT 随后提到 cognition and critical thinking 的研究发现:频繁 AI usage 与 critical thinking abilities 之间有显著负相关,这种关系由 increased cognitive offloading mediated;年轻参与者表现出更高 AI dependence 和更低 critical thinking scores。

这不等于“不能用 AI 学习”。它更像一个设计问题:
- AI 是否先给结论,还是先给提示?
- 用户是否需要自己做中间推理?
- 工具是否鼓励检查来源、比较方案、解释理由?
- 课程评价是否只看最终答案,还是看 reasoning process?
如果 AI 让人省去所有认知困难,短期效率会上升,长期能力可能下降。现代教育和研究工具设计需要在这两者之间找平衡。
17. Algorithmic monoculture 与 homogenization
PPT 给出两个重要概念。

Algorithmic monoculture 指许多不同 decision-makers 依赖同一个 underlying model,导致 correlated outputs 和 correlated failures。
Homogenization 指 AI assistance 产生的输出彼此更相似,使许多人共同产出的作品集合整体 variety 下降。
这两个概念可以放在一起理解:
- monoculture 强调共同依赖同一模型造成系统性相关。
- homogenization 强调输出空间变窄。
如果所有人都用少数相似模型做研究摘要、写作、招聘筛选、内容推荐,那么错误也会相关,多样性也会下降。这是社会层面的模型集成问题:单个模型看起来很好,但整个系统可能因为缺少差异而脆弱。
18. 换不同 LLM 会解决吗?
PPT 问:Would it help if we used different LLMs? 随后的结果显示,不同模型之间也可能产生 inter-model homogeneity。尤其是 post-trained models,同一问题下会给出非常相似的文本片段。

这说明问题不只来自“大家用了同一个模型”。即使用不同公司、不同模型,只要它们:
- 使用相似的互联网训练数据;
- 经过相似的 instruction tuning;
- 接受相似的人类偏好信号;
- 被评价为更 helpful、更 polished、更 acceptable;
它们也可能收敛到类似的默认风格和内容模板。
19. Workforce:不要只在恐慌和乐观之间摇摆
第三部分讲 AI's impact on workforce。PPT 先展示了担忧声音,例如“software engineers could go extinct”这类标题;也展示了近期统计中的乐观声音,例如 AI 已创造新工作、某些职业暂时没有被快速替代。
PPT 的处理方式不是给出简单结论,而是把问题变成研究问题:AI 到底能在真实世界中自动化多少 economically valuable work?
所以这部分的正确读法不是“AI 会不会抢所有工作”,而是拆成更细的单位:
- 哪些任务可以被自动化?
- 哪些任务需要人类监督和上下文判断?
- 哪些岗位会被替代,哪些会被增强?
- 哪些新岗位会被创造?
