05. Attention 与 Transformer
官方 PPT 来源:第 5 讲官方 PPT
本讲对应 CS224n 第 5 讲 Attention and Transformers。它从上一讲 RNN 的两个痛点出发:长距离梯度难传、encoder-decoder 有 bottleneck。然后引入 attention,进一步问:既然 attention 本身就能在序列位置之间传信息,那还需要 RNN 吗?这个问题最终引出 self-attention 和 Transformer。
本讲学习目标
学完这一讲,你应该能从零回答下面这些问题:
- RNN 的 vanishing gradient 为什么会推动我们寻找 attention?
- RNN encoder-decoder 的 bottleneck problem 是什么?
- Attention 为什么可以看成 weighted average 或 soft lookup?
- Seq2seq attention 在 decoder 每一步具体做哪几件事?
- Attention 为什么能改善 NMT、缓解 bottleneck,并提供 soft alignment?
- Cross-attention 和 self-attention 的区别是什么?
- Self-attention 中 query、key、value 分别从哪里来?
- 怎样用 \(q_i^\top k_j\)、softmax 和 value 加权和计算 self-attention?
- Self-attention 为什么没有天然顺序信息?
- Positional representation 为什么要加到 input embeddings 上?
- Sinusoidal position 和 learned absolute position 各有什么利弊?
- 为什么 self-attention block 还需要 feed-forward network?
- Decoder 做语言模型时为什么必须 mask future tokens?
- Transformer decoder block 由哪些组件构成?
- Multi-head attention 相比单头 attention 解决什么问题?
- Sequence-stacked attention 的矩阵形式是什么?
- Scaled dot-product attention 为什么要除以 \(\sqrt{d/h}\)?
- Residual connection 和 layer normalization 分别帮助什么?
- Transformer encoder、decoder、encoder-decoder 的区别是什么?
- Transformer 的 quadratic compute 指什么?
PPT 脉络
| 部分 | PPT 内容 | 本讲义对应章节 |
|---|---|---|
| RNN 问题回顾 | vanishing/exploding gradients、gradient clipping、LSTM/attention/residual 提示 | 1-3 |
| NMT 回顾 | seq2seq、conditional LM、end-to-end training、bottleneck | 4-5 |
| Attention | bottleneck solution、weighted average、lookup、seq2seq attention、soft alignment | 6-10 |
| 从 recurrence 到 attention | attention 的一般定义、是否需要 RNN、cross-attention 到 self-attention | 11-12 |
| Self-attention | Q/K/V、attention scores、softmax、weighted sum | 13-15 |
| Self-attention 作为 building block 的问题 | order、position representations、nonlinearity、masking | 16-20 |
| Transformer | decoder、multi-head、stacked matrix form、scaled dot product、residual、layer norm | 21-28 |
| Transformer 变体与代价 | encoder、encoder-decoder、cross-attention、结果、quadratic cost | 29-33 |
1. 先回到 RNN 的核心失败点
第 4 讲讲过,RNN 理论上可以处理任意长度输入,因为它反复更新 hidden state:
但是训练 RNN 时,梯度要沿时间反向传播。如果从第 \(t\) 步传回第 1 步,中间要经过许多局部导数连乘。
当这些局部因子偏小,远处梯度会越来越小,这就是 vanishing gradient。
PPT 用直觉图表达:
When these are small, the gradient signal gets smaller and smaller as it backpropagates further.
这会导致模型主要根据近处影响更新参数,而很难学到长期依赖。
1.1 RNN-LM 中的长距离依赖例子
PPT 继续用上一讲的例子:
When she tried to print her tickets, she found that the printer was out of toner.
She went to the stationery store to buy more toner.
It was very overpriced.
After installing the toner into the printer, she finally printed her ______
末尾应该预测 tickets。但真正提供关键信息的 tickets 出现在很早之前。
如果远处梯度消失,模型就无法从这个训练样本中学到:
这种依赖。
2. Exploding Gradient 和 Gradient Clipping
PPT 也回顾 exploding gradient。
SGD 更新式是:
如果 \(\nabla_{\theta}J(\theta)\) 太大,更新步子就会太大,参数可能被推到很差的区域,甚至出现:
PPT 给出的实用解决方法是 gradient clipping:
if the norm of the gradient is greater than some threshold, scale it down before applying SGD update.
写成公式:
直觉是:
PPT 说 exploding gradient 比较容易处理;真正难的是 vanishing gradient。
3. Vanishing Gradient 怎么缓解?
PPT 指出,vanishing gradient 的核心问题是:
RNN 很难学会在很多时间步中保存信息。
vanilla RNN 的 hidden state 每一步都被重写。如果信息要穿过很多次重写,它很容易丢失。
PPT 提了两个方向:
- 使用显式 memory,例如 LSTM。
- 在模型中创建更直接、更线性的 pass-through connections,例如 attention、residual connections。
这就是本讲的主线:attention 不只是机器翻译技巧,也是给远处信息和梯度提供 shortcut 的机制。
4. Machine Translation 和 Seq2seq 回顾
Machine translation 的任务是把源语言句子 \(x\) 翻译成目标语言句子 \(y\)。
PPT 例子:
Neural Machine Translation 是 NLP deep learning 的第一个大成功:
- 2014:第一篇 seq2seq paper 发布。
- 2016:Google Translate 从 SMT 切换到 NMT。
- 到 2018 年,NMT 已成为主流。
4.1 Encoder-Decoder
Seq2seq 的一般结构是:
Encoder 读取源句,产生一个 encoding。Decoder 是一个 language model,但它的初始状态由 source encoding 提供。
生成时,decoder 每一步把上一步输出作为下一步输入:
4.2 Conditional Language Model
PPT 说,seq2seq 是 conditional language model。
普通 LM:
NMT:
它是 LM,因为 decoder 预测目标句下一个词;它是 conditional,因为预测还依赖源句 \(x\)。
整句概率:
训练目标是每一步 negative log probability 的平均:
PPT 强调:seq2seq is optimized as a single system,backpropagation end-to-end。
5. Bottleneck Problem:为什么只给一个 encoding 不够?
早期 RNN encoder-decoder 把整个源句压成一个 encoding,然后 decoder 只依赖这个压缩表示生成目标句。
PPT 把这个称为:
问题是:
- 源句越长,需要保存的信息越多。
- 单个 encoding 容量有限。
- decoder 每一步都只能间接依赖这个压缩状态。
- 源句早期位置到目标输出的梯度路径也很长。
这就是 bottleneck problem。
Attention 的出现就是为了解决它:
decoder 每生成一个词,都能直接连接到 encoder 的所有 hidden states。
6. Attention 的核心思想
PPT 进入第 3 部分:
Attention provides a solution to the bottleneck problem.
核心思想:
on each step of the decoder, use direct connection to the encoder to focus on a particular part of the source sequence.
中文说就是:
如果当前目标词对应源句第 1 个词,attention 权重就偏向源句第 1 个 hidden state。
如果当前目标词对应源句第 4 个词,attention 权重就偏向第 4 个 hidden state。
7. Attention 是 Weighted Average,也是 Soft Lookup
PPT 用两个直觉解释 attention。
7.1 Weighted Average
Attention 是加权平均:
其中:
- \(v_j\):第 \(j\) 个 value vector。
- \(\alpha_j\):第 \(j\) 个位置的 attention weight。
- \(\sum_j \alpha_j = 1\)。
如果 \(\alpha_3\) 最大,那么输出主要包含第 3 个 value 的信息。
7.2 Soft Lookup
PPT 把 attention 和 lookup table 类比。
普通 lookup table:
Attention:
它不是硬选一个 value,而是 soft lookup。
这使模型既可以聚焦,也可以混合多个来源的信息。
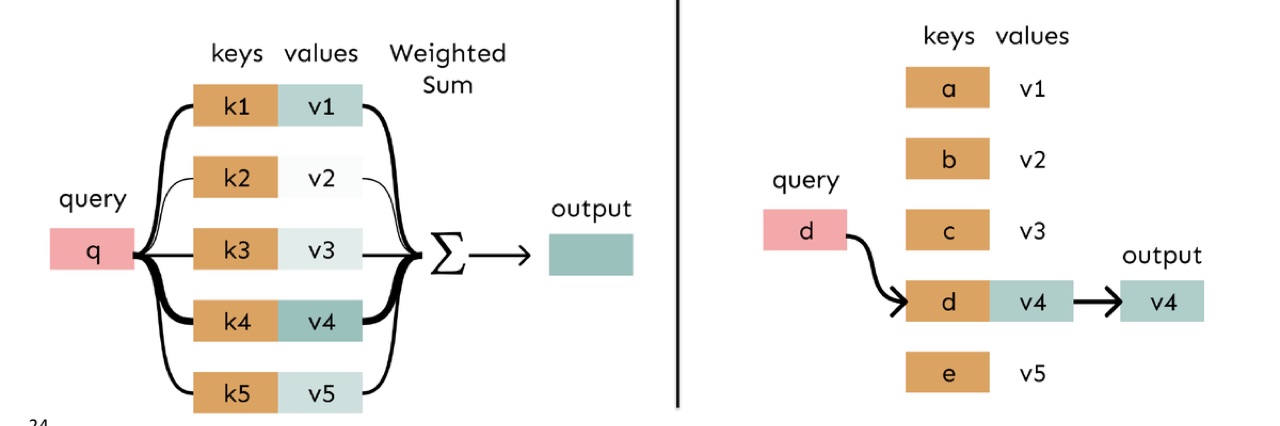
官方 PPT 截图:左边是 attention 的 soft lookup,query 会和所有 keys 匹配,然后对 values 做加权和;右边是普通 lookup,query 只命中一个 key 并返回一个 value。
8. Seq2seq Attention 的具体步骤
以 NMT 为例,encoder 产生一组 hidden states:
decoder 当前 hidden state 记作 \(s_t\)。
每个 decoder step 做下面几步。
8.1 计算 attention scores
PPT 图中使用 dot product。对每个 encoder hidden state:
这表示当前 decoder 状态 \(s_t\) 和源句第 \(j\) 个位置 \(h_j\) 的匹配程度。
8.2 Softmax 得到 attention distribution
把 scores 变成概率分布:
于是:
如果 \(\alpha_{t1}\) 最大,说明当前 step 主要关注源句第 1 个位置。
8.3 对 encoder hidden states 做加权和
Attention output:
PPT 说:
The attention output mostly contains information from the hidden states that received high attention.
