13. 分词与多语言
官方 PPT 来源:Lecture 14 官方 PPT:Tokenization and Multilinguality
本讲只整理官方 PPT 中的课堂内容。它回答一个很容易被低估的问题:语言模型为什么不能直接读字符串?为什么一个看似工程预处理的 tokenizer,会影响模型的拼写能力、跨语言迁移、公平性、推理成本,甚至会制造 glitch tokens?
学习目标
学完本讲,你应该能做到:
- 解释 word、morpheme、character、byte、subword、token、vocabulary、token ID 之间的关系。
- 比较 word tokenization、character/byte tokenization、subword tokenization 的优缺点。
- 手动走完一次 BPE 训练中的 pair 统计、merge、词表扩张和 test-time tokenization。
- 说明为什么 subword tokenizer 会让拼写、字符串反转、typo robustness 这类任务变难。
- 解释 glitch token 的根源:tokenizer 训练数据和语言模型训练数据不一致。
- 说明多语言模型为什么需要跨语言共享表示,以及 vocabulary overlap 为什么有助于 cross-lingual transfer。
- 理解 curse of multilinguality:固定模型容量下,语言越多不一定越好。
- 用 subword fertility 解释 tokenization 如何带来多语言成本和效果不公平。
- 说明为什么 character/byte-level model 和 latent tokenization 又重新变成重要研究方向。
1. 为什么 NLP 模型需要 tokenization
自然语言的原始形式是字符串。模型真正能处理的是向量和张量,因此从文本到模型输入之间必须经过一层离散化:
官方 PPT 先把问题拆成两步:
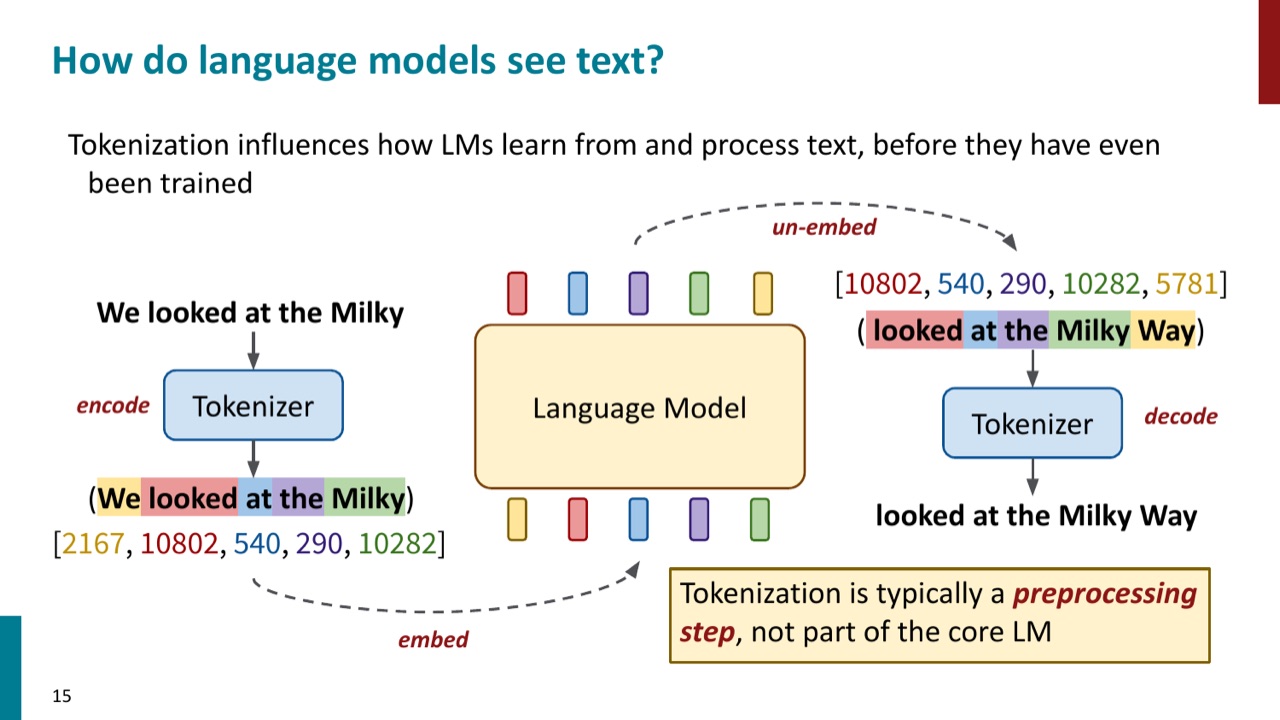
- tokenizer 负责把一段 text 编码成 token 序列,再把 token 序列解码回 text。
- vocabulary 是 tokenizer 认识的全部 token 集合;每个 token 会映射成一个 token ID。

初学者最容易误会的一点是:token 不一定等于词。一个 token 可以是一个词,也可以是一个子词、一个字符、一个 byte,甚至是空格加某个片段。tokenization 的选择决定了模型“看见语言”的基本颗粒度。
2. 语言单位本来就不唯一
PPT 从 word、morpheme、character、phrase 这些单位讲起,是为了提醒你:语言并没有一个天然、唯一、适合所有模型和所有语言的切分单位。
常见单位可以这样理解:
- word:日常意义上的词,比如
looked、Milky Way中的Milky。 - morpheme:带有意义的最小语素,比如
looked可以拆成look和过去式后缀。 - character:字符层面的单位,比如英文中的字母、中文里的汉字、表情符号。
- phrase:短语层面的单位,比如
Milky Way作为一个整体短语。
这些单位各有价值。词通常语义清晰,字符覆盖面强,语素更贴近构词规律,短语能保留固定表达。问题是,模型必须选一个可计算的离散单位体系;tokenization 就是在这几个目标之间做取舍。
3. Tokenizer 在训练前就改变了学习问题
tokenization 不是训练之外的小工具,而是在训练前就改变了模型看到的数据分布。