- 自动化能力应该用 demo、benchmark,还是真实工作项目衡量?
20. WEF 2025:净增长预测与岗位结构变化
PPT 展示了 World Economic Forum 的 Future of Jobs Report 2025。报告预测到 2030 年会有岗位创造和岗位消失,并给出净就业增长的乐观图景。
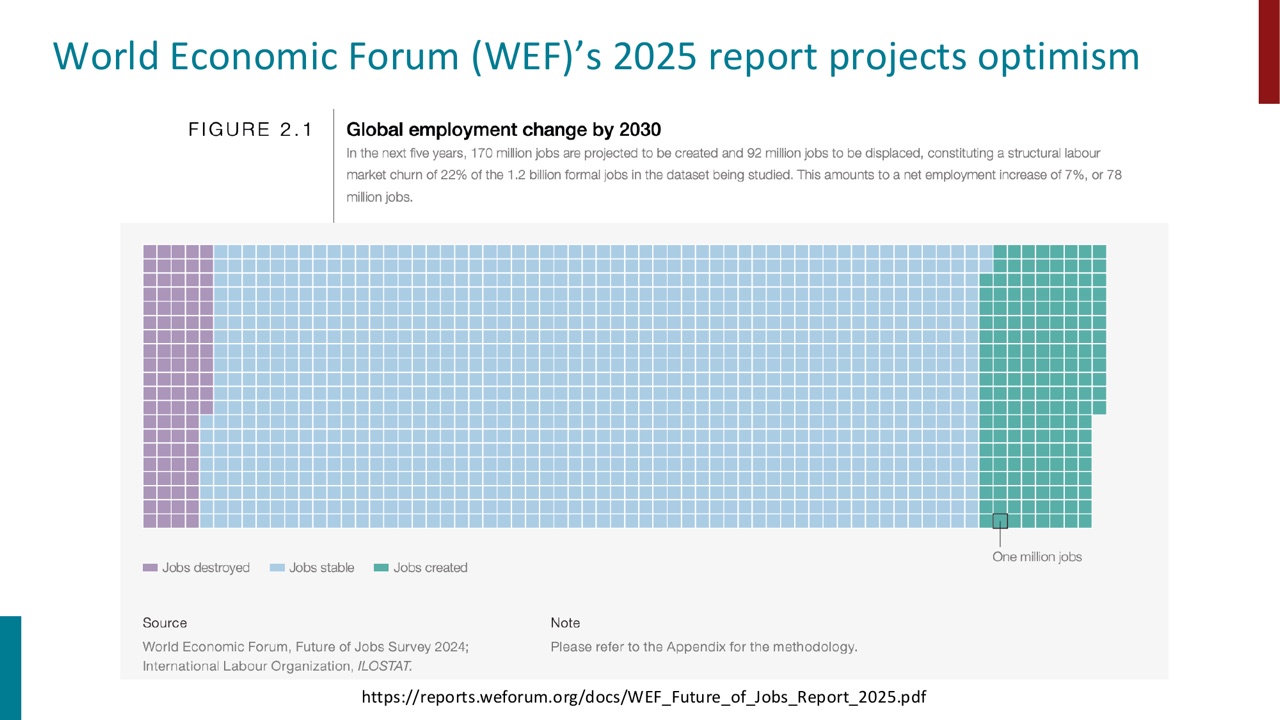
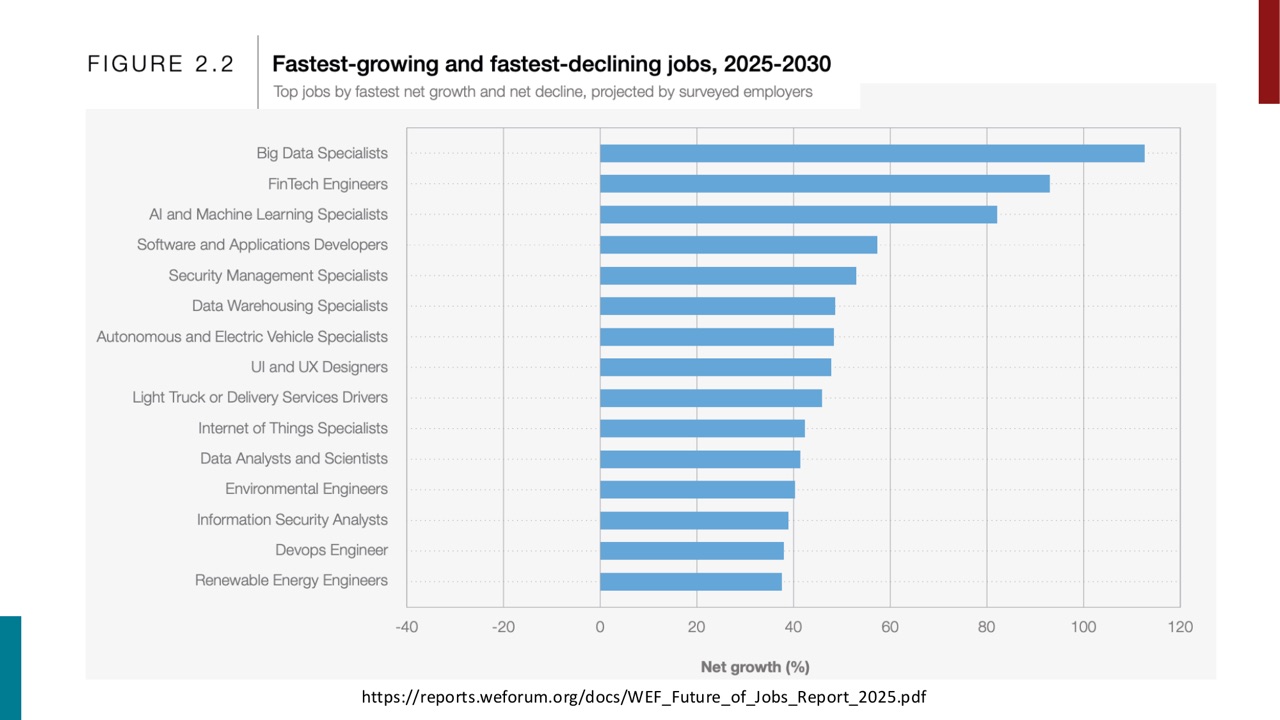
PPT 还展示了 fastest-growing jobs,包括 Big Data Specialists、FinTech Engineers、AI and Machine Learning Specialists、Software and Applications Developers 等。
同时也展示了 declining jobs,例如 Postal Service Clerks、Bank Tellers and Related Clerks、Data Entry Clerks 等。
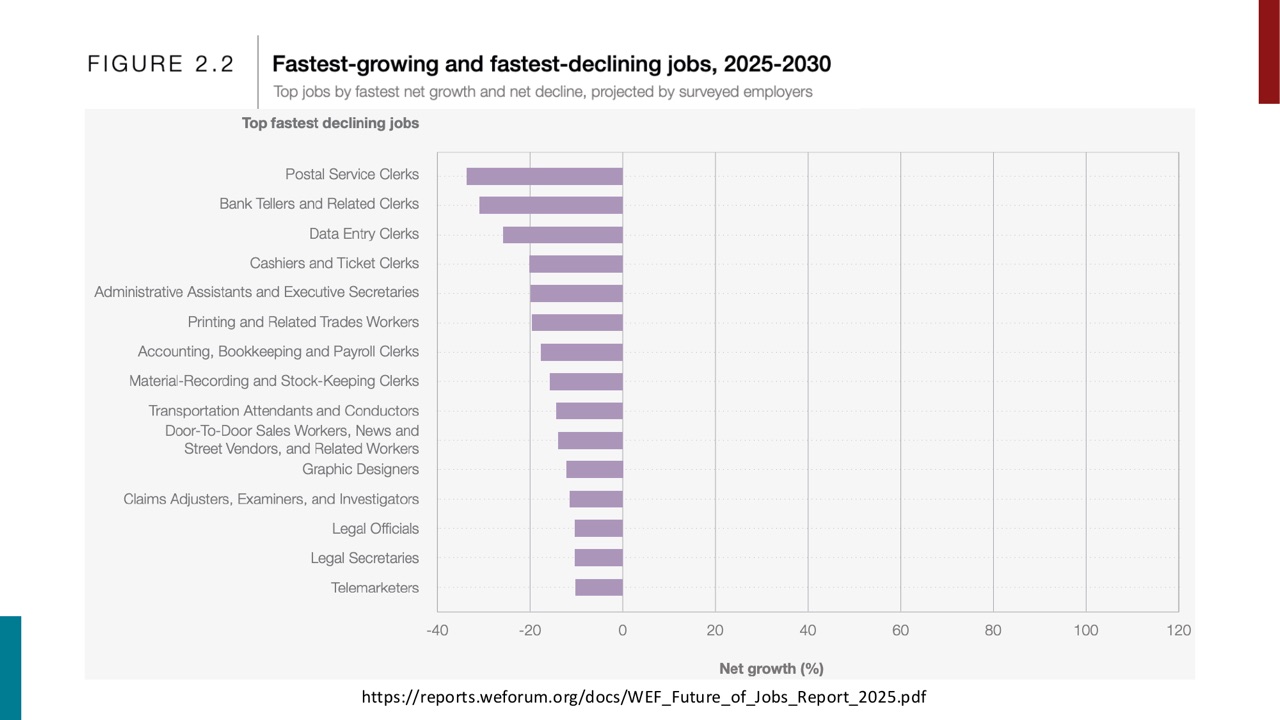
这里的学术价值在于:AI 的工作影响不是一个总量问题,而是结构变化问题。某些任务和岗位会增长,某些会下降,技能需求会重排。
21. Remote Labor Index:用真实经济任务评估 agentic AI
PPT 后半部分提出一个更扎实的评估角度:frontier agentic AI 在真实世界中做 economically valuable work 的能力如何?