8.4 和 decoder hidden state 拼接并预测
PPT 接着说:把 attention output 和 decoder hidden state 拼接,然后像以前一样计算 \(\hat{y}_t\)。
可以写成:
这里 \([s_t; a_t]\) 表示拼接。
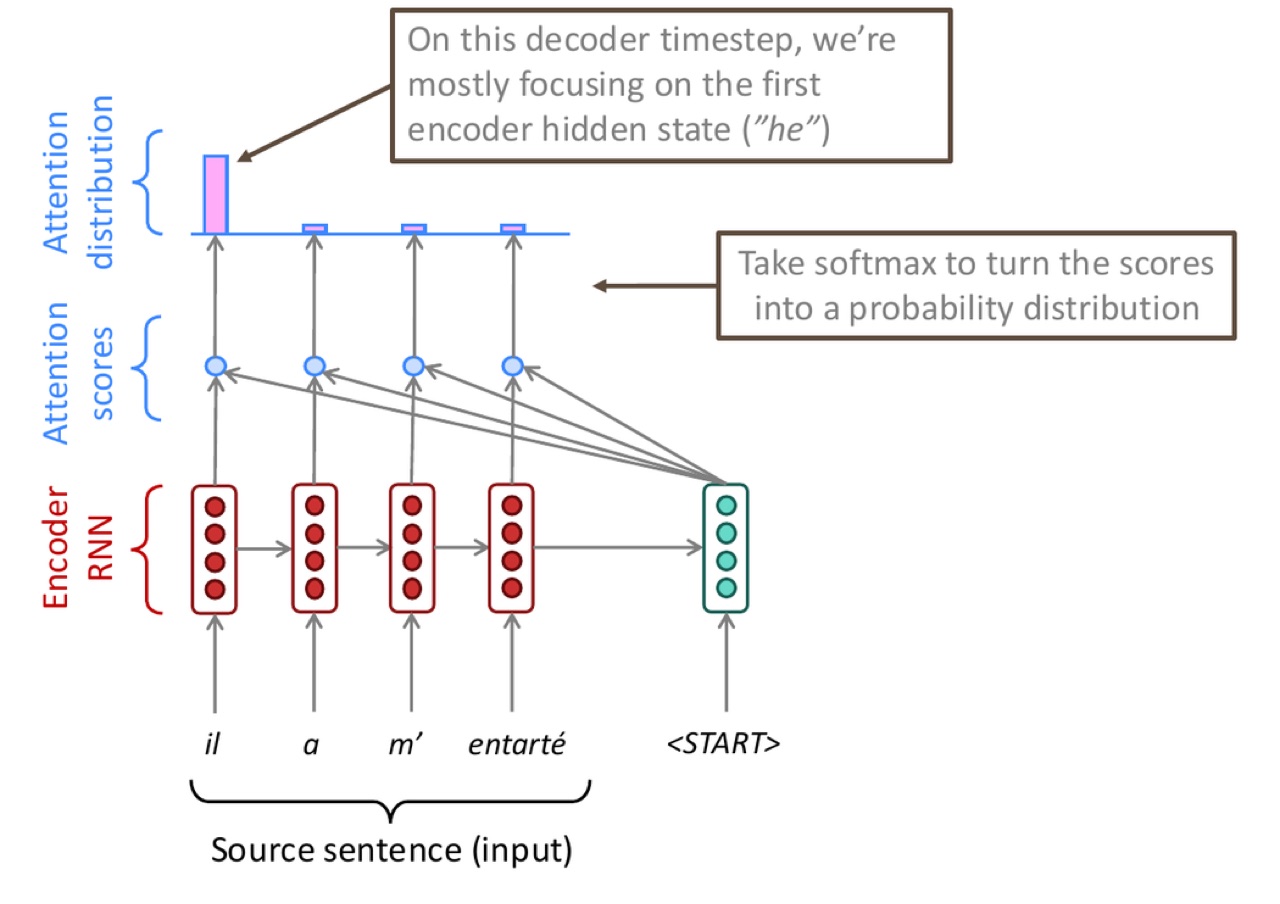
官方 PPT 截图:decoder 当前 hidden state 对所有 encoder hidden states 打分,softmax 后得到 attention distribution。权重越高,attention output 越主要包含该源位置的信息。
8.5 有时还把上一步 attention output 喂给 decoder
PPT 也提到:
Sometimes we take the attention output from the previous step, and also feed it into the decoder.
也就是 decoder 下一步输入除了上一个目标词,还可以包含上一时刻 attention output。
9. Attention 为什么好?
PPT 用 Attention is great! 总结了多个优点。
9.1 改善 NMT 表现
decoder 可以聚焦源句相关部分,翻译效果显著提升。
9.2 更像人类翻译过程
人类翻译时不会把整句全背下来再翻译,而是会边翻译边回看源句。
Attention 让 decoder 也能回看源句。
9.3 解决 bottleneck problem
decoder 不再只依赖单个 source encoding,而是能直接访问 encoder hidden states。
这绕过了 bottleneck。
9.4 缓解 vanishing gradient
Attention 为远处 source states 提供 shortcut。梯度可以通过 attention 连接更直接地传回相关源位置。
9.5 提供一定可解释性
查看 attention distribution,可以看到 decoder 生成当前目标词时关注了源句哪些位置。
PPT 说:
模型自己学出了软对齐关系。
9.6 代价:quadratic cost
PPT 也提醒:
attention has quadratic cost with respect to sequence length.