PPT 给出的流程是:
如果 tokenizer 把一个词拆得很碎,模型就必须在更长的 token 序列上学习它的含义;如果 tokenizer 把某个片段作为整体 token,模型就会给它单独的 embedding。换句话说,tokenizer 决定了模型参数要为哪些离散单位服务。
这会直接影响两个效率指标:
- 序列长度:token 越细,输入越长,Transformer 的注意力计算越重。
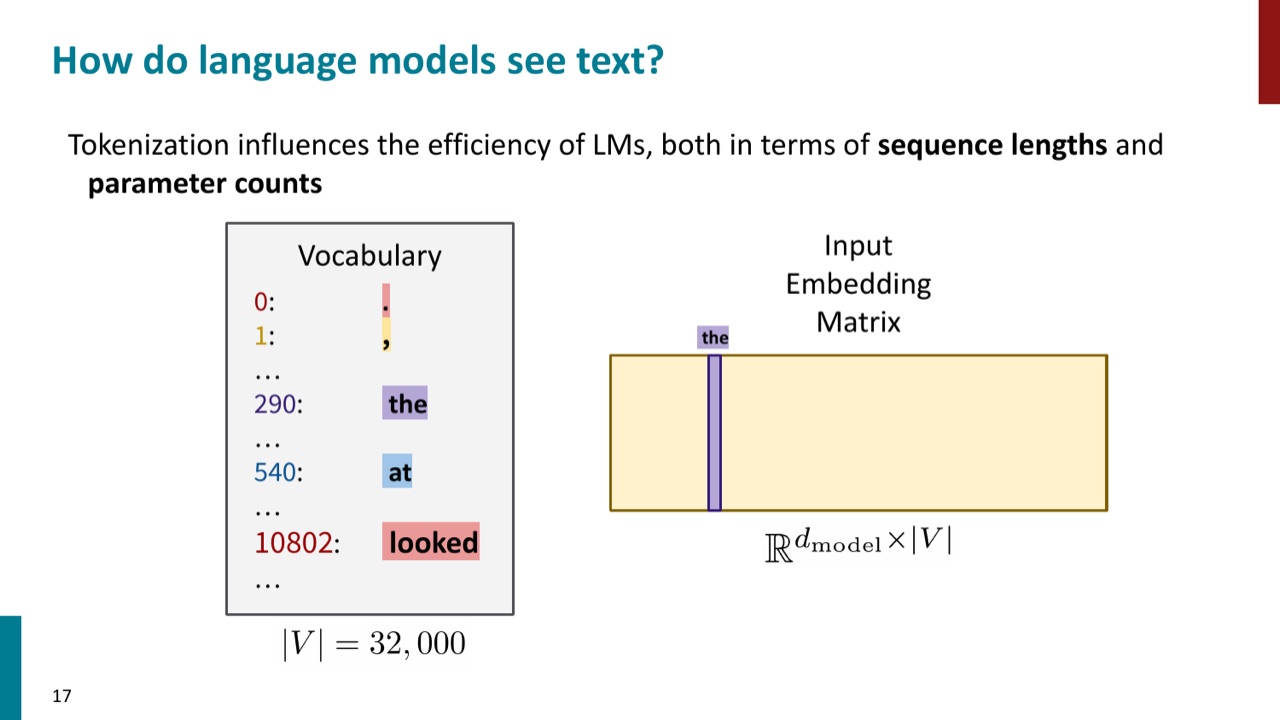
- 词表大小:token 越粗,vocabulary 越大,embedding matrix 和输出层越大。
如果词表大小是 \(|V|\),embedding 维度是 \(d_{\mathrm{model}}\),那么输入 embedding 矩阵大致可以写成:
所以 tokenizer 的粗细会在两类成本之间摇摆:小词表导致长序列,大词表导致大 embedding 和输出空间。
4. Word tokenization:直观,但会撞上长尾和 OOV
最直观的做法是把词当 token。对英语来说,可以先近似理解为按空格和标点切分。这种方式的吸引力很明显:词通常是人类可解释的语义单位,一个词对应一个 embedding,序列长度也比较短。
但 word tokenization 很快会遇到三个问题。
第一,词表会非常大。自然语言词汇不是均匀分布,而是服从长尾分布。高频词很少,低频词和罕见词极多。PPT 用 Zipf 分布提醒我们:有大量词出现次数很少,但它们加起来又无法忽略。
第二,语言一直在变化。新词、人名、产品名、拼写变体、口语写法、网络词都会不断出现。如果训练词表没有见过,就会出现 out-of-vocabulary,也就是 OOV。
第三,没有空格分词的语言会让“按词切分”本身变难。中文、日文、泰文等语言不能简单依赖空格。即使在英语里,缩写、连字符、复合词、标点也会让规则变复杂。

处理 OOV 的传统方式是把未知词映射为 UNK。但这样会丢失信息:StanfordNLP2026、一个罕见人名、一个拼写错误,都可能被压扁成同一个未知符号。模型知道“这里有个未知东西”,却不知道它内部长什么样。
5. Character/byte tokenization:覆盖最强,但序列变长
另一端的做法是把文本拆到字符或 byte。
PPT 区分了 character tokenization 和 byte tokenization:
- character tokenization 把每个字符当 token。
- byte tokenization 把 UTF-8 等编码后的每个 byte 当 token。
这两者都能极大缩小词表。byte vocabulary 尤其小,因为 byte 的基本取值空间固定。它们也天然解决 OOV:任何新词、任何拼写、任何罕见名字,最终都可以拆成字符或 byte。

但代价也很明显:序列会变长。一个词级 tokenizer 可能把 strawberry 看成一个 token,字符级会变成 10 个字符,byte-level 对非 ASCII 字符还可能更长。序列变长意味着更多位置、更多注意力计算,也意味着模型要自己从更细碎的单位里组合出词义、语法和语义。
所以 character/byte tokenization 的基本取舍是:
- 优点:词表小、覆盖强、没有 OOV、能直接观察拼写和字符组成。
- 缺点:序列长、计算贵、模型要学习更长距离的组合。
6. Subword tokenization:现代 LLM 的折中方案
subword tokenization 是目前大语言模型最常见的折中。它的核心想法是:
- 高频词和高频片段可以作为整体 token,节省序列长度。
- 低频词可以拆成较小片段,避免 OOV。
- 词表不用像 word vocabulary 那样无限膨胀。
例如一个罕见词不必整个进入词表,也不必完全拆成字符,而是可以拆成若干常见子词。这样模型既能复用子词表示,又能覆盖新组合。

PPT 也提醒:subword 不一定等于语言学上的 morpheme。它经常由数据频率决定,而不是由人类语法规则决定。因此一个 BPE tokenizer 切出来的片段,有时看起来像词根或后缀,有时只是统计上常一起出现的字符块。
常见 subword tokenizer 包括:
- BPE,也就是 Byte Pair Encoding。
- WordPiece。
- Unigram Language Model。
本讲重点讲 BPE。
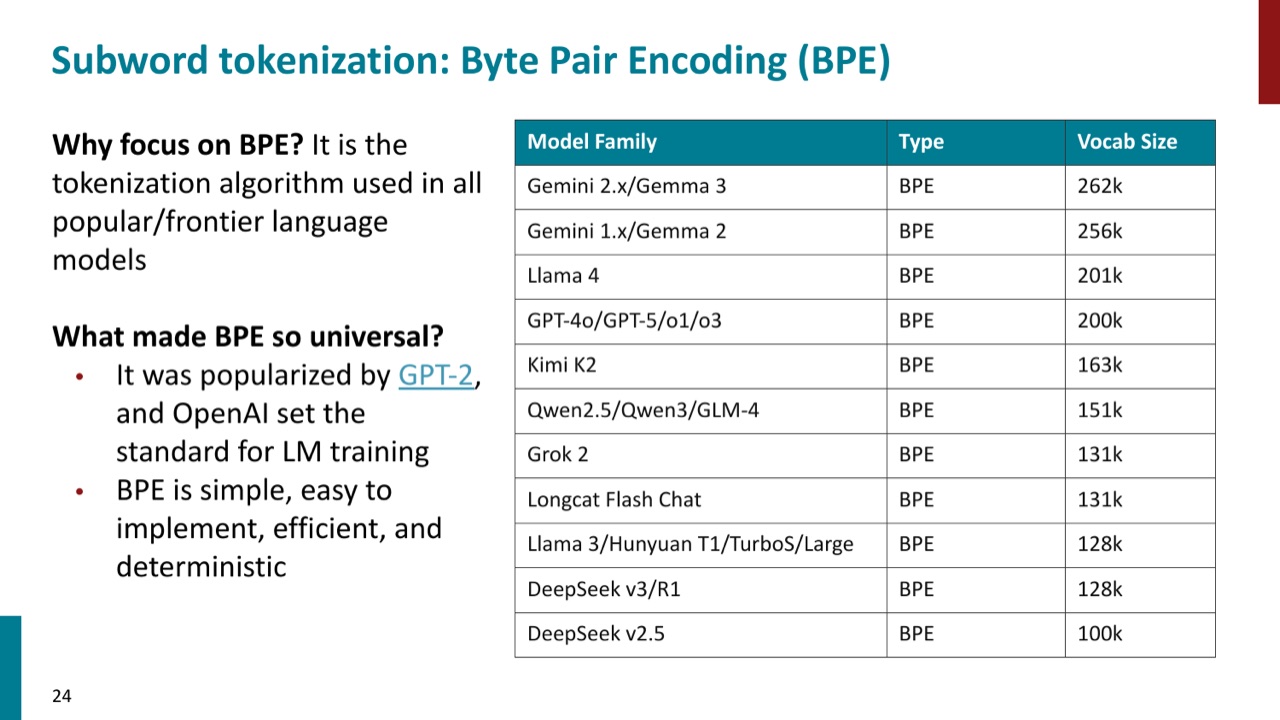
7. BPE 为什么重要
官方 PPT 明确指出,许多 frontier model family 使用 BPE 或 BPE 系 tokenizer。这里的重点不是背模型列表,而是理解为什么 BPE 会成为主流:
- 算法简单:只需要统计相邻 pair 频次并合并。
- 可扩展:能在大语料上训练可控大小的 vocabulary。
- 推理确定:训练得到 merge rules 后,新文本按规则合并即可。
- 工程实用:在覆盖率、序列长度、词表规模之间取得不错平衡。
BPE 的历史直觉来自压缩:如果某两个相邻符号经常一起出现,就把它们合并成一个新符号。放在 NLP 中,这个新符号就是一个新 token。
8. BPE 训练算法
PPT 给出的 BPE 训练过程可以整理成下面的形式。
输入:
- 训练语料 \(D\)。
- 目标词表大小 \(N\)。
初始化:
- 先做 whitespace pre-tokenization,把文本按空格粗略分成片段。
- 词表 \(V\) 初始化为语料中出现的 bytes。
- 把语料 \(D\) 表示成 token 序列,此时 token 还是 byte 级别。
迭代:
while |V| < N:
count all adjacent token pairs in D
choose the most frequent pair (v_i, v_j)
create a new token v_n = v_i v_j, where n = |V| + 1
replace every occurrence of v_i v_j in D with v_n
用数学符号写,某一次 merge 是:
循环终止条件是:

这段算法有几个关键点:
- BPE 每次只合并相邻 token pair。
- 合并依据是当前语料表示中的 pair 频次,而不是语言学规则。
- 新 token 加进 vocabulary 后,语料也会被同步替换。
- 后续统计是在替换后的 token 序列上进行的,所以 merge 会形成越来越长的片段。
- merge 的顺序非常重要,因为 test time 也会按训练得到的顺序应用。
9. BPE 手算:从 Peter Piper 到 _pick
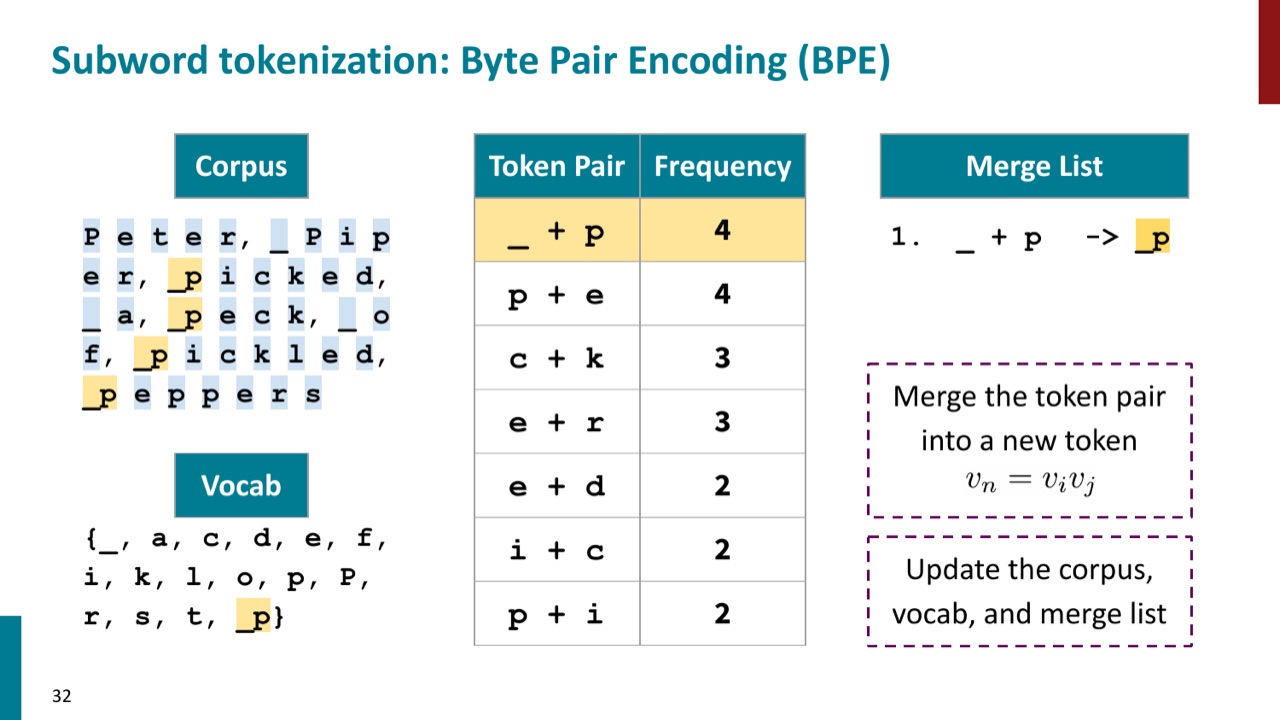
PPT 用一句绕口令做 BPE 示例:
为了表示空格,PPT 把 whitespace 写成 _。训练一开始,语料被拆成 byte 或字符级单位。此时 _、p、e、c、k 这些都是基础 token。
第一步是统计所有相邻 pair。PPT 中最高频 pair 是 _ 和 p。原因很直观:很多以 p 开头的词前面都有空格或句首边界,所以 _p 经常出现。