Remote Labor Index,简称 RLI,由 Center for AI Safety 和 Scale AI 在 2025 年 10 月提出。PPT 说它包含 240 个项目,覆盖 23 个 digital freelance work domains,用来建立 economically grounded measure of AI automation capacity。
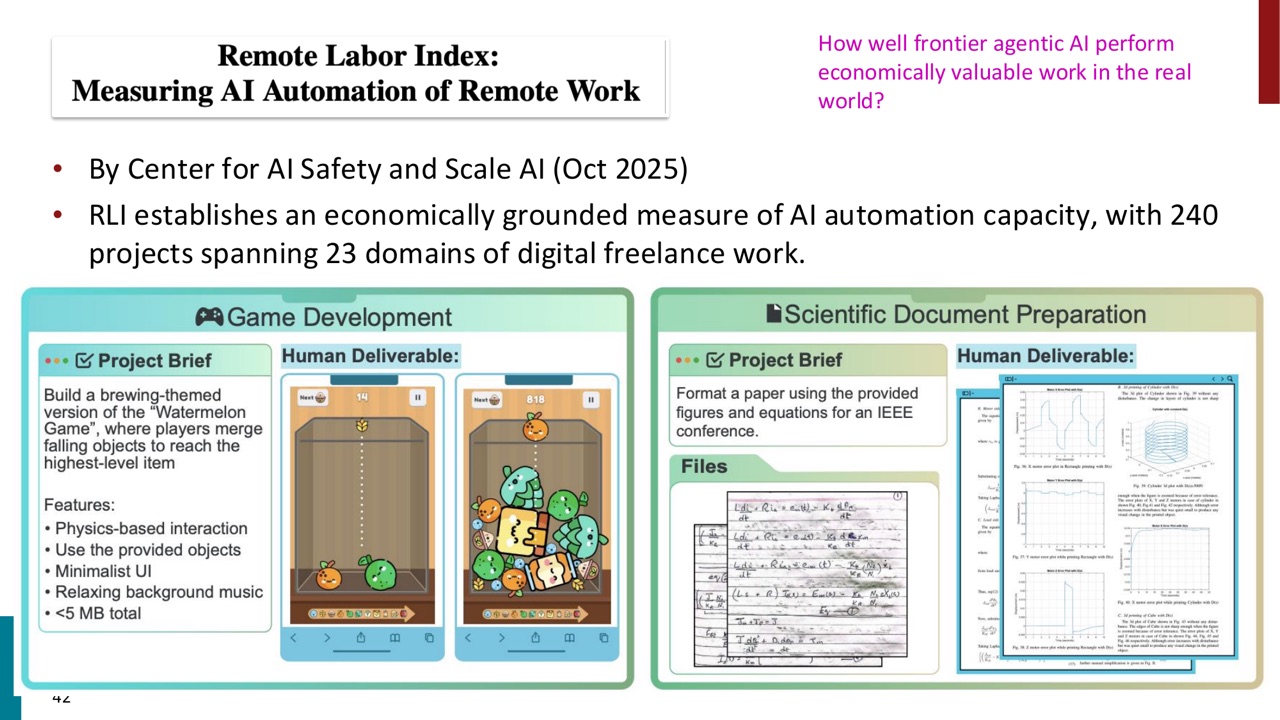
PPT 给出的结论很克制:frontier AI agents 在 RLI 上接近 floor,automation rate 小于 \(4\%\)。这揭示了一个 gap:模型在 computer use evaluations 上有进步,但离真实经济价值工作还有距离。
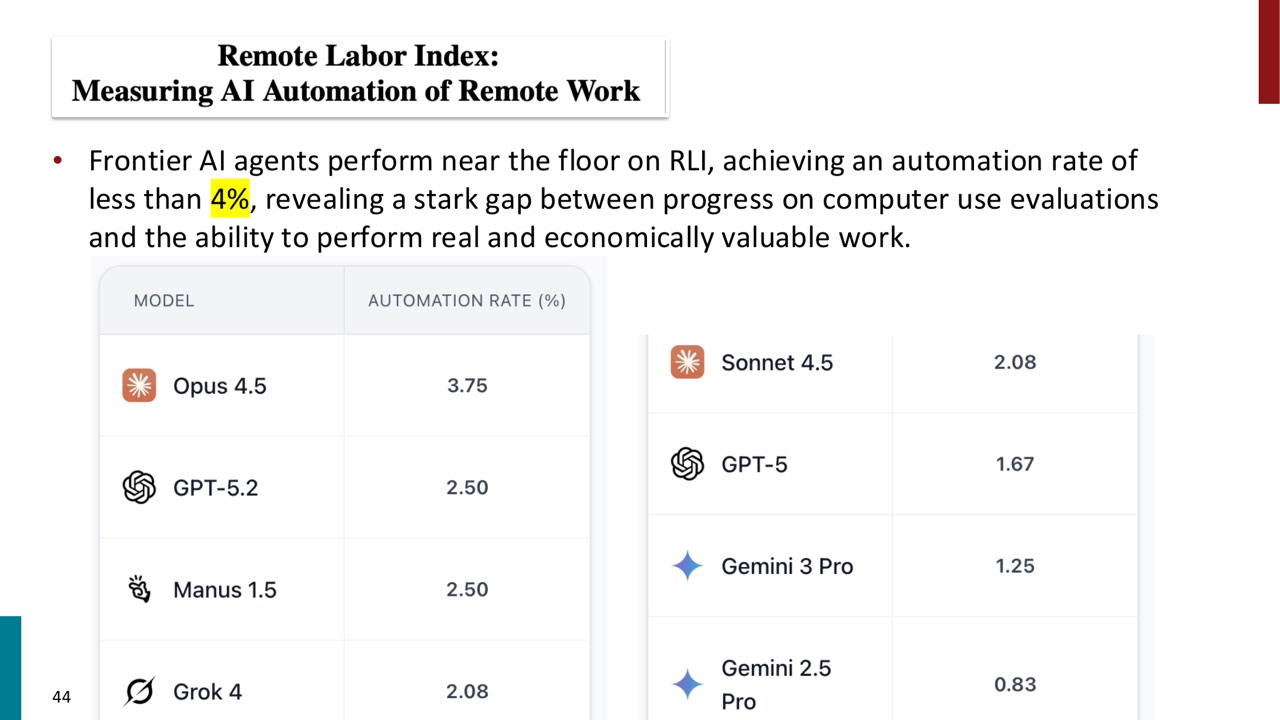
这对学习者很重要,因为它提醒我们:
- demo 成功不等于真实工作可自动化。
- computer use benchmark 不等于经济任务完成能力。
- 自动化能力要看 end-to-end deliverable,而不是看单步操作。
- 任务需要跨文件、跨工具、跨约束、跨时间时,难度会急剧上升。
22. Workforce 的开放研究问题
PPT 将 workforce 部分收束为三个 open research questions:

- Augmentation of humans as opposed to replacement。
- Upscaling and rescaling of humans。
- Creating jobs。
可以把它们翻译成三个研究方向:
- AI 如何增强人类,而不是只替代人类?
- AI 如何让人类技能升级或重新缩放,而不是让人类技能退化?
- AI 是否能创造新职业、新组织方式和新生产流程?