因为很多 attention 形式需要比较序列位置之间的两两关系。
10. Attention 的一般定义
PPT 从 NMT 推广到一般 deep learning 技术:
Given a set of vector values, and a vector query, attention is a technique to compute a weighted sum of the values, dependent on the query.
中文定义:
我们说:
在 seq2seq attention 中:
- query:decoder hidden state。
- values:encoder hidden states。
- attention output:与当前 decoder step 相关的源句信息。
11. 从 Recurrence 到 Attention-Based Models
PPT 接着问:
Do we even need recurrence at all?
抽象地说,RNN 的作用是把序列信息传给后续神经网络输入。Attention 也是一种传递序列信息的方法。
于是问题变成:
这一步非常关键。它把 attention 从“帮助 RNN encoder-decoder 的工具”变成了“替代 recurrence 的基础构件”。
12. Cross-Attention 和 Self-Attention
PPT 先区分两种 attention。
12.1 Cross-Attention
之前 NMT 中的 attention 是 cross-attention:
query 来自 decoder,keys/values 来自 encoder。
12.2 Self-Attention
要去掉 RNN,我们需要 self-attention:
PPT 对 decoder 语言模型的说法是:
to generate \(y_t\), we need to pay attention to \(y_{<t}\)
也就是当前目标位置要看目标前文,而不再靠 RNN hidden state 一步步传递。
13. Self-Attention 的输入:词向量序列
PPT 设:
是一段词序列,例如:
每个词 \(w_i\) 通过 embedding matrix \(E\) 变成词向量:
其中:
得到输入向量序列:
14. Query、Key、Value
Self-attention 为每个输入向量生成三种向量:
其中:
PPT 分别称它们为:
- \(q_i\):query。
- \(k_i\):key。
- \(v_i\):value。
14.1 为什么要三套向量?
可以用 lookup 类比理解:
- query:当前位置想找什么信息。
- key:每个位置提供一个可匹配的索引。
- value:真正被取出来并混合的信息。
同一个 token 既可以作为“提问者”,也可以作为“被查询的候选位置”,还可以作为“被汇总的信息来源”。
15. Self-Attention 的三步公式
PPT 给出三步。
15.1 计算 pairwise similarities
位置 \(i\) 的 query 和位置 \(j\) 的 key 做点积:
这个分数表示:
15.2 Softmax 归一化
对固定的 \(i\),对所有 \(j\) 做 softmax:
于是:
\(\alpha_{ij}\) 是第 \(i\) 个位置关注第 \(j\) 个位置的权重。
15.3 对 values 做加权和
第 \(i\) 个位置的输出:
这就是 self-attention 的输出向量。
15.4 和 RNN 的区别
RNN 中第 \(i\) 个位置的信息要通过多步 hidden state 传递到第 \(t\) 个位置。
Self-attention 中第 \(t\) 个位置可以直接给第 \(i\) 个位置高权重。
这就是 attention 带来的 shortcut。
16. Self-Attention 作为 Building Block 的第一个问题:没有顺序
PPT 列出 self-attention 的第一个 barrier:
Doesn't have an inherent notion of order.
Self-attention 只看一组向量之间的匹配。如果不额外告诉模型位置,它不知道:
里的 The 是第 1 个词,chef 是第 2 个词,who 是第 3 个词。
对语言来说,顺序极其重要。
解决方案是:
Add position representations to the inputs.
17. Positional Representations
PPT 令每个位置 \(i\) 有一个位置向量:
词向量是:
加入位置信息后的输入是:
PPT 说,在 deep self-attention networks 中,通常在第一层这样做。
17.1 为什么是相加?
因为 \(x_i\) 和 \(p_i\) 维度相同,都是 \(\mathbb{R}^{d}\)。相加后仍然是一个 \(d\) 维向量,可以直接送进后续 Q/K/V 变换。
也可以拼接,但 PPT 说 people mostly just add。
18. Sinusoidal Position Representations
PPT 给出一种方法:用不同周期的正弦和余弦函数构造位置向量。
常见写法可以理解为:
其中:
- \(i\):序列中的位置 index。
- \(j\):向量维度中的频率编号。
PPT 强调它是:
18.1 Pros
PPT 给出的优点:
- 周期性说明 absolute position 也许不是最重要的。
- 也许能 extrapolate 到更长序列,因为周期会重复。
18.2 Cons
PPT 给出的缺点:
- Not learnable。
- Extrapolation does not really work。
19. Learned Absolute Position Representations
另一种方法是让每个位置向量都是可学习参数。
PPT 写:
每个 \(p_i\) 是矩阵 \(p\) 的一列。
19.1 Pros
PPT 给出的优点:
- flexibility。
- 每个位置向量都可以学习以适应数据。
19.2 Cons
缺点:
- 不能 extrapolate 到训练时没有的位置 index,例如超过 \(1,\ldots,n\) 的长度。
PPT 说 most systems use this。
19.3 更灵活的位置表示
PPT 还提到:
- relative linear position attention。
- dependency syntax-based position。
这些都围绕一个问题:简单 absolute indices 是否是最好的位置表达?