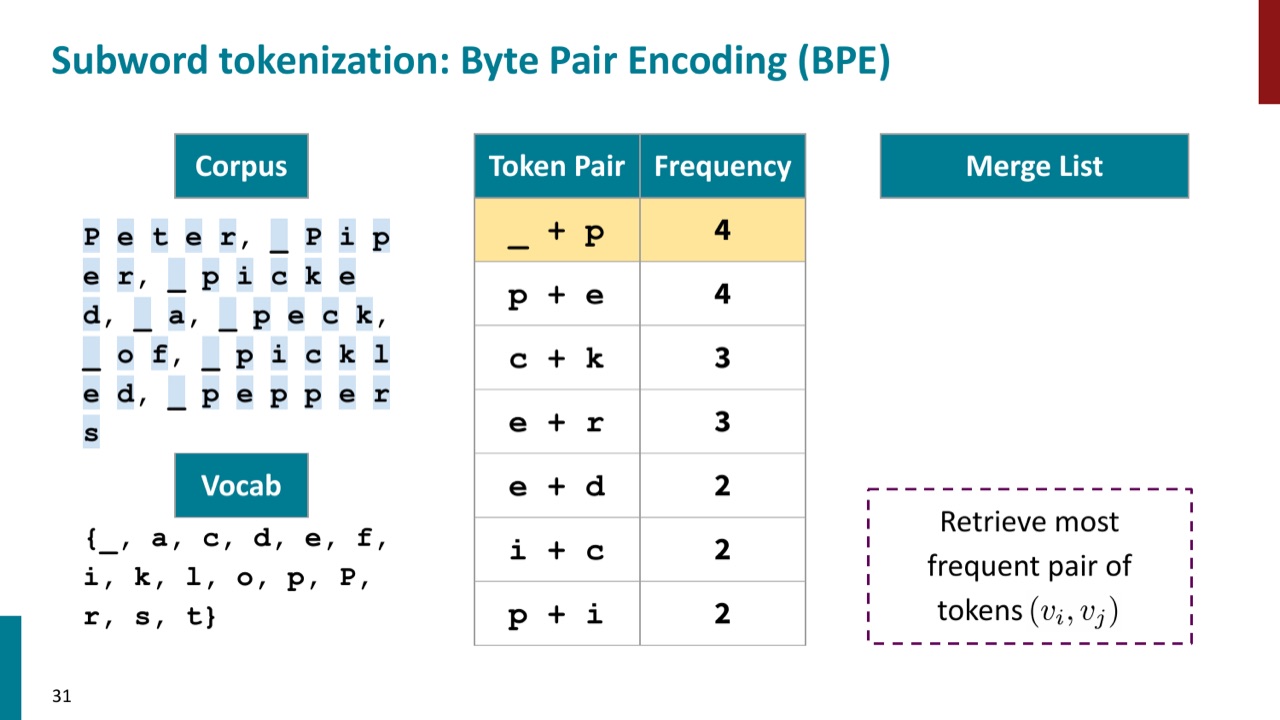
于是第一次 merge 生成新 token:
语料中所有相邻的 _ p 都会被替换成 _p。
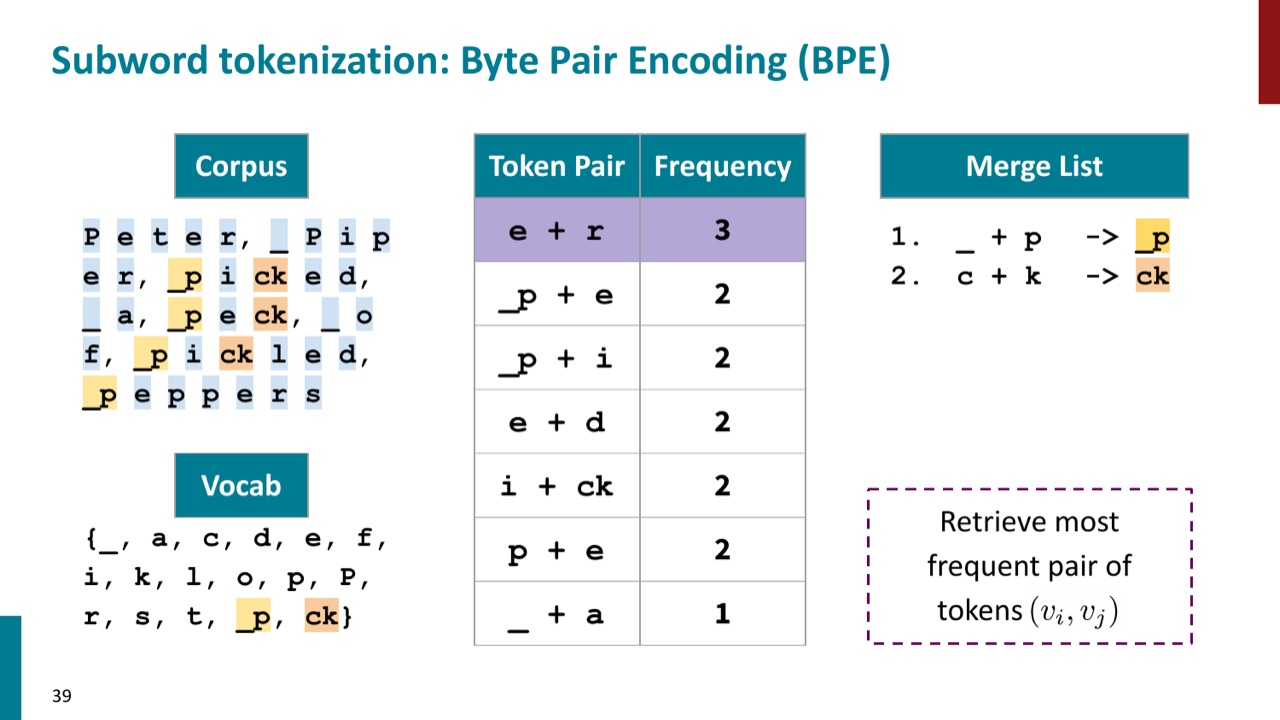
接着继续统计新的相邻 pair。PPT 示例后续会合并 c 和 k 得到 ck,再合并 e 和 r 得到 er。注意,每一次合并都会改变之后的统计单位。
再往后,BPE 会合并 _p 和 e 得到 _pe,合并 _p 和 i 得到 _pi,再合并 _pi 和 ck 得到 _pick。这样,频繁出现的 pick 相关片段就被逐渐建成更大的 token。
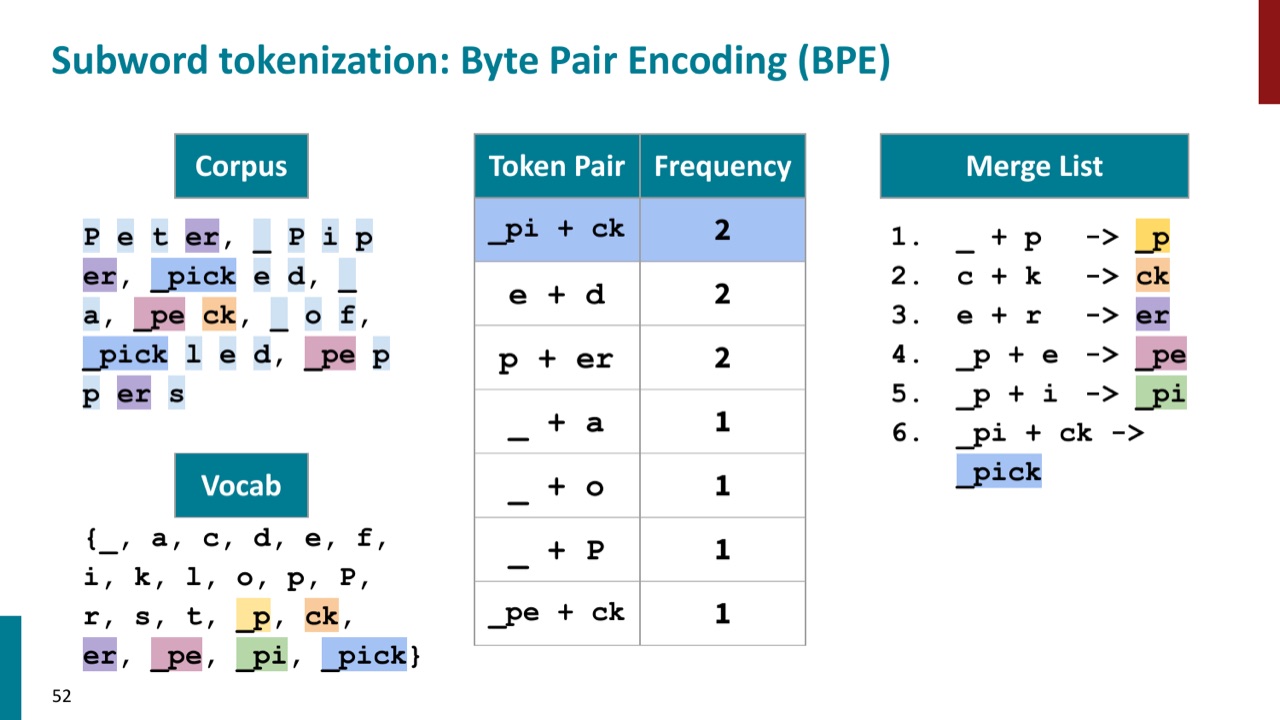
这个例子要记住的不是某个具体 merge,而是 BPE 的机制:
- 先从很小的单位开始。
- 每次找最高频相邻 pair。
- 合并后把新片段当成一个 token。
- 重复以后,常见字符串会变成较大的 subword token。
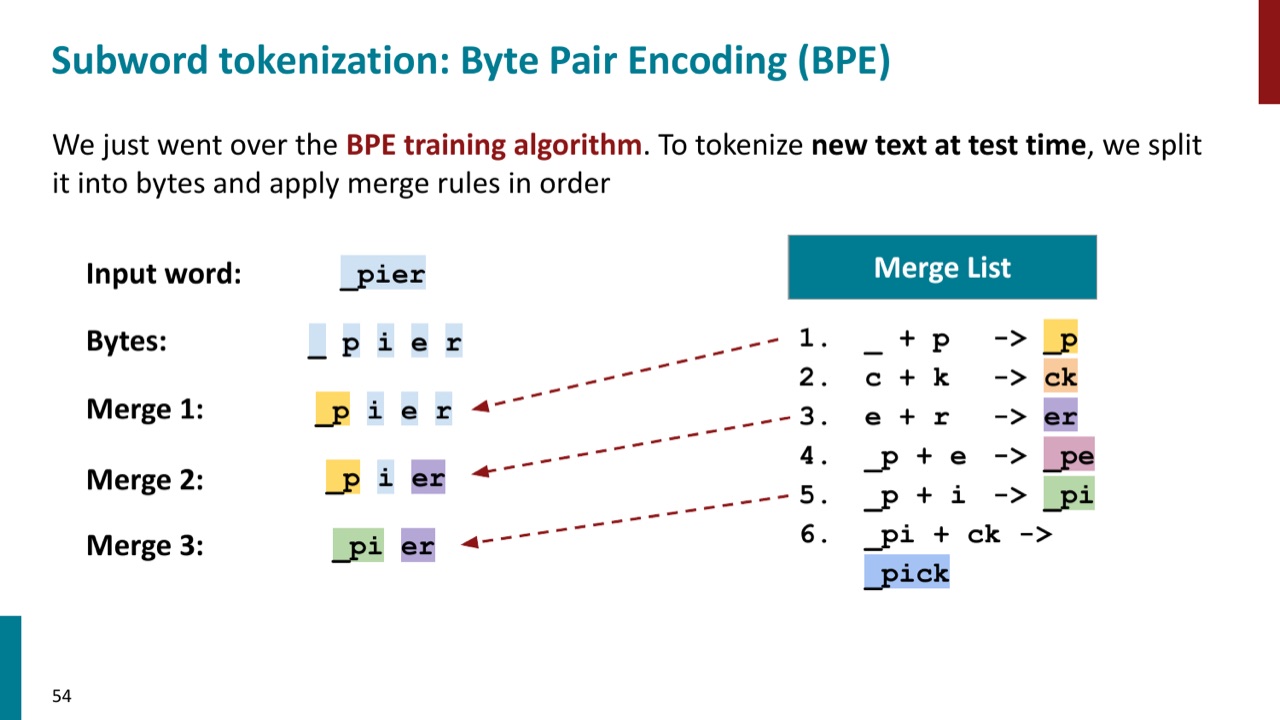
10. BPE test time:为什么 _pier 不会变成 _pick
训练结束后,我们得到一串有顺序的 merge rules。测试时遇到新文本,不再重新训练 tokenizer,而是使用训练好的规则。
PPT 的 test-time 例子是 _pier。初始切分为:
然后按训练时的 merge 顺序应用规则。由于 _ p 是学到的 merge,先得到:
由于 e r 也是学到的 merge,又得到:
由于 _p i 也是学到的 merge,最后得到:
它不会变成 _pick,因为 _pick 需要 _pi 后面跟着 ck,而 _pier 里是 er。这说明 BPE 不是语义猜测器,而是严格按字符片段和 merge rules 运转的确定性程序。
这对理解 LLM 很重要:模型并不是先看到“词”,再理解词义。它看到的是 tokenizer 产生的 token 序列。token 边界错在哪里,模型的输入边界就错在哪里。
11. SentencePiece 与 SuperBPE
PPT 接着提到两个扩展方向。
SentencePiece 是 tokenizer library,而不是某一个单独算法。它实现了 BPE 和 Unigram LM 等方法,并把 whitespace 当作基础符号处理。很多模型使用 SentencePiece 训练或应用 tokenizer,例如 T5、Llama 2、XLM-R、Gemma 和许多 multilingual models。
SuperBPE 的动机是突破 whitespace pre-tokenization 的限制。普通 BPE 经常先按空格切开,再在词内学习 subword;SuperBPE 则先学习 subword,再移除 whitespace 限制,让 tokenizer 可以学到跨越词边界的 superword token。PPT 强调的效果是:用更小词表和更少 inference compute 表示更多内容。

从学习角度看,SentencePiece 告诉我们 tokenizer 是一个可以被系统工程化的组件;SuperBPE 告诉我们 token 边界本身仍然是研究对象,而不是已经定型的标准答案。
12. Case study 1:拼写为什么会难
当用户问模型 How many r's are in strawberry? 时,直觉上这是字符任务。但 subword 模型看到的未必是字符。