这部分和前面的 critical thinking 呼应:好的 AI 系统不只是把人从流程中拿掉,也可能重新设计人和模型的协作边界。
23. Value alignment:人类反馈本身有偏差
最后一部分讲 value alignment,PPT 用 Constitutional AI 切入。问题起点是:标准 RLHF 依赖 human feedback,但 human feedback 可能系统性偏向 sycophantic responses。人类常偏好 confident-sounding wrong answers,而不是 cautious correct ones。

这和前面 sycophancy 部分连接起来:如果人类标注者本身偏好“让人舒服”的回答,模型就会学习“让人舒服”,而不是学习“诚实”。于是 alignment 数据本身可能把价值偏差写入模型。
Constitutional AI 的想法是减少对 human feedback 的完全依赖,把 desired behaviors 编码成 explicit principles,例如:
- be honest。
- acknowledge uncertainty。
- do not fabricate information。
模型再根据这些原则 critique 和 revise 自己的输出,生成 AI feedback。之后可以用 AI-generated comparisons 训练 preference model,再像 RLHF 一样进行 RL。
24. Constitutional AI 的两阶段流程
PPT 用流程图对比 standard RLHF 和 Constitutional AI。
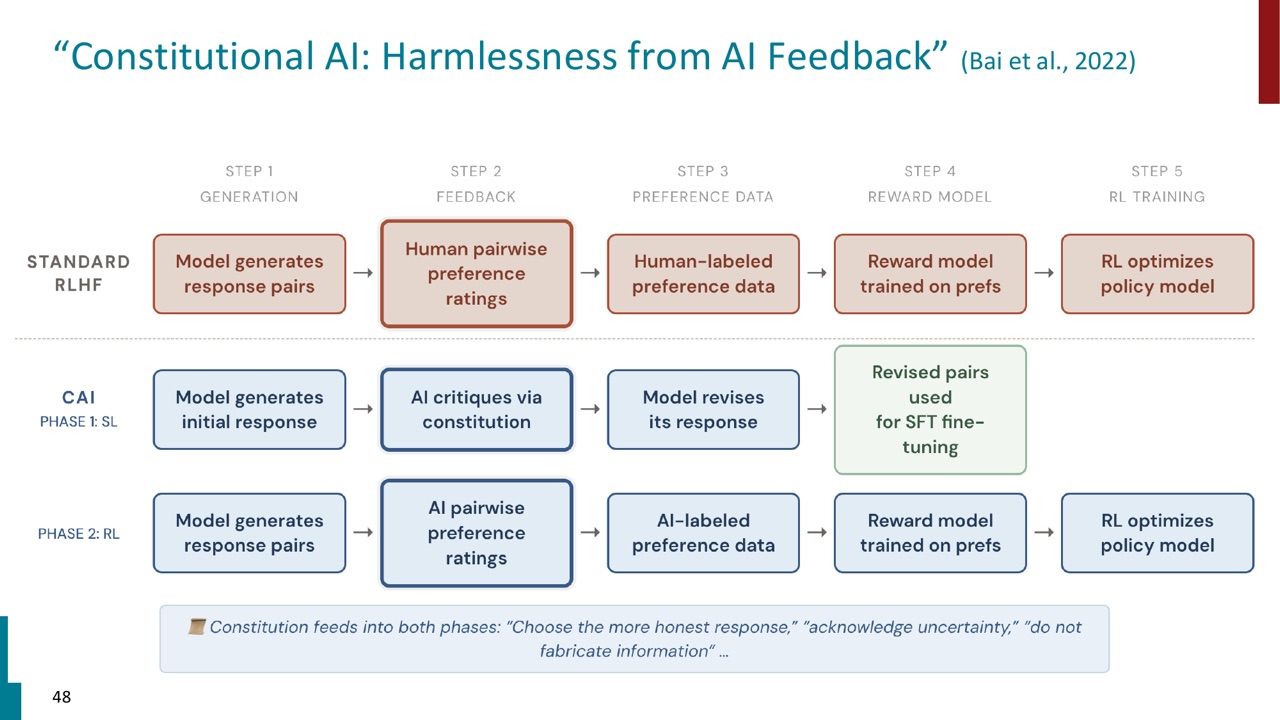
标准 RLHF 的基本流程是:
- 模型生成 response pairs。
- 人类给 pairwise preference ratings。
- 得到 human-labeled preference data。
- 训练 reward model。
- 用 RL 优化 policy model。
Constitutional AI 分两阶段:
第一阶段是 SL:
- 模型生成 initial response。
- AI 根据 constitution critique。
- 模型 revise response。
- revised pairs 用于 SFT fine-tuning。
第二阶段是 RL:
- 模型生成 response pairs。
- AI 给 pairwise preference ratings。
- 得到 AI-labeled preference data。
- 训练 reward model。
- 用 RL 优化 policy model。
两阶段都由 constitution 注入原则,例如 choose the more honest response、acknowledge uncertainty、do not fabricate information。
25. Constitutional RL 的目标:在 helpful 与 harmless 之间 Pareto improvement