20. 第二个问题:Self-Attention 本身缺少非线性
PPT 的第二个 barrier:
No nonlinearities for deep learning. It is all just weighted averages.
Self-attention 输出是 values 的加权平均。如果不断堆叠纯 self-attention,直觉上只是反复重新平均 value vectors。
PPT 给出的简单修复:
add a feed-forward network to post-process each output vector.
对每个位置的 attention output \(o_i\),使用同一个 feed-forward network:
PPT 给出形式:
这个 FF network 逐位置处理 attention 的结果,引入非线性。
20.1 为什么每个位置用同一个 FFN?
这保持了和 self-attention 类似的共享机制:每个 token position 都用同一套参数处理。
不同位置的信息交互由 attention 完成;逐位置非线性变换由 FFN 完成。
21. 第三个问题:Decoder 不能看未来
如果用 self-attention 做 language model 或 decoder,预测第 \(i\) 个位置时,不能看到第 \(i+1\) 个以及更后面的词。
PPT 的 barrier:
Need to ensure we do not look at the future when predicting a sequence.
21.1 低效做法
每个时间步只把过去 token 放进 keys/queries。
但这样会破坏并行化,效率低。
21.2 Masking future
PPT 的做法:
mask out attention to future words by setting attention scores to \(-\infty\).
公式:
softmax 后,未来位置的权重变成 0:
这样既可以并行计算整段序列,又不会让当前位置偷看未来答案。
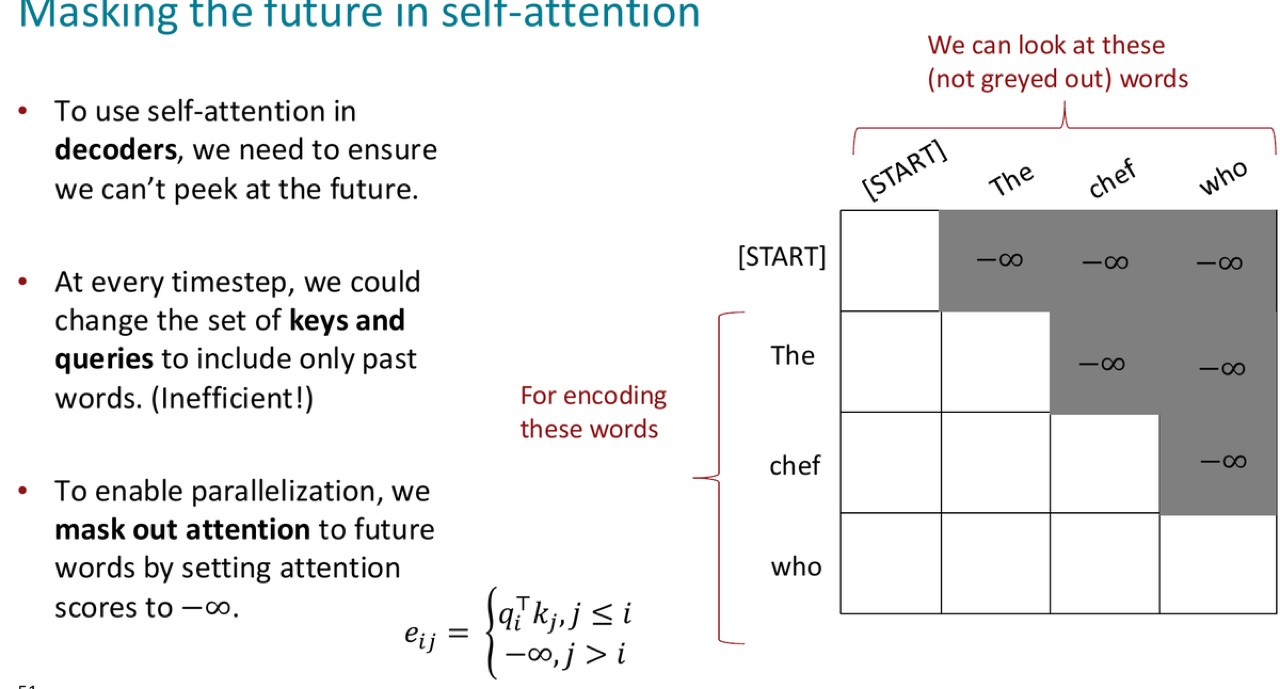
官方 PPT 截图:灰色区域是被 mask 的未来位置,分数被设为 \(-\infty\),softmax 后这些位置的 attention weight 为 0。
22. Self-Attention Building Block 需要的四个东西
PPT 总结了 self-attention building block 的必要组件。
22.1 Self-attention
这是方法基础,用来在序列位置之间传递信息。
22.2 Position representations
因为 self-attention 本身是 unordered function,需要显式加入顺序。
22.3 Nonlinearities
通常在 self-attention 输出后接 feed-forward network。
22.4 Masking
为了在 decoder / language modeling 中并行计算,同时不泄露未来信息。
这四件事组合起来,就能构成 Transformer decoder 的基础。
23. Transformer Decoder:语言模型的骨架
PPT 说:
A Transformer decoder is how we build systems like language models.