PPT 对比了 GPT-2 tokenizer 和 GPT-4o tokenizer 的 strawberry 切分:
- GPT-2 会把它切成类似
str、aw、berry的片段。 - GPT-4o 可以把
strawberry看成一个整体 token。
无论是哪种情况,模型都不是直接拿到一个个字符 s t r a w b e r r y。因此它要数 r,必须从 token embedding 中间接恢复字符组成。这不是不可能,但它不是 tokenizer 直接提供的信息。

这解释了 PPT 提到的几类困难:
- spelling out words:逐字拼写单词。
- reversing strings:反转字符串。
- typo robustness:面对拼写错误或字符扰动保持稳定。
- counting characters:统计某个字符出现次数。
如果 tokenizer 的基本单位是 subword,模型天然更擅长在 subword 级别建模;字符级结构需要额外从 embedding 和上下文中学出来。
13. Case study 2:glitch tokens
glitch token 指的是那些进入 tokenizer vocabulary、但在语言模型训练中几乎没有被充分学习的 token。PPT 用 SolidGoldMagikarp 作为著名例子。
根源是两个训练数据不一致:
- tokenizer 训练数据决定哪些字符串片段会进入 vocabulary。
- LM 训练数据决定模型是否见过这些 token,以及是否学到了稳定 embedding 和输出行为。
如果某个 token 在 tokenizer 训练时出现频率足够高,于是进入词表;但它在 LM 训练语料中很少甚至没有出现,那么它对应的 embedding 就可能接近随机初始化或学习不足。模型遇到它时,就会表现出异常、回避、胡说或无法复述。

PPT 强调这不只是好玩的现象。它带来两个实际问题:
- 词表容量被浪费:一些 token 占着位置,却没有稳定语义。
- 安全风险增加:异常 token 可能成为 adversarial attack surface。
这也再次说明 tokenizer 不是无害的预处理。一个不良词表会把问题直接带进模型内部。
14. 多语言为什么是 NLP 的核心问题
PPT 进入 multilinguality 时先给出背景:世界上有 7000 多种 documented languages。英语很重要,但远远不是全部。世界上说英语的人只占一部分,native English speakers 更少。如果 NLP 只在英语上有效,就会把大多数人排除在外。
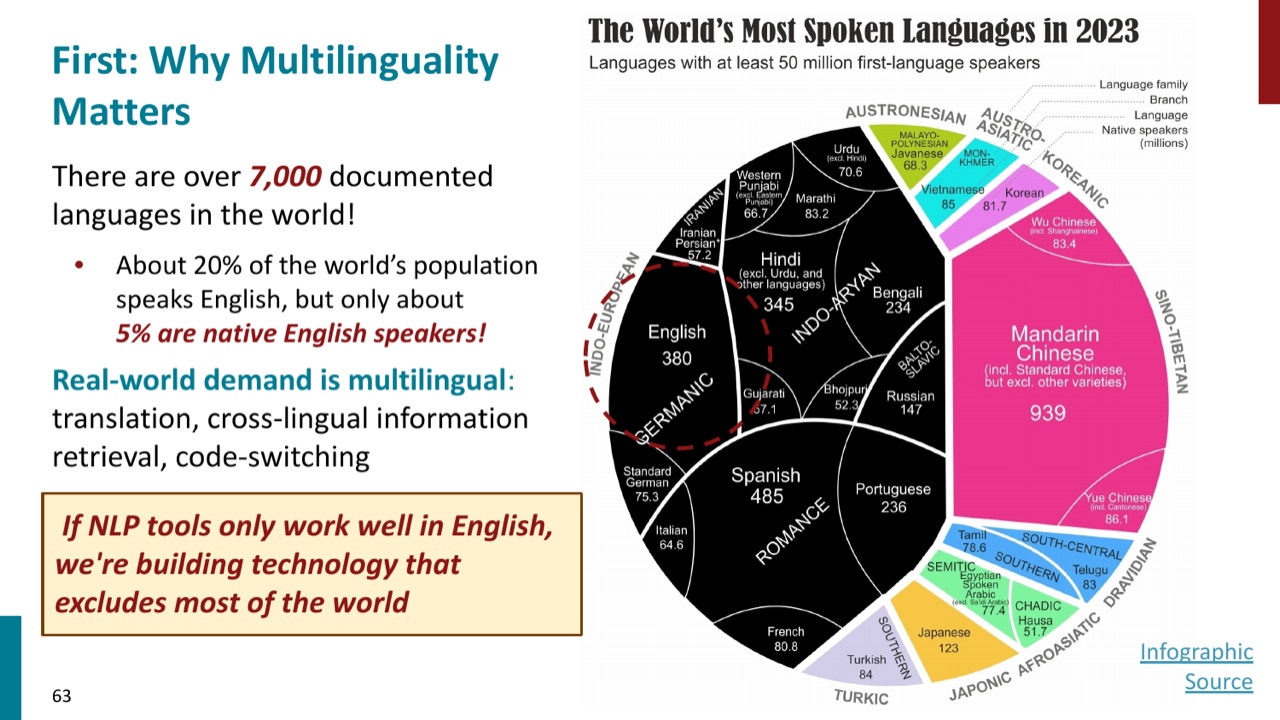
数据分布也极不平衡。Common Crawl 中英语占比很高,而许多低资源语言在网页语料中极少。PPT 用 high-resource languages 和 low-resource languages 区分资源丰富和资源稀缺的语言;一些低资源语言在 Common Crawl 中占比甚至小于 \(0.01\%\)。
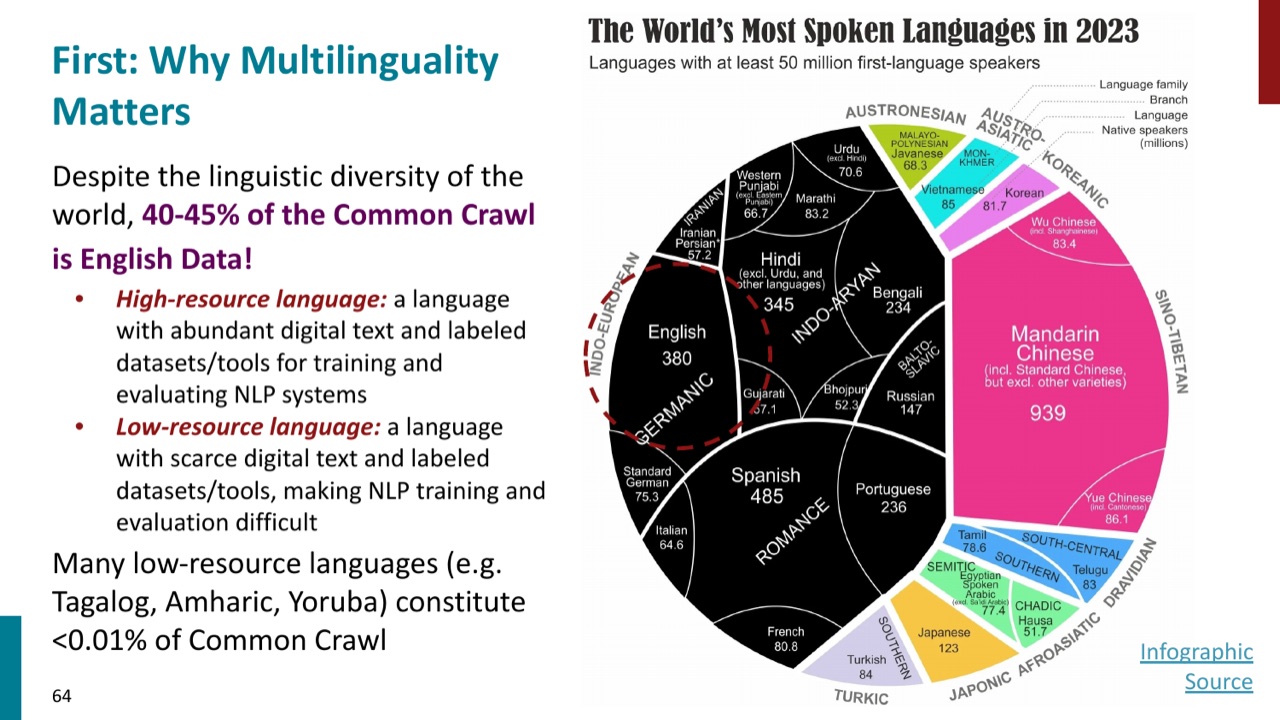
这给多语言模型带来两个目标:
- 高资源语言不能因为加入更多语言而明显退化。
- 低资源语言需要从共享模型和其他语言中获得迁移收益。
15. 多语言模型与 cross-lingual transfer
多语言语言模型和单语言语言模型在架构和训练目标上不一定不同。PPT 的说法是:核心差异通常在训练数据。多语言模型的 tokenizer 训练数据和 LM 训练数据都来自多种语言。

这种设定最重要的能力之一是 cross-lingual transfer。PPT 给出的典型流程是:
- 用英语标注数据 fine-tune 一个任务,例如自然语言推理。
- 在另一个语言上测试,即使该语言没有任务标注数据。
- 如果模型学到了跨语言共享表示,就能把英语任务能力迁移过去。
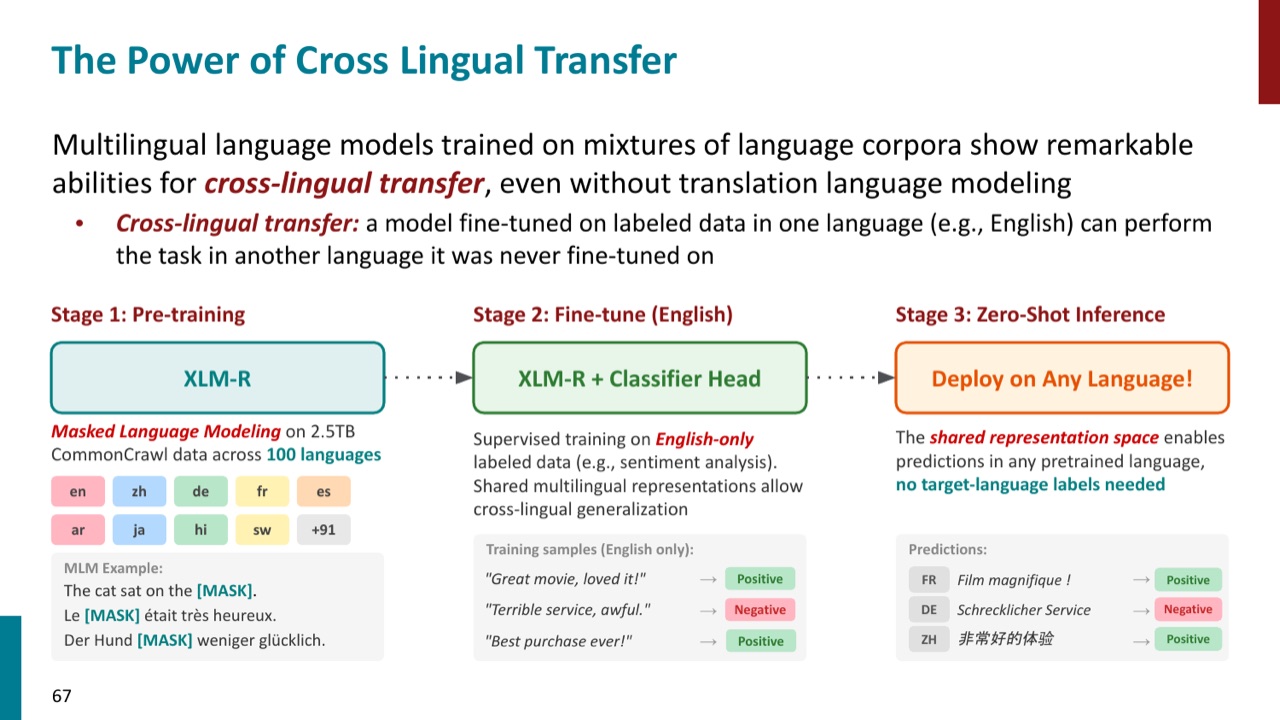
为什么这可能发生?因为多语言模型在预训练中把不同语言放进同一个参数空间。相似概念、相似语义关系、共享文字片段、借词、数字、标点、命名实体,都可能让模型学到跨语言对齐。
16. Vocabulary overlap 为什么有助于迁移
PPT 强调 vocabulary overlap 能促进 cross-lingual transfer。直觉是:如果两种语言共享 token,模型就可以更直接地共享 embedding 和后续表示。
例如不同语言中共享的数字、标点、专名、外来词、词根片段,都能成为迁移桥梁。即使是 false friends,也就是形式相似但语义不同的词,PPT 指出它们有时也能帮助 embedding 对齐,因为共享形式本身会提供连接点。

但 overlap 不是唯一目标。每种语言仍然需要足够的 vocabulary allocation。如果一个 tokenizer 主要为英语分配大量 token,而低资源语言只能被拆得很碎,那么低资源语言的序列会更长、表示更稀疏、训练更困难。
PPT 提到 XLM-V 的方向:用更大的 multilingual vocabulary 提升覆盖。但这也引入效率代价,因为词表更大意味着 embedding 和输出层更大。
所以这里有一个三角关系:
- 更大词表:覆盖更多语言片段,但参数和计算成本更高。
- 更小词表:效率更好,但很多语言被拆得更碎。
- 更高 overlap:有助于迁移,但不能牺牲每种语言的基本覆盖。
17. Curse of multilinguality:语言越多,固定容量越紧
多语言模型不是简单地“加语言就变强”。PPT 用 curse of multilinguality 描述一个现象:在模型容量固定时,加入越来越多语言会带来资源竞争。

PPT 中的 XLM-R 结果显示,语言数量从较少扩展到更多时,XNLI 平均准确率会下降。核心解释是:
- 高资源语言原本训练充分,加入更多语言后会分走容量和训练预算。
- 低资源语言一开始能从多语言共享中受益。
- 但语言继续增加、模型容量不变时,低资源语言也会受到竞争影响。
这不是说多语言模型不好,而是说多语言模型需要容量、数据采样、tokenizer、训练策略一起配合。否则同一个模型要同时容纳太多语言,就会出现互相挤压。
18. Tokenization unfairness:分词从入口制造不公平
PPT 最重要的观点之一是:多语言不公平不是等模型训练完才出现,它从 tokenizer 就开始了。
PPT 用 ChatGPT tokenizer 展示不同语言表达类似内容时的 token 数差异:英语、法语、索马里语、泰语会被切成不同数量的 tokens。相同语义如果在某种语言中需要更多 token,就会有直接后果:
- 用户需要支付更多 token 成本。
- 同样上下文窗口里能放的内容更少。
- 模型训练和推理时要处理更长序列。
- 表示被切得更碎,下游任务可能更难。

PPT 用 subword fertility 衡量这种现象。可以把它理解为平均每个词被拆成多少个 subword token:
fertility 越高,说明一个词平均要用更多 subword 表示。PPT 指出 fertility 和下游表现存在很强的负相关:被切得越碎的语言,往往表现越差。