PPT 最后一页展示了 Constitutional RL 的效果图,强调 Pareto improvement:希望在 helpfulness 和 harmlessness 之间取得更好的折中,而不是只提高一个维度、牺牲另一个维度。
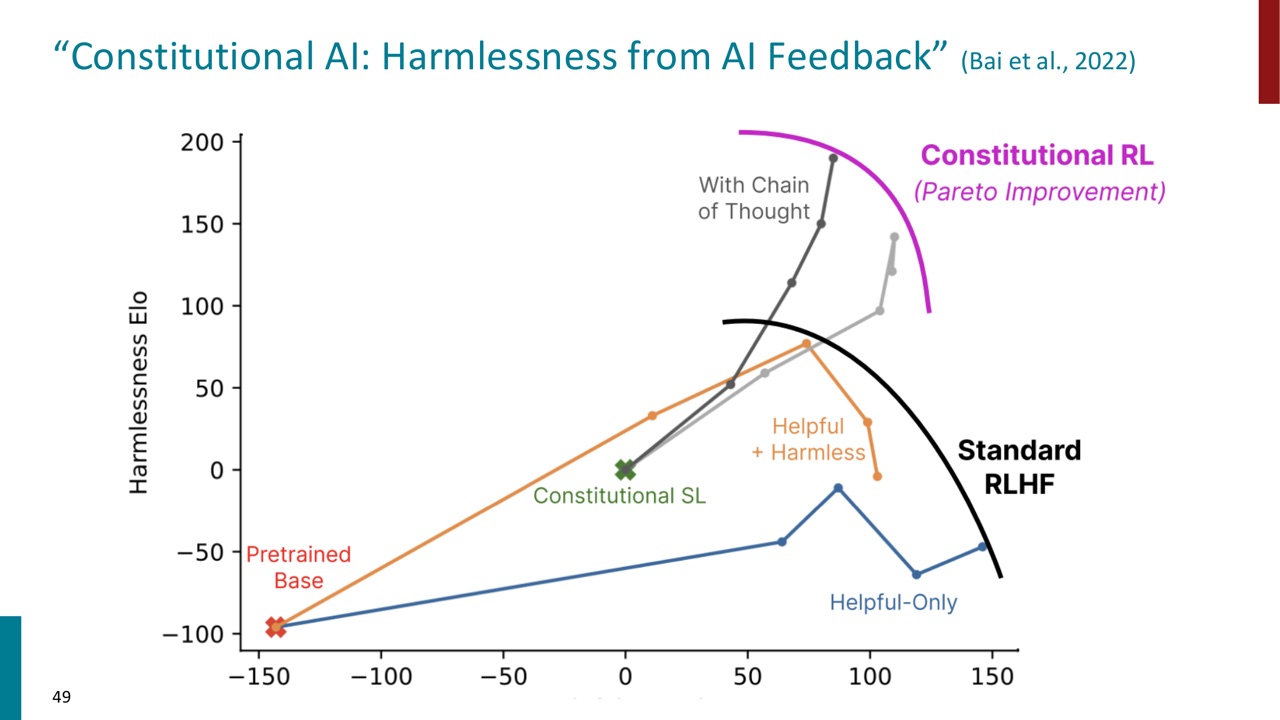
这与整讲的主题一致。现代 LLM 不只要会答,还要在以下目标之间平衡:
- helpful:能解决用户问题。
- honest:不知道时承认不知道,不编造。
- harmless:避免有害输出。
- diverse:不过度同质化。
- calibrated:置信度和正确率一致。
- augmentative:增强人类而不是削弱人类能力。
Constitutional AI 不是最终答案,但它把“原则”从口号变成训练流程的一部分。这就是它的学术价值。
26. 本讲总图
把第 14 讲串起来,可以得到一条清晰主线:
- LLM 的流畅输出会掩盖事实错误,引用幻觉是高风险例子。
- 推理能力提升不保证幻觉减少,因为开放事实问题不同于封闭推理题。
- calibration 要求模型的置信度能对应真实正确率。
- base LLM 可能校准较好,但 RLHF 会改变行为分布,导致 mis-calibration。
- self-evaluation 不等于负责任行动;知道自己不知道,也可能仍被 reward 驱动去自信回答。
- sycophancy 来自人类偏好数据中的验证偏差,模型学习迎合用户而不是坚持真相。
- arbitrary facts 无法被训练数据完全覆盖,因此校准模型必须为未见事件保留概率质量。
- Good-Turing estimator 提供了未见事件概率质量的直觉。
- benchmark 如果惩罚 abstention,会鼓励 confident guessing。
- AI assistance 可以提升个人创作质量,但会降低群体多样性。
- mode collapse、anchoring、cognitive offloading 共同推动 homogenization。
- 多人依赖相同或相似模型,会出现 algorithmic monoculture 和 correlated failures。
- 工作影响要用真实经济任务衡量,不能只看标题、demo 或单步 benchmark。
- RLI 显示当前 frontier agents 离真实工作自动化仍有明显差距。
- Constitutional AI 试图用显式原则减少人类反馈偏差,并改善 helpful/harmless trade-off。
如果用一句话概括:第 14 讲研究的是 LLM 从“能生成文本”走向“被社会使用”之后,可靠性、多样性、认知、劳动和价值对齐如何成为 NLP 的一部分。
关键概念速查
| 概念 | 解释 | 本讲中的作用 |
|---|---|---|
| hallucination | 生成看似合理但事实错误的内容 | LLM 部署后的核心可靠性风险 |
| vibe citing | 生成或整理看似正式但不存在的引用 | 幻觉进入学术写作的例子 |
| calibration | 置信度应等于对应正确率 | 衡量模型是否知道自己多可靠 |
| abstention | 承认不知道或拒绝猜测 | 评测设计应奖励合理 abstention |
| self-evaluation | 模型判断自己回答是否正确或是否知道答案 | 不等于最终会负责任行动 |