它很像前面最小 self-attention 架构,但多了几个组件。
最底部:
然后通过多个 decoder blocks。每个 block 包含:
其中 masked 是为了不能看未来。
24. Sequence-Stacked Attention 的矩阵形式
PPT 把 attention 写成矩阵形式,方便理解并行计算。
令:
这是把 \(n\) 个输入向量按行堆起来。
线性投影:
24.1 所有 query-key 点积
所有 pairwise scores 可以一次矩阵乘法得到:
这个矩阵的第 \(i,j\) 项就是第 \(i\) 个 query 和第 \(j\) 个 key 的匹配分数。
24.2 Softmax 后乘 values
输出:
形状:
这说明 self-attention 可以高度并行:所有位置之间的 pairwise scores 一次算出。
25. Multi-Head Attention
PPT 问:
What if we want to look in multiple places in the sentence at once?
单头 self-attention 对词 \(i\) 会关注 \(x_i^\top Q^\top Kx_j\) 高的位置。但一个词可能因为不同原因需要关注不同位置。
例如:
- 一个关系是句法主谓。
- 一个关系是指代。
- 一个关系是局部搭配。
Multi-head attention 让模型同时拥有多个 attention heads。
25.1 每个 head 有自己的 Q/K/V
令 head 数为 \(h\),第 \(\ell\) 个 head 的参数:
\(\ell\) 从 1 到 \(h\)。
每个 head 独立计算:
其中:
25.2 合并 heads
把所有 head 的输出拼接:
再乘一个输出矩阵:
得到最终 multi-head output。
PPT 的直觉:
Each head gets to look at different things, and construct value vectors differently.
25.3 为什么计算上仍然高效?
PPT 说,即使有 \(h\) 个 heads,也不是真的贵 \(h\) 倍。
因为实现时先算:
再 reshape 成:
head 轴可以像 batch 轴一样并行处理。
26. Scaled Dot-Product Attention
PPT 说:
Scaled Dot Product attention aids in training.
当维度 \(d\) 变大时,向量点积往往变大。softmax 的输入太大时,softmax 会很尖锐,梯度可能变小。
因此 Transformer 不直接使用:
而是把 attention scores 除以 \(\sqrt{d/h}\):
这里 \(d/h\) 是每个 head 的维度。
26.1 直觉
缩放不是为了改变 attention 的含义,而是为了控制分数尺度:

官方 PPT 截图:scaled dot-product attention 的唯一变化是把 attention scores 除以每个 head 维度的平方根,从而让训练更稳定。
27. Residual Connections
PPT 说,Transformer 还需要两个训练技巧:
- residual connections。
- layer normalization。
Residual connection 的普通层写法是:
加 residual 后:
也就是只让 layer 学 residual:
27.1 为什么有用?
PPT 给出两个直觉:
- Gradient is great through the residual connection; it is 1。
- Bias towards the identity function。
如果某层暂时学不到有用变换,residual 允许它接近恒等映射,至少不破坏信息流。
28. Layer Normalization
PPT 说 layer normalization 是帮助模型更快训练的技巧。
核心想法:
cut down on uninformative variation in hidden vector values by normalizing to unit mean and standard deviation within each layer.
对模型中的一个词向量:
均值:
PPT 将方差项写作:
再引入可学习参数:
Layer normalization 计算:
其中 \(\otimes\) 表示逐元素乘法。
28.1 它在 Transformer 图里叫什么?
PPT 说,在多数 Transformer 图中,residual connection 和 layer normalization 常写成:
也就是先做残差相加,再做归一化。
29. Transformer Decoder Block
PPT 总结 Transformer decoder:
The Transformer Decoder is a stack of Transformer Decoder Blocks.
每个 block 包含:
- Self-attention。
- Add & Norm。
- Feed-Forward。
- Add & Norm。
对 language model / decoder 来说,self-attention 是 masked multi-head self-attention。
所以 decoder block 可以理解为:
多个 blocks 堆叠后,模型就可以逐层构造复杂上下文表示。
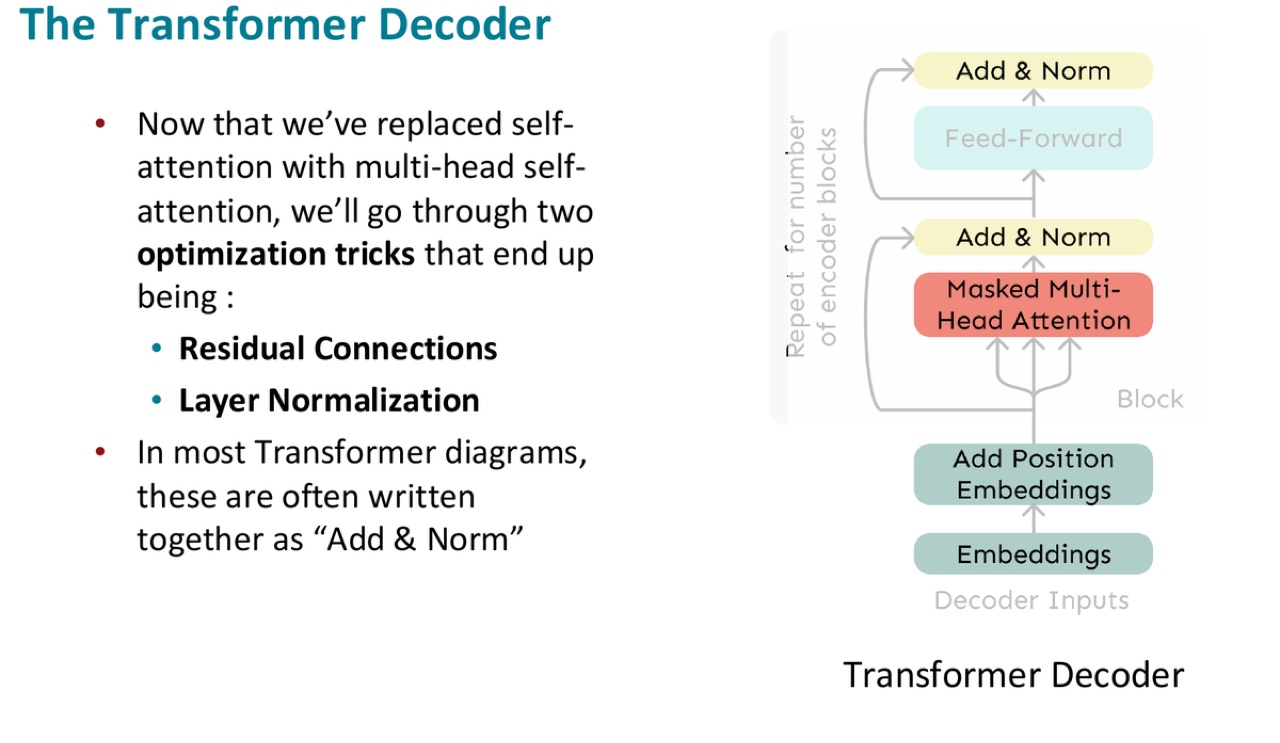
官方 PPT 截图:Transformer decoder 由 embeddings、position embeddings、masked multi-head attention、feed-forward、residual connections 和 layer normalization 组成,并将 decoder block 重复堆叠。
30. Transformer Encoder
PPT 问:
What if we want bidirectional context, like in a bidirectional RNN?
这就是 Transformer encoder。
它和 decoder 的核心区别:
Encoder 可以看完整输入序列,所以不需要防止看到未来。
例如做源句编码时,每个 source token 可以关注源句中任何位置。
30.1 Encoder 与 Decoder 对比
| 模块 | 是否 mask future | 典型用途 |
|---|---|---|
| Transformer Decoder | 是 | language model、自回归生成 |
| Transformer Encoder | 否 | 双向编码输入序列 |
31. Transformer Encoder-Decoder
对 machine translation 这类 seq2seq 任务,PPT 说常用 Transformer encoder-decoder。
结构:
- 使用普通 Transformer encoder 处理源句。
- 使用 Transformer decoder 生成目标句。
- decoder 被修改为对 encoder output 做 cross-attention。
31.1 Cross-Attention 的 Q/K/V 来源
PPT 明确区分 self-attention 和 cross-attention。
Self-attention:
Cross-attention 中:
- encoder 输出:
- decoder 当前表示:
keys 和 values 来自 encoder:
queries 来自 decoder:
直觉:
这正是早期 RNN attention 思想在 Transformer 中的版本。
32. Transformer 的效果
PPT 在第 6 部分展示了 Transformer 的好结果。
32.1 Machine Translation
原始 Transformer paper 在机器翻译上不仅 BLEU scores 更好,也更高效地训练。
32.2 Document Generation
PPT 还展示 document generation 场景,强调从旧标准走向:
这说明 Transformer 不只是翻译模型,而逐渐变成更通用的序列建模架构。
33. Transformer 的问题和开放方向
PPT 最后问:
What would we like to fix about the Transformer?
33.1 Self-attention 的 quadratic compute
Self-attention 要计算所有 token pair 的交互。
如果序列长度是 \(n\),attention score matrix 是:
所以计算随序列长度二次增长:
如果:
例如处理长文档,代价会非常大。
33.2 Position representations
PPT 也问:
Are simple absolute indices the best we can do to represent position?
并再次提到:
- relative linear position attention。
- dependency syntax-based position。
33.3 是否真的需要移除 quadratic cost?