这让我们重新看 tokenizer 的设计目标。一个只按总体语料频率优化的 tokenizer,很容易偏向高资源语言。高资源语言有更多片段进入词表,低资源语言则被迫拆得更细。于是模型还没开始训练,输入表示就已经不平等。
19. 为什么重新考虑 character/byte-level model
讲到这里,character/byte tokenization 的缺点仍然存在:序列长,计算贵。但 PPT 的后半部分说明,多语言和鲁棒性给了我们重新考虑它的理由。
CANINE 是一个 character-level multilingual model。由于它覆盖 full Unicode alphabet,PPT 强调它甚至可以处理训练时没有见过的语言。这和 subword tokenizer 很不同:subword 词表如果对某些语言覆盖很差,这些语言会被切得很碎;character-level 至少能直接表示字符。
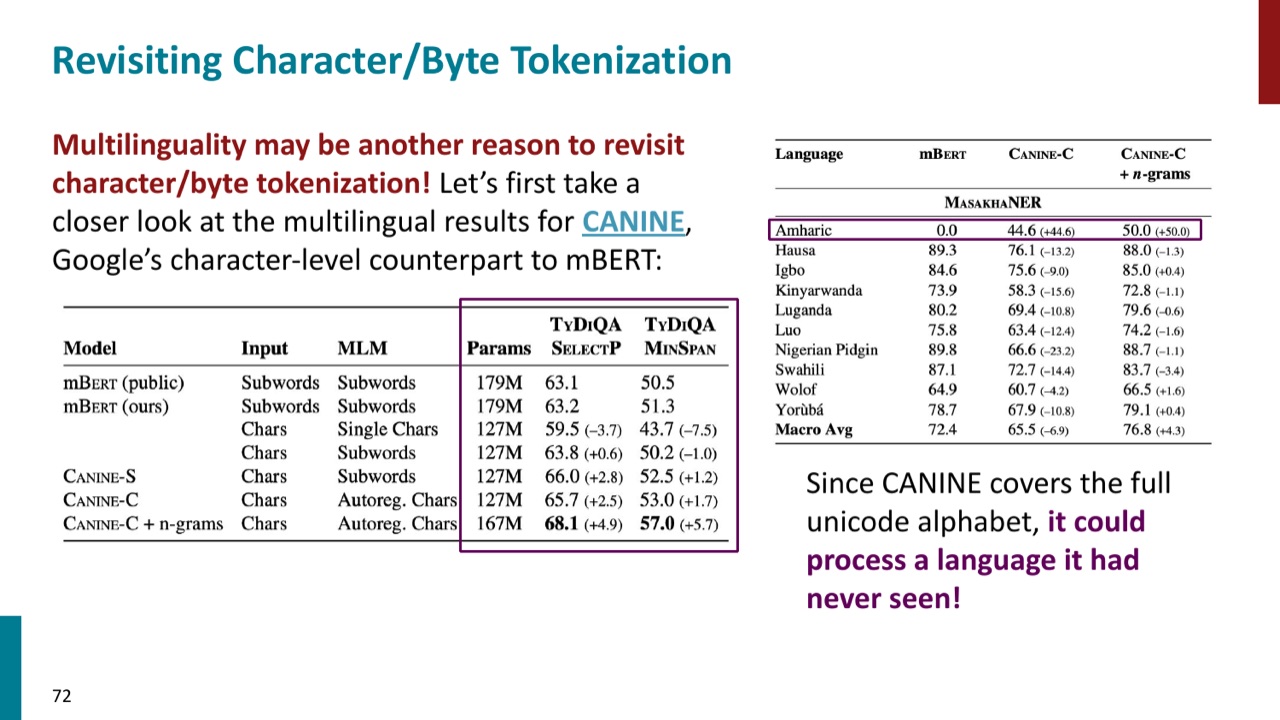
序列长的问题也可以通过架构缓解。PPT 提到 MrT5:它教 ByT5 对大部分处理只使用部分 bytes,通过 learnable delete gate 动态减少序列长度。也就是说,模型先从 byte-level 获得覆盖和鲁棒性,再学习丢掉不必要的位置,提高效率。
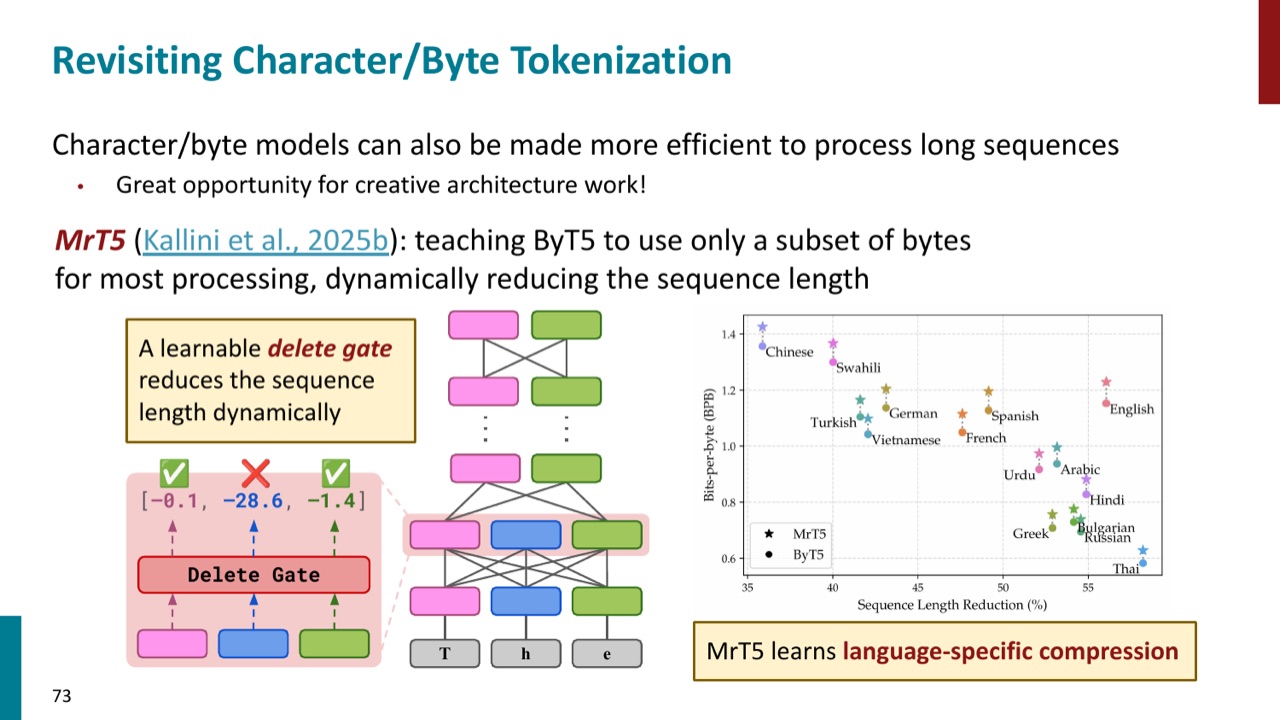
character/byte tokenization 还能缓解 subword tokenization 的一些问题:
- 没有 glitch tokens:每个字符或 byte 都会在训练数据中被覆盖。
- 更强字符级鲁棒性:模型直接看到字符扰动。
- 直接观察词的字符组成:拼写、反转、计数等任务更自然。
但这并不意味着“直接回到字符级”就是唯一答案。PPT 最后提到 latent tokenization:byte/character-level models 可以在架构内部学习真正相关的 meaning units。也就是说,我们也许不需要在预处理阶段固定 token 边界,而可以让模型自己学出合适的中间单位。

20. 本讲总图:tokenizer 是模型的一部分
把这一讲串起来,可以得到一条主线:
- 模型不能直接处理字符串,所以需要 tokenizer。
- tokenization 决定模型的基本输入单位。
- word tokenization 语义直观,但 OOV 和长尾严重。
- character/byte tokenization 覆盖强,但序列长。
- subword tokenization 在效率和覆盖之间折中,因此成为现代 LLM 主流。
- BPE 用数据频率学习 merge rules,常见片段会逐渐变成较大 token。
- subword tokenization 会影响拼写、字符级任务和 typo robustness。
- tokenizer 和 LM 数据错配会产生 glitch tokens。
- 多语言模型依赖共享表示和 cross-lingual transfer。
- vocabulary overlap 有助于迁移,但每种语言也需要足够词表覆盖。
- 固定容量下语言过多会出现 curse of multilinguality。
- tokenization unfairness 会让非英语或低资源语言付出更多 token 成本、获得更差性能。
- character/byte-level 与 latent tokenization 是解决这些问题的重要研究方向。
这一讲最应该带走的一句话是:tokenizer 不是模型外部的清洗脚本,它是语言模型能力、成本和公平性的入口。