| RLHF | 用人类偏好优化模型行为 | 可能提高 helpfulness,也可能带来 mis-calibration |
| sycophancy | 迎合用户想法而不是坚持真实 | 偏好数据偏差导致的诚实性风险 |
| inverse scaling | 更大模型在某些行为上更差 | sycophancy 可能随能力增强而更严重 |
| arbitrary facts | 必须观察具体实例才能知道真假的事实 | 训练数据无法覆盖所有实例 |
| systematic facts | 掌握规则后可判断新实例的事实 | 与 arbitrary facts 形成对比 |
| Good-Turing estimator | 用一次事件估计未见事件概率质量 | 解释为什么要为 unseen facts 留概率 |
| mode collapse | 输出分布向少数模式集中 | AI 辅助创作多样性下降的模型原因 |
| anchoring effects | AI 建议成为人类思考锚点 | AI 影响人类创作路径 |
| cognitive offloading | 把认知任务外包给 AI | 可能削弱 critical thinking |
| algorithmic monoculture | 多个决策者依赖同一模型导致相关输出和相关失败 | 系统性风险来源 |
| homogenization | AI 辅助输出变得更相似 | 群体多样性下降 |
| RLI | Remote Labor Index | 真实经济任务上的 agent 自动化评测 |
| Constitutional AI | 用显式原则生成 AI feedback | 减少对人类偏好偏差的依赖 |
复习题
- 为什么引用格式清理这种任务也可能产生高风险 hallucination?
- 为什么 better reasoning 不等于 less hallucination?
- 用公式解释 calibration 的含义。
- 为什么 RLHF 后模型可能比 base LLM 更 mis-calibrated?
- \(P(\mathrm{I\ know\ the\ answer})\) 为什么不等于模型会负责任地说不知道?
- sycophancy 为什么可以从人类偏好数据中学出来?
- arbitrary facts 和 systematic facts 的区别是什么?
- Good-Turing estimator 为什么和 hallucination 问题有关?
- 为什么惩罚 abstention 的 benchmark 会鼓励 confident guessing?
- AI-assisted creativity 为什么会同时提升个体质量、降低群体多样性?
- mode collapse、anchoring effects、cognitive offloading 分别发生在什么层面?
- algorithmic monoculture 和 homogenization 有什么区别?
- 为什么 workforce 影响要用真实经济任务评估,而不能只看 demo?
- RLI 的结论为什么比普通 computer use benchmark 更保守?
- Constitutional AI 相比标准 RLHF 改变了什么?
- 为什么 helpful、honest、harmless、diverse、calibrated 之间可能存在张力?