PPT 最后一页提出一个更微妙的问题:
随着 Transformer 变大,越来越多计算其实在 self-attention 之外。实践中,大型 Transformer language models 几乎仍然使用这里介绍的 quadratic cost attention,因为便宜替代方法在 scale 上往往不如它。
问题变成:
这不是本讲解决的问题,但它解释了后续许多长上下文研究的动机。
34. 初学者最容易混的点
34.1 Attention 不是“解释模型”的同义词
Attention weights 可以提供 soft alignment,让我们看到模型生成某个词时关注哪里。但 PPT 只说它提供 some interpretability,不等于完整解释模型所有决策。
34.2 Attention output 不是选中的一个 token
它是 values 的加权平均:
即使一个位置权重最大,输出也通常混合了多个位置的信息。
34.3 Self-attention 不自动知道顺序
如果不加 positional representations,模型只看到一组 token 向量之间的关系,不知道谁在前谁在后。
34.4 Masking 是 decoder 的约束,不是 encoder 的约束
语言模型 decoder 不能看未来,所以要 causal mask。
Encoder 编码完整输入,没有这个限制。
34.5 Multi-head 不是简单重复同一个 attention
每个 head 有自己的 Q/K/V 投影,可以关注不同关系,并构造不同 value 表示。
34.6 Transformer 的核心不是“没有 RNN”这么简单
Transformer decoder 至少需要:
- masked multi-head self-attention。
- positional representations。
- feed-forward network。
- residual connections。
- layer normalization。
这些组件组合起来才是可训练的深层架构。
35. 板书级总结
35.1 Seq2seq attention score
35.2 Attention distribution
35.3 Attention output
35.4 Self-attention Q/K/V
35.5 Self-attention scores
35.6 Self-attention weights
35.7 Self-attention output
35.8 Positional input
35.9 Causal mask
35.10 Matrix self-attention
35.11 Scaled dot-product attention
35.12 Residual connection
35.13 Layer normalization
35.14 Cross-attention
35.15 Quadratic cost
36. 自学路线
第一步:先理解 attention 为什么出现
不要先背 Q/K/V。先记住:
第二步:把 attention 当成 soft lookup
掌握这句话:
这就是所有 attention 公式的共同骨架。
第三步:区分 cross-attention 和 self-attention
Cross-attention:
Self-attention:
第四步:理解 self-attention 三个缺陷
它自己缺:
- 顺序。
- 非线性。
- decoder 中的未来遮蔽。
对应解决:
- positional representations。
- feed-forward network。
- causal mask。
第五步:再看 Transformer decoder block
把 block 背成:
第六步:理解 encoder 和 encoder-decoder
Encoder 去掉 mask。
Encoder-decoder 在 decoder 中增加 cross-attention,让目标生成依赖源句表示。
第七步:最后记住代价
Transformer 的强大来自全连接式 token interaction,但这也带来:
的 self-attention 计算代价。
37. 自测题
- Attention 解决 RNN encoder-decoder 的哪个核心问题?
- 为什么 attention 可以看成 weighted average?
- 为什么 attention 又可以看成 soft lookup?
- Seq2seq attention 中,decoder hidden state 和 encoder hidden states 分别扮演什么角色?
- Attention 为什么能缓解 vanishing gradient?
- Cross-attention 和 self-attention 的 Q/K/V 来源有什么不同?
- Self-attention 中 \(e_{ij}=q_i^\top k_j\) 表示什么?
- 为什么 softmax 后的 \(\alpha_{ij}\) 可以当作权重?
- Self-attention 为什么必须加入 positional representations?
- Sinusoidal position 和 learned absolute position 的优缺点分别是什么?
- 为什么 self-attention 后面要加 feed-forward network?
- Decoder 中为什么要把未来位置 score 设置成 \(-\infty\)?
- Multi-head attention 为什么比单头更灵活?
- Scaled dot-product attention 为什么要除以 \(\sqrt{d/h}\)?
- Residual connection 的公式是什么,它帮助什么?
- Layer normalization 在做什么?
- Transformer encoder 和 decoder 的主要区别是什么?
- Transformer encoder-decoder 中 cross-attention 的 keys/values 和 queries 分别来自哪里?
- Transformer 的 quadratic compute 来自哪里?
38. 自测题参考答案
- 解决 source sentence 被压缩进单一 encoding 的 bottleneck problem。
- 因为 attention output 是 \(\sum_j \alpha_j v_j\),即对 value vectors 按权重求和。
- 因为 query 和所有 keys 做软匹配,不是硬选择一个 key,而是用 softmax 权重混合对应 values。
- Decoder hidden state 是 query;encoder hidden states 是被关注的 source-side representations,可作为 keys/values。
- 它给 decoder 到远处 encoder states 提供直接连接,缩短梯度路径。
- Cross-attention 的 query 来自 decoder,keys/values 来自 encoder;self-attention 的 Q/K/V 都来自同一序列。
- 表示第 \(i\) 个位置的 query 和第 \(j\) 个位置的 key 的匹配分数。
- softmax 输出非负且对所有 \(j\) 求和为 1,所以可以作为加权平均的权重。
- 因为 self-attention 本身没有内置顺序概念,不知道 token 的序列位置。
- Sinusoidal position 不可学习,也不一定真能外推,但有周期结构;learned absolute position 灵活、可拟合数据,但不能外推到没训练过的位置。
- 因为 self-attention 本身主要是 weighted averages,缺少逐元素非线性;FFN 提供非线性和逐位置变换。
- 为了防止当前位置在语言模型训练中看到未来 token,避免信息泄漏。
- 每个 head 有独立 Q/K/V,可以关注不同位置关系并构造不同 value 表示。
- 维度大时点积分数会变大,使 softmax 过尖、梯度变差;除以 \(\sqrt{d/h}\) 控制分数尺度。
- \(X^{(i)}=X^{(i-1)}+\text{Layer}(X^{(i-1)})\)。它让梯度更容易通过,也让层默认接近恒等映射。
- 它在每层内对 hidden vector 做均值和尺度归一化,再用 learned gain/bias 调整,帮助训练更快更稳定。
- Decoder 有 causal mask,只看过去;encoder 去掉 mask,可以看完整输入。
- Keys/values 来自 encoder outputs \(h_i\),queries 来自 decoder representations \(z_i\)。
- self-attention 要计算所有 token pair 的 \(n \times n\) score matrix,所以随序列长度 \(n\) 呈 \(O(n^2)\) 增长。