关键概念速查
| 概念 | 解释 | 本讲中的作用 |
|---|---|---|
| token | tokenizer 产生的离散单位 | 模型真正看到的输入单位 |
| vocabulary | tokenizer 认识的 token 集合 | 决定 embedding 和输出空间大小 |
| token ID | token 在词表中的整数编号 | 连接文本和向量表示 |
| word tokenization | 把词作为 token | 直观但有 OOV 和长尾问题 |
| character tokenization | 把字符作为 token | 覆盖强但序列长 |
| byte tokenization | 把编码后的 byte 作为 token | 词表固定且无 OOV |
| subword tokenization | 把常见片段作为 token | 现代 LLM 的主流折中 |
| BPE | 高频相邻 pair 迭代合并 | 学习 subword vocabulary |
| SentencePiece | tokenizer library | 支持 BPE 和 Unigram LM 等 |
| glitch token | 词表中存在但 LM 没学好的 token | 来自 tokenizer 与 LM 数据错配 |
| cross-lingual transfer | 一种语言的任务能力迁移到另一种语言 | 多语言模型的重要目标 |
| vocabulary overlap | 不同语言共享 token | 有助于共享 embedding 和迁移 |
| curse of multilinguality | 固定容量下语言数增加带来的性能压力 | 多语言模型的容量竞争问题 |
| subword fertility | 平均每个词对应多少 subword | 衡量 tokenization 不公平 |
| latent tokenization | 模型内部学习意义单位 | 避免预先固定 token 边界的方向 |
复习题
- 为什么语言模型不能直接把原始字符串作为输入?
- token、token ID、vocabulary、embedding matrix 分别处在模型输入流程的哪一步?
- word tokenization 为什么会产生 OOV?
UNK为什么会丢失信息? - character tokenization 和 byte tokenization 的差别是什么?
- subword tokenization 为什么能同时缓解 OOV 和序列长度问题?
- BPE 每次 merge 的依据是什么?为什么 merge 顺序会影响 test-time tokenization?
- 用自己的话解释
_pier为什么会被切成_pi er,而不是_pick。 - SentencePiece 为什么不是一种单独的 tokenization algorithm?
- 为什么
strawberry这类拼写问题会暴露 subword tokenizer 的局限? - glitch token 为什么会出现?它为什么不只是一个趣味现象?
- cross-lingual transfer 依赖哪些共享信号?
- vocabulary overlap 有什么好处?它又为什么不能完全解决低资源语言问题?
- curse of multilinguality 的核心矛盾是什么?
- subword fertility 为什么可以衡量 tokenization unfairness?
- character/byte-level model 在多语言场景中重新受到关注的原因是什么?